添加pm,git和依赖
This commit is contained in:
parent
615163a7f6
commit
940fb66fe9
|
|
@ -18,6 +18,13 @@
|
||||||
"program": "src/hook.pyw",
|
"program": "src/hook.pyw",
|
||||||
"console": "integratedTerminal"
|
"console": "integratedTerminal"
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"name": "Python 调试程序: 当前文件",
|
||||||
|
"type": "debugpy",
|
||||||
|
"request": "launch",
|
||||||
|
"program": "${file}",
|
||||||
|
"console": "integratedTerminal"
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"command": "make debug",
|
"command": "make debug",
|
||||||
"name": "打包并在虚拟机中运行",
|
"name": "打包并在虚拟机中运行",
|
||||||
|
|
|
||||||
Binary file not shown.
|
|
@ -1 +0,0 @@
|
||||||
echo helloworld
|
|
||||||
|
|
@ -1 +0,0 @@
|
||||||
nihaoshijie
|
|
||||||
|
|
@ -1,55 +0,0 @@
|
||||||
{
|
|
||||||
"version": "0.0.1",
|
|
||||||
"name": "cli-tools",
|
|
||||||
"author": "cxykevin",
|
|
||||||
"introduce": "PEinjector/命令行工具",
|
|
||||||
"compatibility": {
|
|
||||||
"injector": {
|
|
||||||
"min": "0.0.1",
|
|
||||||
"max": "0.0.1"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"load": {
|
|
||||||
"symlink": true,
|
|
||||||
"mode": {
|
|
||||||
"onboot": [
|
|
||||||
{
|
|
||||||
"type": "copy",
|
|
||||||
"from": "cli",
|
|
||||||
"to": "X:/Windows/system32"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"onload": [
|
|
||||||
{
|
|
||||||
"type": "start",
|
|
||||||
"command": "cmd"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"start": {
|
|
||||||
"icon": {
|
|
||||||
"name": "CMD",
|
|
||||||
"command": "cmd",
|
|
||||||
"icon": "X:/Windows/system32/cmd.exe"
|
|
||||||
},
|
|
||||||
"path": [
|
|
||||||
"X:/Windows/system32/cli"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
"reg": [
|
|
||||||
"1.reg"
|
|
||||||
],
|
|
||||||
"keywords": [
|
|
||||||
"cli",
|
|
||||||
"PEinjector"
|
|
||||||
],
|
|
||||||
"dependence": [],
|
|
||||||
"datas": [
|
|
||||||
{
|
|
||||||
"type": "dir",
|
|
||||||
"from": "cli/test.txt",
|
|
||||||
"to": "data1"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
{
|
||||||
|
"version": "0.0.1",
|
||||||
|
"name": "git",
|
||||||
|
"author": "cxykevin,undefined",
|
||||||
|
"introduce": "Git 版本管理工具",
|
||||||
|
"keywords": [
|
||||||
|
"git",
|
||||||
|
"develop",
|
||||||
|
"PEinjector"
|
||||||
|
],
|
||||||
|
"dependence": [],
|
||||||
|
"start": {
|
||||||
|
"path": [
|
||||||
|
"Git/bin"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1,31 @@
|
||||||
|
{
|
||||||
|
"version": "0.0.1",
|
||||||
|
"name": "pmapi",
|
||||||
|
"author": "PEinjector",
|
||||||
|
"introduce": "PEinjector/包管理api",
|
||||||
|
"compatibility": {
|
||||||
|
"injector": {
|
||||||
|
"min": "0.0.1"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"load": {
|
||||||
|
"symlink": true,
|
||||||
|
"mode": {
|
||||||
|
"onload": [
|
||||||
|
{
|
||||||
|
"type": "copy",
|
||||||
|
"from": "pm_api",
|
||||||
|
"to": "X:/PEinjector/pmapi"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"keywords": [
|
||||||
|
"pm",
|
||||||
|
"pmapi",
|
||||||
|
"PEinjector"
|
||||||
|
],
|
||||||
|
"dependence": [
|
||||||
|
"git"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
import load_packages # 自动运行
|
||||||
|
import log
|
||||||
|
load_packages.do_nothing()
|
||||||
|
log.info("--- log start ---")
|
||||||
|
|
@ -0,0 +1,3 @@
|
||||||
|
LOGLEVEL = "debug"
|
||||||
|
OUTPUT_COLORFUL = True
|
||||||
|
OUTPUT_STD = True
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
import requests
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
import sys
|
||||||
|
import os
|
||||||
|
|
||||||
|
|
||||||
|
def load_path(): # 加载第三方包到导入目录
|
||||||
|
sys.path.append(os.path.dirname(__file__)+os.sep+"tool")
|
||||||
|
|
||||||
|
|
||||||
|
def do_nothing(): # 过检测
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
load_path()
|
||||||
|
|
@ -0,0 +1,55 @@
|
||||||
|
# ------ cxykevin log moudle ------
|
||||||
|
# This moudle is not a part of this project.
|
||||||
|
# This file is CopyNone.
|
||||||
|
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import config
|
||||||
|
import sys
|
||||||
|
import os
|
||||||
|
levels = {
|
||||||
|
"debug": logging.DEBUG,
|
||||||
|
'info': logging.INFO,
|
||||||
|
'warning': logging.WARN,
|
||||||
|
'err': logging.ERROR
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
logging.basicConfig(filename=os.path.dirname(__file__)+os.sep+"log.log",
|
||||||
|
format='[%(asctime)s][%(levelname)s] %(message)s',
|
||||||
|
level=levels[config.LOGLEVEL], filemode="a")
|
||||||
|
|
||||||
|
|
||||||
|
def info(msg: str) -> None:
|
||||||
|
if (20 >= levels[config.LOGLEVEL] and config.OUTPUT_STD):
|
||||||
|
sys.stdout.write(
|
||||||
|
("[\033[34mINFO\033[0m]" if config.OUTPUT_COLORFUL else "[INFO]") + msg + "\n")
|
||||||
|
logging.info(msg)
|
||||||
|
|
||||||
|
|
||||||
|
def warn(msg: str) -> None:
|
||||||
|
if (30 >= levels[config.LOGLEVEL] and config.OUTPUT_STD):
|
||||||
|
sys.stdout.write(
|
||||||
|
("[\033[33mWARNING\033[0m]" if config.OUTPUT_COLORFUL else "[WARNING]") + msg + "\n")
|
||||||
|
logging.warn(msg)
|
||||||
|
|
||||||
|
|
||||||
|
def err(msg: str) -> None:
|
||||||
|
if (40 >= levels[config.LOGLEVEL] and config.OUTPUT_STD):
|
||||||
|
sys.stdout.write(
|
||||||
|
("[\033[31mERROR\033[0m]" if config.OUTPUT_COLORFUL else "[ERROR]") + msg + "\n")
|
||||||
|
logging.error(msg)
|
||||||
|
|
||||||
|
|
||||||
|
def break_err(msg: str) -> None:
|
||||||
|
if (40 >= levels[config.LOGLEVEL] and config.OUTPUT_STD):
|
||||||
|
sys.stdout.write(logging
|
||||||
|
("[\033[31mERROR\033[0m]" if config.OUTPUT_COLORFUL else "[ERROR]") + msg + "\n")
|
||||||
|
logging.error(msg)
|
||||||
|
|
||||||
|
|
||||||
|
def print(*args, end="\n") -> None:
|
||||||
|
msg = ' '.join(map(str, args))
|
||||||
|
if (10 >= levels[config.LOGLEVEL]):
|
||||||
|
sys.stdout.write(msg + end)
|
||||||
|
logging.debug(msg)
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
pip
|
||||||
|
|
@ -0,0 +1,20 @@
|
||||||
|
This package contains a modified version of ca-bundle.crt:
|
||||||
|
|
||||||
|
ca-bundle.crt -- Bundle of CA Root Certificates
|
||||||
|
|
||||||
|
This is a bundle of X.509 certificates of public Certificate Authorities
|
||||||
|
(CA). These were automatically extracted from Mozilla's root certificates
|
||||||
|
file (certdata.txt). This file can be found in the mozilla source tree:
|
||||||
|
https://hg.mozilla.org/mozilla-central/file/tip/security/nss/lib/ckfw/builtins/certdata.txt
|
||||||
|
It contains the certificates in PEM format and therefore
|
||||||
|
can be directly used with curl / libcurl / php_curl, or with
|
||||||
|
an Apache+mod_ssl webserver for SSL client authentication.
|
||||||
|
Just configure this file as the SSLCACertificateFile.#
|
||||||
|
|
||||||
|
***** BEGIN LICENSE BLOCK *****
|
||||||
|
This Source Code Form is subject to the terms of the Mozilla Public License,
|
||||||
|
v. 2.0. If a copy of the MPL was not distributed with this file, You can obtain
|
||||||
|
one at http://mozilla.org/MPL/2.0/.
|
||||||
|
|
||||||
|
***** END LICENSE BLOCK *****
|
||||||
|
@(#) $RCSfile: certdata.txt,v $ $Revision: 1.80 $ $Date: 2011/11/03 15:11:58 $
|
||||||
|
|
@ -0,0 +1,66 @@
|
||||||
|
Metadata-Version: 2.1
|
||||||
|
Name: certifi
|
||||||
|
Version: 2024.2.2
|
||||||
|
Summary: Python package for providing Mozilla's CA Bundle.
|
||||||
|
Home-page: https://github.com/certifi/python-certifi
|
||||||
|
Author: Kenneth Reitz
|
||||||
|
Author-email: me@kennethreitz.com
|
||||||
|
License: MPL-2.0
|
||||||
|
Project-URL: Source, https://github.com/certifi/python-certifi
|
||||||
|
Classifier: Development Status :: 5 - Production/Stable
|
||||||
|
Classifier: Intended Audience :: Developers
|
||||||
|
Classifier: License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)
|
||||||
|
Classifier: Natural Language :: English
|
||||||
|
Classifier: Programming Language :: Python
|
||||||
|
Classifier: Programming Language :: Python :: 3
|
||||||
|
Classifier: Programming Language :: Python :: 3 :: Only
|
||||||
|
Classifier: Programming Language :: Python :: 3.6
|
||||||
|
Classifier: Programming Language :: Python :: 3.7
|
||||||
|
Classifier: Programming Language :: Python :: 3.8
|
||||||
|
Classifier: Programming Language :: Python :: 3.9
|
||||||
|
Classifier: Programming Language :: Python :: 3.10
|
||||||
|
Classifier: Programming Language :: Python :: 3.11
|
||||||
|
Requires-Python: >=3.6
|
||||||
|
License-File: LICENSE
|
||||||
|
|
||||||
|
Certifi: Python SSL Certificates
|
||||||
|
================================
|
||||||
|
|
||||||
|
Certifi provides Mozilla's carefully curated collection of Root Certificates for
|
||||||
|
validating the trustworthiness of SSL certificates while verifying the identity
|
||||||
|
of TLS hosts. It has been extracted from the `Requests`_ project.
|
||||||
|
|
||||||
|
Installation
|
||||||
|
------------
|
||||||
|
|
||||||
|
``certifi`` is available on PyPI. Simply install it with ``pip``::
|
||||||
|
|
||||||
|
$ pip install certifi
|
||||||
|
|
||||||
|
Usage
|
||||||
|
-----
|
||||||
|
|
||||||
|
To reference the installed certificate authority (CA) bundle, you can use the
|
||||||
|
built-in function::
|
||||||
|
|
||||||
|
>>> import certifi
|
||||||
|
|
||||||
|
>>> certifi.where()
|
||||||
|
'/usr/local/lib/python3.7/site-packages/certifi/cacert.pem'
|
||||||
|
|
||||||
|
Or from the command line::
|
||||||
|
|
||||||
|
$ python -m certifi
|
||||||
|
/usr/local/lib/python3.7/site-packages/certifi/cacert.pem
|
||||||
|
|
||||||
|
Enjoy!
|
||||||
|
|
||||||
|
.. _`Requests`: https://requests.readthedocs.io/en/master/
|
||||||
|
|
||||||
|
Addition/Removal of Certificates
|
||||||
|
--------------------------------
|
||||||
|
|
||||||
|
Certifi does not support any addition/removal or other modification of the
|
||||||
|
CA trust store content. This project is intended to provide a reliable and
|
||||||
|
highly portable root of trust to python deployments. Look to upstream projects
|
||||||
|
for methods to use alternate trust.
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
certifi-2024.2.2.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
||||||
|
certifi-2024.2.2.dist-info/LICENSE,sha256=6TcW2mucDVpKHfYP5pWzcPBpVgPSH2-D8FPkLPwQyvc,989
|
||||||
|
certifi-2024.2.2.dist-info/METADATA,sha256=1noreLRChpOgeSj0uJT1mehiBl8ngh33Guc7KdvzYYM,2170
|
||||||
|
certifi-2024.2.2.dist-info/RECORD,,
|
||||||
|
certifi-2024.2.2.dist-info/WHEEL,sha256=oiQVh_5PnQM0E3gPdiz09WCNmwiHDMaGer_elqB3coM,92
|
||||||
|
certifi-2024.2.2.dist-info/top_level.txt,sha256=KMu4vUCfsjLrkPbSNdgdekS-pVJzBAJFO__nI8NF6-U,8
|
||||||
|
certifi/__init__.py,sha256=ljtEx-EmmPpTe2SOd5Kzsujm_lUD0fKJVnE9gzce320,94
|
||||||
|
certifi/__main__.py,sha256=xBBoj905TUWBLRGANOcf7oi6e-3dMP4cEoG9OyMs11g,243
|
||||||
|
certifi/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
certifi/__pycache__/__main__.cpython-312.pyc,,
|
||||||
|
certifi/__pycache__/core.cpython-312.pyc,,
|
||||||
|
certifi/cacert.pem,sha256=ejR8qP724p-CtuR4U1WmY1wX-nVeCUD2XxWqj8e9f5I,292541
|
||||||
|
certifi/core.py,sha256=qRDDFyXVJwTB_EmoGppaXU_R9qCZvhl-EzxPMuV3nTA,4426
|
||||||
|
certifi/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
||||||
|
|
@ -0,0 +1,5 @@
|
||||||
|
Wheel-Version: 1.0
|
||||||
|
Generator: bdist_wheel (0.42.0)
|
||||||
|
Root-Is-Purelib: true
|
||||||
|
Tag: py3-none-any
|
||||||
|
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
certifi
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
from .core import contents, where
|
||||||
|
|
||||||
|
__all__ = ["contents", "where"]
|
||||||
|
__version__ = "2024.02.02"
|
||||||
|
|
@ -0,0 +1,12 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
from certifi import contents, where
|
||||||
|
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument("-c", "--contents", action="store_true")
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
if args.contents:
|
||||||
|
print(contents())
|
||||||
|
else:
|
||||||
|
print(where())
|
||||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,114 @@
|
||||||
|
"""
|
||||||
|
certifi.py
|
||||||
|
~~~~~~~~~~
|
||||||
|
|
||||||
|
This module returns the installation location of cacert.pem or its contents.
|
||||||
|
"""
|
||||||
|
import sys
|
||||||
|
import atexit
|
||||||
|
|
||||||
|
def exit_cacert_ctx() -> None:
|
||||||
|
_CACERT_CTX.__exit__(None, None, None) # type: ignore[union-attr]
|
||||||
|
|
||||||
|
|
||||||
|
if sys.version_info >= (3, 11):
|
||||||
|
|
||||||
|
from importlib.resources import as_file, files
|
||||||
|
|
||||||
|
_CACERT_CTX = None
|
||||||
|
_CACERT_PATH = None
|
||||||
|
|
||||||
|
def where() -> str:
|
||||||
|
# This is slightly terrible, but we want to delay extracting the file
|
||||||
|
# in cases where we're inside of a zipimport situation until someone
|
||||||
|
# actually calls where(), but we don't want to re-extract the file
|
||||||
|
# on every call of where(), so we'll do it once then store it in a
|
||||||
|
# global variable.
|
||||||
|
global _CACERT_CTX
|
||||||
|
global _CACERT_PATH
|
||||||
|
if _CACERT_PATH is None:
|
||||||
|
# This is slightly janky, the importlib.resources API wants you to
|
||||||
|
# manage the cleanup of this file, so it doesn't actually return a
|
||||||
|
# path, it returns a context manager that will give you the path
|
||||||
|
# when you enter it and will do any cleanup when you leave it. In
|
||||||
|
# the common case of not needing a temporary file, it will just
|
||||||
|
# return the file system location and the __exit__() is a no-op.
|
||||||
|
#
|
||||||
|
# We also have to hold onto the actual context manager, because
|
||||||
|
# it will do the cleanup whenever it gets garbage collected, so
|
||||||
|
# we will also store that at the global level as well.
|
||||||
|
_CACERT_CTX = as_file(files("certifi").joinpath("cacert.pem"))
|
||||||
|
_CACERT_PATH = str(_CACERT_CTX.__enter__())
|
||||||
|
atexit.register(exit_cacert_ctx)
|
||||||
|
|
||||||
|
return _CACERT_PATH
|
||||||
|
|
||||||
|
def contents() -> str:
|
||||||
|
return files("certifi").joinpath("cacert.pem").read_text(encoding="ascii")
|
||||||
|
|
||||||
|
elif sys.version_info >= (3, 7):
|
||||||
|
|
||||||
|
from importlib.resources import path as get_path, read_text
|
||||||
|
|
||||||
|
_CACERT_CTX = None
|
||||||
|
_CACERT_PATH = None
|
||||||
|
|
||||||
|
def where() -> str:
|
||||||
|
# This is slightly terrible, but we want to delay extracting the
|
||||||
|
# file in cases where we're inside of a zipimport situation until
|
||||||
|
# someone actually calls where(), but we don't want to re-extract
|
||||||
|
# the file on every call of where(), so we'll do it once then store
|
||||||
|
# it in a global variable.
|
||||||
|
global _CACERT_CTX
|
||||||
|
global _CACERT_PATH
|
||||||
|
if _CACERT_PATH is None:
|
||||||
|
# This is slightly janky, the importlib.resources API wants you
|
||||||
|
# to manage the cleanup of this file, so it doesn't actually
|
||||||
|
# return a path, it returns a context manager that will give
|
||||||
|
# you the path when you enter it and will do any cleanup when
|
||||||
|
# you leave it. In the common case of not needing a temporary
|
||||||
|
# file, it will just return the file system location and the
|
||||||
|
# __exit__() is a no-op.
|
||||||
|
#
|
||||||
|
# We also have to hold onto the actual context manager, because
|
||||||
|
# it will do the cleanup whenever it gets garbage collected, so
|
||||||
|
# we will also store that at the global level as well.
|
||||||
|
_CACERT_CTX = get_path("certifi", "cacert.pem")
|
||||||
|
_CACERT_PATH = str(_CACERT_CTX.__enter__())
|
||||||
|
atexit.register(exit_cacert_ctx)
|
||||||
|
|
||||||
|
return _CACERT_PATH
|
||||||
|
|
||||||
|
def contents() -> str:
|
||||||
|
return read_text("certifi", "cacert.pem", encoding="ascii")
|
||||||
|
|
||||||
|
else:
|
||||||
|
import os
|
||||||
|
import types
|
||||||
|
from typing import Union
|
||||||
|
|
||||||
|
Package = Union[types.ModuleType, str]
|
||||||
|
Resource = Union[str, "os.PathLike"]
|
||||||
|
|
||||||
|
# This fallback will work for Python versions prior to 3.7 that lack the
|
||||||
|
# importlib.resources module but relies on the existing `where` function
|
||||||
|
# so won't address issues with environments like PyOxidizer that don't set
|
||||||
|
# __file__ on modules.
|
||||||
|
def read_text(
|
||||||
|
package: Package,
|
||||||
|
resource: Resource,
|
||||||
|
encoding: str = 'utf-8',
|
||||||
|
errors: str = 'strict'
|
||||||
|
) -> str:
|
||||||
|
with open(where(), encoding=encoding) as data:
|
||||||
|
return data.read()
|
||||||
|
|
||||||
|
# If we don't have importlib.resources, then we will just do the old logic
|
||||||
|
# of assuming we're on the filesystem and munge the path directly.
|
||||||
|
def where() -> str:
|
||||||
|
f = os.path.dirname(__file__)
|
||||||
|
|
||||||
|
return os.path.join(f, "cacert.pem")
|
||||||
|
|
||||||
|
def contents() -> str:
|
||||||
|
return read_text("certifi", "cacert.pem", encoding="ascii")
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
pip
|
||||||
|
|
@ -0,0 +1,21 @@
|
||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2019 TAHRI Ahmed R.
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
|
|
@ -0,0 +1,683 @@
|
||||||
|
Metadata-Version: 2.1
|
||||||
|
Name: charset-normalizer
|
||||||
|
Version: 3.3.2
|
||||||
|
Summary: The Real First Universal Charset Detector. Open, modern and actively maintained alternative to Chardet.
|
||||||
|
Home-page: https://github.com/Ousret/charset_normalizer
|
||||||
|
Author: Ahmed TAHRI
|
||||||
|
Author-email: ahmed.tahri@cloudnursery.dev
|
||||||
|
License: MIT
|
||||||
|
Project-URL: Bug Reports, https://github.com/Ousret/charset_normalizer/issues
|
||||||
|
Project-URL: Documentation, https://charset-normalizer.readthedocs.io/en/latest
|
||||||
|
Keywords: encoding,charset,charset-detector,detector,normalization,unicode,chardet,detect
|
||||||
|
Classifier: Development Status :: 5 - Production/Stable
|
||||||
|
Classifier: License :: OSI Approved :: MIT License
|
||||||
|
Classifier: Intended Audience :: Developers
|
||||||
|
Classifier: Topic :: Software Development :: Libraries :: Python Modules
|
||||||
|
Classifier: Operating System :: OS Independent
|
||||||
|
Classifier: Programming Language :: Python
|
||||||
|
Classifier: Programming Language :: Python :: 3
|
||||||
|
Classifier: Programming Language :: Python :: 3.7
|
||||||
|
Classifier: Programming Language :: Python :: 3.8
|
||||||
|
Classifier: Programming Language :: Python :: 3.9
|
||||||
|
Classifier: Programming Language :: Python :: 3.10
|
||||||
|
Classifier: Programming Language :: Python :: 3.11
|
||||||
|
Classifier: Programming Language :: Python :: 3.12
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
||||||
|
Classifier: Topic :: Text Processing :: Linguistic
|
||||||
|
Classifier: Topic :: Utilities
|
||||||
|
Classifier: Typing :: Typed
|
||||||
|
Requires-Python: >=3.7.0
|
||||||
|
Description-Content-Type: text/markdown
|
||||||
|
License-File: LICENSE
|
||||||
|
Provides-Extra: unicode_backport
|
||||||
|
|
||||||
|
<h1 align="center">Charset Detection, for Everyone 👋</h1>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<sup>The Real First Universal Charset Detector</sup><br>
|
||||||
|
<a href="https://pypi.org/project/charset-normalizer">
|
||||||
|
<img src="https://img.shields.io/pypi/pyversions/charset_normalizer.svg?orange=blue" />
|
||||||
|
</a>
|
||||||
|
<a href="https://pepy.tech/project/charset-normalizer/">
|
||||||
|
<img alt="Download Count Total" src="https://static.pepy.tech/badge/charset-normalizer/month" />
|
||||||
|
</a>
|
||||||
|
<a href="https://bestpractices.coreinfrastructure.org/projects/7297">
|
||||||
|
<img src="https://bestpractices.coreinfrastructure.org/projects/7297/badge">
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
<p align="center">
|
||||||
|
<sup><i>Featured Packages</i></sup><br>
|
||||||
|
<a href="https://github.com/jawah/niquests">
|
||||||
|
<img alt="Static Badge" src="https://img.shields.io/badge/Niquests-HTTP_1.1%2C%202%2C_and_3_Client-cyan">
|
||||||
|
</a>
|
||||||
|
<a href="https://github.com/jawah/wassima">
|
||||||
|
<img alt="Static Badge" src="https://img.shields.io/badge/Wassima-Certifi_Killer-cyan">
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
<p align="center">
|
||||||
|
<sup><i>In other language (unofficial port - by the community)</i></sup><br>
|
||||||
|
<a href="https://github.com/nickspring/charset-normalizer-rs">
|
||||||
|
<img alt="Static Badge" src="https://img.shields.io/badge/Rust-red">
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
> A library that helps you read text from an unknown charset encoding.<br /> Motivated by `chardet`,
|
||||||
|
> I'm trying to resolve the issue by taking a new approach.
|
||||||
|
> All IANA character set names for which the Python core library provides codecs are supported.
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
>>>>> <a href="https://charsetnormalizerweb.ousret.now.sh" target="_blank">👉 Try Me Online Now, Then Adopt Me 👈 </a> <<<<<
|
||||||
|
</p>
|
||||||
|
|
||||||
|
This project offers you an alternative to **Universal Charset Encoding Detector**, also known as **Chardet**.
|
||||||
|
|
||||||
|
| Feature | [Chardet](https://github.com/chardet/chardet) | Charset Normalizer | [cChardet](https://github.com/PyYoshi/cChardet) |
|
||||||
|
|--------------------------------------------------|:---------------------------------------------:|:--------------------------------------------------------------------------------------------------:|:-----------------------------------------------:|
|
||||||
|
| `Fast` | ❌ | ✅ | ✅ |
|
||||||
|
| `Universal**` | ❌ | ✅ | ❌ |
|
||||||
|
| `Reliable` **without** distinguishable standards | ❌ | ✅ | ✅ |
|
||||||
|
| `Reliable` **with** distinguishable standards | ✅ | ✅ | ✅ |
|
||||||
|
| `License` | LGPL-2.1<br>_restrictive_ | MIT | MPL-1.1<br>_restrictive_ |
|
||||||
|
| `Native Python` | ✅ | ✅ | ❌ |
|
||||||
|
| `Detect spoken language` | ❌ | ✅ | N/A |
|
||||||
|
| `UnicodeDecodeError Safety` | ❌ | ✅ | ❌ |
|
||||||
|
| `Whl Size (min)` | 193.6 kB | 42 kB | ~200 kB |
|
||||||
|
| `Supported Encoding` | 33 | 🎉 [99](https://charset-normalizer.readthedocs.io/en/latest/user/support.html#supported-encodings) | 40 |
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://i.imgflip.com/373iay.gif" alt="Reading Normalized Text" width="226"/><img src="https://media.tenor.com/images/c0180f70732a18b4965448d33adba3d0/tenor.gif" alt="Cat Reading Text" width="200"/>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
*\*\* : They are clearly using specific code for a specific encoding even if covering most of used one*<br>
|
||||||
|
Did you got there because of the logs? See [https://charset-normalizer.readthedocs.io/en/latest/user/miscellaneous.html](https://charset-normalizer.readthedocs.io/en/latest/user/miscellaneous.html)
|
||||||
|
|
||||||
|
## ⚡ Performance
|
||||||
|
|
||||||
|
This package offer better performance than its counterpart Chardet. Here are some numbers.
|
||||||
|
|
||||||
|
| Package | Accuracy | Mean per file (ms) | File per sec (est) |
|
||||||
|
|-----------------------------------------------|:--------:|:------------------:|:------------------:|
|
||||||
|
| [chardet](https://github.com/chardet/chardet) | 86 % | 200 ms | 5 file/sec |
|
||||||
|
| charset-normalizer | **98 %** | **10 ms** | 100 file/sec |
|
||||||
|
|
||||||
|
| Package | 99th percentile | 95th percentile | 50th percentile |
|
||||||
|
|-----------------------------------------------|:---------------:|:---------------:|:---------------:|
|
||||||
|
| [chardet](https://github.com/chardet/chardet) | 1200 ms | 287 ms | 23 ms |
|
||||||
|
| charset-normalizer | 100 ms | 50 ms | 5 ms |
|
||||||
|
|
||||||
|
Chardet's performance on larger file (1MB+) are very poor. Expect huge difference on large payload.
|
||||||
|
|
||||||
|
> Stats are generated using 400+ files using default parameters. More details on used files, see GHA workflows.
|
||||||
|
> And yes, these results might change at any time. The dataset can be updated to include more files.
|
||||||
|
> The actual delays heavily depends on your CPU capabilities. The factors should remain the same.
|
||||||
|
> Keep in mind that the stats are generous and that Chardet accuracy vs our is measured using Chardet initial capability
|
||||||
|
> (eg. Supported Encoding) Challenge-them if you want.
|
||||||
|
|
||||||
|
## ✨ Installation
|
||||||
|
|
||||||
|
Using pip:
|
||||||
|
|
||||||
|
```sh
|
||||||
|
pip install charset-normalizer -U
|
||||||
|
```
|
||||||
|
|
||||||
|
## 🚀 Basic Usage
|
||||||
|
|
||||||
|
### CLI
|
||||||
|
This package comes with a CLI.
|
||||||
|
|
||||||
|
```
|
||||||
|
usage: normalizer [-h] [-v] [-a] [-n] [-m] [-r] [-f] [-t THRESHOLD]
|
||||||
|
file [file ...]
|
||||||
|
|
||||||
|
The Real First Universal Charset Detector. Discover originating encoding used
|
||||||
|
on text file. Normalize text to unicode.
|
||||||
|
|
||||||
|
positional arguments:
|
||||||
|
files File(s) to be analysed
|
||||||
|
|
||||||
|
optional arguments:
|
||||||
|
-h, --help show this help message and exit
|
||||||
|
-v, --verbose Display complementary information about file if any.
|
||||||
|
Stdout will contain logs about the detection process.
|
||||||
|
-a, --with-alternative
|
||||||
|
Output complementary possibilities if any. Top-level
|
||||||
|
JSON WILL be a list.
|
||||||
|
-n, --normalize Permit to normalize input file. If not set, program
|
||||||
|
does not write anything.
|
||||||
|
-m, --minimal Only output the charset detected to STDOUT. Disabling
|
||||||
|
JSON output.
|
||||||
|
-r, --replace Replace file when trying to normalize it instead of
|
||||||
|
creating a new one.
|
||||||
|
-f, --force Replace file without asking if you are sure, use this
|
||||||
|
flag with caution.
|
||||||
|
-t THRESHOLD, --threshold THRESHOLD
|
||||||
|
Define a custom maximum amount of chaos allowed in
|
||||||
|
decoded content. 0. <= chaos <= 1.
|
||||||
|
--version Show version information and exit.
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
normalizer ./data/sample.1.fr.srt
|
||||||
|
```
|
||||||
|
|
||||||
|
or
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python -m charset_normalizer ./data/sample.1.fr.srt
|
||||||
|
```
|
||||||
|
|
||||||
|
🎉 Since version 1.4.0 the CLI produce easily usable stdout result in JSON format.
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"path": "/home/default/projects/charset_normalizer/data/sample.1.fr.srt",
|
||||||
|
"encoding": "cp1252",
|
||||||
|
"encoding_aliases": [
|
||||||
|
"1252",
|
||||||
|
"windows_1252"
|
||||||
|
],
|
||||||
|
"alternative_encodings": [
|
||||||
|
"cp1254",
|
||||||
|
"cp1256",
|
||||||
|
"cp1258",
|
||||||
|
"iso8859_14",
|
||||||
|
"iso8859_15",
|
||||||
|
"iso8859_16",
|
||||||
|
"iso8859_3",
|
||||||
|
"iso8859_9",
|
||||||
|
"latin_1",
|
||||||
|
"mbcs"
|
||||||
|
],
|
||||||
|
"language": "French",
|
||||||
|
"alphabets": [
|
||||||
|
"Basic Latin",
|
||||||
|
"Latin-1 Supplement"
|
||||||
|
],
|
||||||
|
"has_sig_or_bom": false,
|
||||||
|
"chaos": 0.149,
|
||||||
|
"coherence": 97.152,
|
||||||
|
"unicode_path": null,
|
||||||
|
"is_preferred": true
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### Python
|
||||||
|
*Just print out normalized text*
|
||||||
|
```python
|
||||||
|
from charset_normalizer import from_path
|
||||||
|
|
||||||
|
results = from_path('./my_subtitle.srt')
|
||||||
|
|
||||||
|
print(str(results.best()))
|
||||||
|
```
|
||||||
|
|
||||||
|
*Upgrade your code without effort*
|
||||||
|
```python
|
||||||
|
from charset_normalizer import detect
|
||||||
|
```
|
||||||
|
|
||||||
|
The above code will behave the same as **chardet**. We ensure that we offer the best (reasonable) BC result possible.
|
||||||
|
|
||||||
|
See the docs for advanced usage : [readthedocs.io](https://charset-normalizer.readthedocs.io/en/latest/)
|
||||||
|
|
||||||
|
## 😇 Why
|
||||||
|
|
||||||
|
When I started using Chardet, I noticed that it was not suited to my expectations, and I wanted to propose a
|
||||||
|
reliable alternative using a completely different method. Also! I never back down on a good challenge!
|
||||||
|
|
||||||
|
I **don't care** about the **originating charset** encoding, because **two different tables** can
|
||||||
|
produce **two identical rendered string.**
|
||||||
|
What I want is to get readable text, the best I can.
|
||||||
|
|
||||||
|
In a way, **I'm brute forcing text decoding.** How cool is that ? 😎
|
||||||
|
|
||||||
|
Don't confuse package **ftfy** with charset-normalizer or chardet. ftfy goal is to repair unicode string whereas charset-normalizer to convert raw file in unknown encoding to unicode.
|
||||||
|
|
||||||
|
## 🍰 How
|
||||||
|
|
||||||
|
- Discard all charset encoding table that could not fit the binary content.
|
||||||
|
- Measure noise, or the mess once opened (by chunks) with a corresponding charset encoding.
|
||||||
|
- Extract matches with the lowest mess detected.
|
||||||
|
- Additionally, we measure coherence / probe for a language.
|
||||||
|
|
||||||
|
**Wait a minute**, what is noise/mess and coherence according to **YOU ?**
|
||||||
|
|
||||||
|
*Noise :* I opened hundred of text files, **written by humans**, with the wrong encoding table. **I observed**, then
|
||||||
|
**I established** some ground rules about **what is obvious** when **it seems like** a mess.
|
||||||
|
I know that my interpretation of what is noise is probably incomplete, feel free to contribute in order to
|
||||||
|
improve or rewrite it.
|
||||||
|
|
||||||
|
*Coherence :* For each language there is on earth, we have computed ranked letter appearance occurrences (the best we can). So I thought
|
||||||
|
that intel is worth something here. So I use those records against decoded text to check if I can detect intelligent design.
|
||||||
|
|
||||||
|
## ⚡ Known limitations
|
||||||
|
|
||||||
|
- Language detection is unreliable when text contains two or more languages sharing identical letters. (eg. HTML (english tags) + Turkish content (Sharing Latin characters))
|
||||||
|
- Every charset detector heavily depends on sufficient content. In common cases, do not bother run detection on very tiny content.
|
||||||
|
|
||||||
|
## ⚠️ About Python EOLs
|
||||||
|
|
||||||
|
**If you are running:**
|
||||||
|
|
||||||
|
- Python >=2.7,<3.5: Unsupported
|
||||||
|
- Python 3.5: charset-normalizer < 2.1
|
||||||
|
- Python 3.6: charset-normalizer < 3.1
|
||||||
|
- Python 3.7: charset-normalizer < 4.0
|
||||||
|
|
||||||
|
Upgrade your Python interpreter as soon as possible.
|
||||||
|
|
||||||
|
## 👤 Contributing
|
||||||
|
|
||||||
|
Contributions, issues and feature requests are very much welcome.<br />
|
||||||
|
Feel free to check [issues page](https://github.com/ousret/charset_normalizer/issues) if you want to contribute.
|
||||||
|
|
||||||
|
## 📝 License
|
||||||
|
|
||||||
|
Copyright © [Ahmed TAHRI @Ousret](https://github.com/Ousret).<br />
|
||||||
|
This project is [MIT](https://github.com/Ousret/charset_normalizer/blob/master/LICENSE) licensed.
|
||||||
|
|
||||||
|
Characters frequencies used in this project © 2012 [Denny Vrandečić](http://simia.net/letters/)
|
||||||
|
|
||||||
|
## 💼 For Enterprise
|
||||||
|
|
||||||
|
Professional support for charset-normalizer is available as part of the [Tidelift
|
||||||
|
Subscription][1]. Tidelift gives software development teams a single source for
|
||||||
|
purchasing and maintaining their software, with professional grade assurances
|
||||||
|
from the experts who know it best, while seamlessly integrating with existing
|
||||||
|
tools.
|
||||||
|
|
||||||
|
[1]: https://tidelift.com/subscription/pkg/pypi-charset-normalizer?utm_source=pypi-charset-normalizer&utm_medium=readme
|
||||||
|
|
||||||
|
# Changelog
|
||||||
|
All notable changes to charset-normalizer will be documented in this file. This project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
|
||||||
|
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/).
|
||||||
|
|
||||||
|
## [3.3.2](https://github.com/Ousret/charset_normalizer/compare/3.3.1...3.3.2) (2023-10-31)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Unintentional memory usage regression when using large payload that match several encoding (#376)
|
||||||
|
- Regression on some detection case showcased in the documentation (#371)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Noise (md) probe that identify malformed arabic representation due to the presence of letters in isolated form (credit to my wife)
|
||||||
|
|
||||||
|
## [3.3.1](https://github.com/Ousret/charset_normalizer/compare/3.3.0...3.3.1) (2023-10-22)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Optional mypyc compilation upgraded to version 1.6.1 for Python >= 3.8
|
||||||
|
- Improved the general detection reliability based on reports from the community
|
||||||
|
|
||||||
|
## [3.3.0](https://github.com/Ousret/charset_normalizer/compare/3.2.0...3.3.0) (2023-09-30)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Allow to execute the CLI (e.g. normalizer) through `python -m charset_normalizer.cli` or `python -m charset_normalizer`
|
||||||
|
- Support for 9 forgotten encoding that are supported by Python but unlisted in `encoding.aliases` as they have no alias (#323)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- (internal) Redundant utils.is_ascii function and unused function is_private_use_only
|
||||||
|
- (internal) charset_normalizer.assets is moved inside charset_normalizer.constant
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- (internal) Unicode code blocks in constants are updated using the latest v15.0.0 definition to improve detection
|
||||||
|
- Optional mypyc compilation upgraded to version 1.5.1 for Python >= 3.8
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Unable to properly sort CharsetMatch when both chaos/noise and coherence were close due to an unreachable condition in \_\_lt\_\_ (#350)
|
||||||
|
|
||||||
|
## [3.2.0](https://github.com/Ousret/charset_normalizer/compare/3.1.0...3.2.0) (2023-06-07)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Typehint for function `from_path` no longer enforce `PathLike` as its first argument
|
||||||
|
- Minor improvement over the global detection reliability
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Introduce function `is_binary` that relies on main capabilities, and optimized to detect binaries
|
||||||
|
- Propagate `enable_fallback` argument throughout `from_bytes`, `from_path`, and `from_fp` that allow a deeper control over the detection (default True)
|
||||||
|
- Explicit support for Python 3.12
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Edge case detection failure where a file would contain 'very-long' camel cased word (Issue #289)
|
||||||
|
|
||||||
|
## [3.1.0](https://github.com/Ousret/charset_normalizer/compare/3.0.1...3.1.0) (2023-03-06)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Argument `should_rename_legacy` for legacy function `detect` and disregard any new arguments without errors (PR #262)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Support for Python 3.6 (PR #260)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Optional speedup provided by mypy/c 1.0.1
|
||||||
|
|
||||||
|
## [3.0.1](https://github.com/Ousret/charset_normalizer/compare/3.0.0...3.0.1) (2022-11-18)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Multi-bytes cutter/chunk generator did not always cut correctly (PR #233)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Speedup provided by mypy/c 0.990 on Python >= 3.7
|
||||||
|
|
||||||
|
## [3.0.0](https://github.com/Ousret/charset_normalizer/compare/2.1.1...3.0.0) (2022-10-20)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Extend the capability of explain=True when cp_isolation contains at most two entries (min one), will log in details of the Mess-detector results
|
||||||
|
- Support for alternative language frequency set in charset_normalizer.assets.FREQUENCIES
|
||||||
|
- Add parameter `language_threshold` in `from_bytes`, `from_path` and `from_fp` to adjust the minimum expected coherence ratio
|
||||||
|
- `normalizer --version` now specify if current version provide extra speedup (meaning mypyc compilation whl)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Build with static metadata using 'build' frontend
|
||||||
|
- Make the language detection stricter
|
||||||
|
- Optional: Module `md.py` can be compiled using Mypyc to provide an extra speedup up to 4x faster than v2.1
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- CLI with opt --normalize fail when using full path for files
|
||||||
|
- TooManyAccentuatedPlugin induce false positive on the mess detection when too few alpha character have been fed to it
|
||||||
|
- Sphinx warnings when generating the documentation
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Coherence detector no longer return 'Simple English' instead return 'English'
|
||||||
|
- Coherence detector no longer return 'Classical Chinese' instead return 'Chinese'
|
||||||
|
- Breaking: Method `first()` and `best()` from CharsetMatch
|
||||||
|
- UTF-7 will no longer appear as "detected" without a recognized SIG/mark (is unreliable/conflict with ASCII)
|
||||||
|
- Breaking: Class aliases CharsetDetector, CharsetDoctor, CharsetNormalizerMatch and CharsetNormalizerMatches
|
||||||
|
- Breaking: Top-level function `normalize`
|
||||||
|
- Breaking: Properties `chaos_secondary_pass`, `coherence_non_latin` and `w_counter` from CharsetMatch
|
||||||
|
- Support for the backport `unicodedata2`
|
||||||
|
|
||||||
|
## [3.0.0rc1](https://github.com/Ousret/charset_normalizer/compare/3.0.0b2...3.0.0rc1) (2022-10-18)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Extend the capability of explain=True when cp_isolation contains at most two entries (min one), will log in details of the Mess-detector results
|
||||||
|
- Support for alternative language frequency set in charset_normalizer.assets.FREQUENCIES
|
||||||
|
- Add parameter `language_threshold` in `from_bytes`, `from_path` and `from_fp` to adjust the minimum expected coherence ratio
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Build with static metadata using 'build' frontend
|
||||||
|
- Make the language detection stricter
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- CLI with opt --normalize fail when using full path for files
|
||||||
|
- TooManyAccentuatedPlugin induce false positive on the mess detection when too few alpha character have been fed to it
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Coherence detector no longer return 'Simple English' instead return 'English'
|
||||||
|
- Coherence detector no longer return 'Classical Chinese' instead return 'Chinese'
|
||||||
|
|
||||||
|
## [3.0.0b2](https://github.com/Ousret/charset_normalizer/compare/3.0.0b1...3.0.0b2) (2022-08-21)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- `normalizer --version` now specify if current version provide extra speedup (meaning mypyc compilation whl)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Breaking: Method `first()` and `best()` from CharsetMatch
|
||||||
|
- UTF-7 will no longer appear as "detected" without a recognized SIG/mark (is unreliable/conflict with ASCII)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Sphinx warnings when generating the documentation
|
||||||
|
|
||||||
|
## [3.0.0b1](https://github.com/Ousret/charset_normalizer/compare/2.1.0...3.0.0b1) (2022-08-15)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Optional: Module `md.py` can be compiled using Mypyc to provide an extra speedup up to 4x faster than v2.1
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Breaking: Class aliases CharsetDetector, CharsetDoctor, CharsetNormalizerMatch and CharsetNormalizerMatches
|
||||||
|
- Breaking: Top-level function `normalize`
|
||||||
|
- Breaking: Properties `chaos_secondary_pass`, `coherence_non_latin` and `w_counter` from CharsetMatch
|
||||||
|
- Support for the backport `unicodedata2`
|
||||||
|
|
||||||
|
## [2.1.1](https://github.com/Ousret/charset_normalizer/compare/2.1.0...2.1.1) (2022-08-19)
|
||||||
|
|
||||||
|
### Deprecated
|
||||||
|
- Function `normalize` scheduled for removal in 3.0
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Removed useless call to decode in fn is_unprintable (#206)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Third-party library (i18n xgettext) crashing not recognizing utf_8 (PEP 263) with underscore from [@aleksandernovikov](https://github.com/aleksandernovikov) (#204)
|
||||||
|
|
||||||
|
## [2.1.0](https://github.com/Ousret/charset_normalizer/compare/2.0.12...2.1.0) (2022-06-19)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Output the Unicode table version when running the CLI with `--version` (PR #194)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Re-use decoded buffer for single byte character sets from [@nijel](https://github.com/nijel) (PR #175)
|
||||||
|
- Fixing some performance bottlenecks from [@deedy5](https://github.com/deedy5) (PR #183)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Workaround potential bug in cpython with Zero Width No-Break Space located in Arabic Presentation Forms-B, Unicode 1.1 not acknowledged as space (PR #175)
|
||||||
|
- CLI default threshold aligned with the API threshold from [@oleksandr-kuzmenko](https://github.com/oleksandr-kuzmenko) (PR #181)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Support for Python 3.5 (PR #192)
|
||||||
|
|
||||||
|
### Deprecated
|
||||||
|
- Use of backport unicodedata from `unicodedata2` as Python is quickly catching up, scheduled for removal in 3.0 (PR #194)
|
||||||
|
|
||||||
|
## [2.0.12](https://github.com/Ousret/charset_normalizer/compare/2.0.11...2.0.12) (2022-02-12)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- ASCII miss-detection on rare cases (PR #170)
|
||||||
|
|
||||||
|
## [2.0.11](https://github.com/Ousret/charset_normalizer/compare/2.0.10...2.0.11) (2022-01-30)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Explicit support for Python 3.11 (PR #164)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- The logging behavior have been completely reviewed, now using only TRACE and DEBUG levels (PR #163 #165)
|
||||||
|
|
||||||
|
## [2.0.10](https://github.com/Ousret/charset_normalizer/compare/2.0.9...2.0.10) (2022-01-04)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fallback match entries might lead to UnicodeDecodeError for large bytes sequence (PR #154)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Skipping the language-detection (CD) on ASCII (PR #155)
|
||||||
|
|
||||||
|
## [2.0.9](https://github.com/Ousret/charset_normalizer/compare/2.0.8...2.0.9) (2021-12-03)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Moderating the logging impact (since 2.0.8) for specific environments (PR #147)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Wrong logging level applied when setting kwarg `explain` to True (PR #146)
|
||||||
|
|
||||||
|
## [2.0.8](https://github.com/Ousret/charset_normalizer/compare/2.0.7...2.0.8) (2021-11-24)
|
||||||
|
### Changed
|
||||||
|
- Improvement over Vietnamese detection (PR #126)
|
||||||
|
- MD improvement on trailing data and long foreign (non-pure latin) data (PR #124)
|
||||||
|
- Efficiency improvements in cd/alphabet_languages from [@adbar](https://github.com/adbar) (PR #122)
|
||||||
|
- call sum() without an intermediary list following PEP 289 recommendations from [@adbar](https://github.com/adbar) (PR #129)
|
||||||
|
- Code style as refactored by Sourcery-AI (PR #131)
|
||||||
|
- Minor adjustment on the MD around european words (PR #133)
|
||||||
|
- Remove and replace SRTs from assets / tests (PR #139)
|
||||||
|
- Initialize the library logger with a `NullHandler` by default from [@nmaynes](https://github.com/nmaynes) (PR #135)
|
||||||
|
- Setting kwarg `explain` to True will add provisionally (bounded to function lifespan) a specific stream handler (PR #135)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fix large (misleading) sequence giving UnicodeDecodeError (PR #137)
|
||||||
|
- Avoid using too insignificant chunk (PR #137)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Add and expose function `set_logging_handler` to configure a specific StreamHandler from [@nmaynes](https://github.com/nmaynes) (PR #135)
|
||||||
|
- Add `CHANGELOG.md` entries, format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/) (PR #141)
|
||||||
|
|
||||||
|
## [2.0.7](https://github.com/Ousret/charset_normalizer/compare/2.0.6...2.0.7) (2021-10-11)
|
||||||
|
### Added
|
||||||
|
- Add support for Kazakh (Cyrillic) language detection (PR #109)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Further, improve inferring the language from a given single-byte code page (PR #112)
|
||||||
|
- Vainly trying to leverage PEP263 when PEP3120 is not supported (PR #116)
|
||||||
|
- Refactoring for potential performance improvements in loops from [@adbar](https://github.com/adbar) (PR #113)
|
||||||
|
- Various detection improvement (MD+CD) (PR #117)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Remove redundant logging entry about detected language(s) (PR #115)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fix a minor inconsistency between Python 3.5 and other versions regarding language detection (PR #117 #102)
|
||||||
|
|
||||||
|
## [2.0.6](https://github.com/Ousret/charset_normalizer/compare/2.0.5...2.0.6) (2021-09-18)
|
||||||
|
### Fixed
|
||||||
|
- Unforeseen regression with the loss of the backward-compatibility with some older minor of Python 3.5.x (PR #100)
|
||||||
|
- Fix CLI crash when using --minimal output in certain cases (PR #103)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Minor improvement to the detection efficiency (less than 1%) (PR #106 #101)
|
||||||
|
|
||||||
|
## [2.0.5](https://github.com/Ousret/charset_normalizer/compare/2.0.4...2.0.5) (2021-09-14)
|
||||||
|
### Changed
|
||||||
|
- The project now comply with: flake8, mypy, isort and black to ensure a better overall quality (PR #81)
|
||||||
|
- The BC-support with v1.x was improved, the old staticmethods are restored (PR #82)
|
||||||
|
- The Unicode detection is slightly improved (PR #93)
|
||||||
|
- Add syntax sugar \_\_bool\_\_ for results CharsetMatches list-container (PR #91)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- The project no longer raise warning on tiny content given for detection, will be simply logged as warning instead (PR #92)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- In some rare case, the chunks extractor could cut in the middle of a multi-byte character and could mislead the mess detection (PR #95)
|
||||||
|
- Some rare 'space' characters could trip up the UnprintablePlugin/Mess detection (PR #96)
|
||||||
|
- The MANIFEST.in was not exhaustive (PR #78)
|
||||||
|
|
||||||
|
## [2.0.4](https://github.com/Ousret/charset_normalizer/compare/2.0.3...2.0.4) (2021-07-30)
|
||||||
|
### Fixed
|
||||||
|
- The CLI no longer raise an unexpected exception when no encoding has been found (PR #70)
|
||||||
|
- Fix accessing the 'alphabets' property when the payload contains surrogate characters (PR #68)
|
||||||
|
- The logger could mislead (explain=True) on detected languages and the impact of one MBCS match (PR #72)
|
||||||
|
- Submatch factoring could be wrong in rare edge cases (PR #72)
|
||||||
|
- Multiple files given to the CLI were ignored when publishing results to STDOUT. (After the first path) (PR #72)
|
||||||
|
- Fix line endings from CRLF to LF for certain project files (PR #67)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Adjust the MD to lower the sensitivity, thus improving the global detection reliability (PR #69 #76)
|
||||||
|
- Allow fallback on specified encoding if any (PR #71)
|
||||||
|
|
||||||
|
## [2.0.3](https://github.com/Ousret/charset_normalizer/compare/2.0.2...2.0.3) (2021-07-16)
|
||||||
|
### Changed
|
||||||
|
- Part of the detection mechanism has been improved to be less sensitive, resulting in more accurate detection results. Especially ASCII. (PR #63)
|
||||||
|
- According to the community wishes, the detection will fall back on ASCII or UTF-8 in a last-resort case. (PR #64)
|
||||||
|
|
||||||
|
## [2.0.2](https://github.com/Ousret/charset_normalizer/compare/2.0.1...2.0.2) (2021-07-15)
|
||||||
|
### Fixed
|
||||||
|
- Empty/Too small JSON payload miss-detection fixed. Report from [@tseaver](https://github.com/tseaver) (PR #59)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Don't inject unicodedata2 into sys.modules from [@akx](https://github.com/akx) (PR #57)
|
||||||
|
|
||||||
|
## [2.0.1](https://github.com/Ousret/charset_normalizer/compare/2.0.0...2.0.1) (2021-07-13)
|
||||||
|
### Fixed
|
||||||
|
- Make it work where there isn't a filesystem available, dropping assets frequencies.json. Report from [@sethmlarson](https://github.com/sethmlarson). (PR #55)
|
||||||
|
- Using explain=False permanently disable the verbose output in the current runtime (PR #47)
|
||||||
|
- One log entry (language target preemptive) was not show in logs when using explain=True (PR #47)
|
||||||
|
- Fix undesired exception (ValueError) on getitem of instance CharsetMatches (PR #52)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Public function normalize default args values were not aligned with from_bytes (PR #53)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- You may now use charset aliases in cp_isolation and cp_exclusion arguments (PR #47)
|
||||||
|
|
||||||
|
## [2.0.0](https://github.com/Ousret/charset_normalizer/compare/1.4.1...2.0.0) (2021-07-02)
|
||||||
|
### Changed
|
||||||
|
- 4x to 5 times faster than the previous 1.4.0 release. At least 2x faster than Chardet.
|
||||||
|
- Accent has been made on UTF-8 detection, should perform rather instantaneous.
|
||||||
|
- The backward compatibility with Chardet has been greatly improved. The legacy detect function returns an identical charset name whenever possible.
|
||||||
|
- The detection mechanism has been slightly improved, now Turkish content is detected correctly (most of the time)
|
||||||
|
- The program has been rewritten to ease the readability and maintainability. (+Using static typing)+
|
||||||
|
- utf_7 detection has been reinstated.
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- This package no longer require anything when used with Python 3.5 (Dropped cached_property)
|
||||||
|
- Removed support for these languages: Catalan, Esperanto, Kazakh, Baque, Volapük, Azeri, Galician, Nynorsk, Macedonian, and Serbocroatian.
|
||||||
|
- The exception hook on UnicodeDecodeError has been removed.
|
||||||
|
|
||||||
|
### Deprecated
|
||||||
|
- Methods coherence_non_latin, w_counter, chaos_secondary_pass of the class CharsetMatch are now deprecated and scheduled for removal in v3.0
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- The CLI output used the relative path of the file(s). Should be absolute.
|
||||||
|
|
||||||
|
## [1.4.1](https://github.com/Ousret/charset_normalizer/compare/1.4.0...1.4.1) (2021-05-28)
|
||||||
|
### Fixed
|
||||||
|
- Logger configuration/usage no longer conflict with others (PR #44)
|
||||||
|
|
||||||
|
## [1.4.0](https://github.com/Ousret/charset_normalizer/compare/1.3.9...1.4.0) (2021-05-21)
|
||||||
|
### Removed
|
||||||
|
- Using standard logging instead of using the package loguru.
|
||||||
|
- Dropping nose test framework in favor of the maintained pytest.
|
||||||
|
- Choose to not use dragonmapper package to help with gibberish Chinese/CJK text.
|
||||||
|
- Require cached_property only for Python 3.5 due to constraint. Dropping for every other interpreter version.
|
||||||
|
- Stop support for UTF-7 that does not contain a SIG.
|
||||||
|
- Dropping PrettyTable, replaced with pure JSON output in CLI.
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- BOM marker in a CharsetNormalizerMatch instance could be False in rare cases even if obviously present. Due to the sub-match factoring process.
|
||||||
|
- Not searching properly for the BOM when trying utf32/16 parent codec.
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Improving the package final size by compressing frequencies.json.
|
||||||
|
- Huge improvement over the larges payload.
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- CLI now produces JSON consumable output.
|
||||||
|
- Return ASCII if given sequences fit. Given reasonable confidence.
|
||||||
|
|
||||||
|
## [1.3.9](https://github.com/Ousret/charset_normalizer/compare/1.3.8...1.3.9) (2021-05-13)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- In some very rare cases, you may end up getting encode/decode errors due to a bad bytes payload (PR #40)
|
||||||
|
|
||||||
|
## [1.3.8](https://github.com/Ousret/charset_normalizer/compare/1.3.7...1.3.8) (2021-05-12)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Empty given payload for detection may cause an exception if trying to access the `alphabets` property. (PR #39)
|
||||||
|
|
||||||
|
## [1.3.7](https://github.com/Ousret/charset_normalizer/compare/1.3.6...1.3.7) (2021-05-12)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- The legacy detect function should return UTF-8-SIG if sig is present in the payload. (PR #38)
|
||||||
|
|
||||||
|
## [1.3.6](https://github.com/Ousret/charset_normalizer/compare/1.3.5...1.3.6) (2021-02-09)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Amend the previous release to allow prettytable 2.0 (PR #35)
|
||||||
|
|
||||||
|
## [1.3.5](https://github.com/Ousret/charset_normalizer/compare/1.3.4...1.3.5) (2021-02-08)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fix error while using the package with a python pre-release interpreter (PR #33)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Dependencies refactoring, constraints revised.
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Add python 3.9 and 3.10 to the supported interpreters
|
||||||
|
|
||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2019 TAHRI Ahmed R.
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
|
|
@ -0,0 +1,35 @@
|
||||||
|
../../Scripts/normalizer.exe,sha256=I1urYT7S5Xur-aSbzHWFc6mDehEOECjOR7NmuUySBKE,108436
|
||||||
|
charset_normalizer-3.3.2.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
||||||
|
charset_normalizer-3.3.2.dist-info/LICENSE,sha256=znnj1Var_lZ-hzOvD5W50wcQDp9qls3SD2xIau88ufc,1090
|
||||||
|
charset_normalizer-3.3.2.dist-info/METADATA,sha256=hHDqDpXmQH3f8XSn30NlqB3R3NuhJzXC0zABqFwA6Nk,34233
|
||||||
|
charset_normalizer-3.3.2.dist-info/RECORD,,
|
||||||
|
charset_normalizer-3.3.2.dist-info/WHEEL,sha256=aDrgWfEd5Ac7WJzHsr90rcMGiH4MHbAXoCWpyP5CEBc,102
|
||||||
|
charset_normalizer-3.3.2.dist-info/entry_points.txt,sha256=ADSTKrkXZ3hhdOVFi6DcUEHQRS0xfxDIE_pEz4wLIXA,65
|
||||||
|
charset_normalizer-3.3.2.dist-info/top_level.txt,sha256=7ASyzePr8_xuZWJsnqJjIBtyV8vhEo0wBCv1MPRRi3Q,19
|
||||||
|
charset_normalizer/__init__.py,sha256=m1cUEsb9K5v831m9P_lv2JlUEKD7MhxL7fxw3hn75o4,1623
|
||||||
|
charset_normalizer/__main__.py,sha256=nVnMo31hTPN2Yy045GJIvHj3dKDJz4dAQR3cUSdvYyc,77
|
||||||
|
charset_normalizer/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/__main__.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/api.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/cd.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/constant.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/legacy.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/md.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/models.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/utils.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/version.cpython-312.pyc,,
|
||||||
|
charset_normalizer/api.py,sha256=qFL0frUrcfcYEJmGpqoJ4Af68ToVue3f5SK1gp8UC5Q,21723
|
||||||
|
charset_normalizer/cd.py,sha256=Yfk3sbee0Xqo1-vmQYbOqM51-SajXPLzFVG89nTsZzc,12955
|
||||||
|
charset_normalizer/cli/__init__.py,sha256=COwP8fK2qbuldMem2lL81JieY-PIA2G2GZ5IdAPMPFA,106
|
||||||
|
charset_normalizer/cli/__main__.py,sha256=rs-cBipBzr7d0TAaUa0nG4qrjXhdddeCVB-f6Xt_wS0,10040
|
||||||
|
charset_normalizer/cli/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
charset_normalizer/cli/__pycache__/__main__.cpython-312.pyc,,
|
||||||
|
charset_normalizer/constant.py,sha256=2tVrXQ9cvC8jt0b8gZzRXvXte1pVbRra0A5dOWDQSao,42476
|
||||||
|
charset_normalizer/legacy.py,sha256=KbJxEpu7g6zE2uXSB3T-3178cgiSQdVJlJmY-gv3EAM,2125
|
||||||
|
charset_normalizer/md.cp312-win_amd64.pyd,sha256=7PEuLAoAwO1OI0PqlW147tVeWja6SXc2M7Lf57BDNcA,10752
|
||||||
|
charset_normalizer/md.py,sha256=F7S001NdPgkAoma2w598Idx2clW9ljXlRIYKZQKsCQA,20239
|
||||||
|
charset_normalizer/md__mypyc.cp312-win_amd64.pyd,sha256=QQex1vEdhCB0qfITIykLvpfo7tSqd4-8NI7gnMT6Rjc,122880
|
||||||
|
charset_normalizer/models.py,sha256=AlehuyGDE74jhryjg6TTkYh1MCntfxXFfGhTi0esu-Y,11964
|
||||||
|
charset_normalizer/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
||||||
|
charset_normalizer/utils.py,sha256=jjvfSXHJD6QPgxcxIx4utsOFx3PxFssWef1IYxA3uKs,12315
|
||||||
|
charset_normalizer/version.py,sha256=q3fF12xGlBuaub5kroTZt7lBPQLO3kFvMnkoEnt-6YA,85
|
||||||
|
|
@ -0,0 +1,5 @@
|
||||||
|
Wheel-Version: 1.0
|
||||||
|
Generator: bdist_wheel (0.41.2)
|
||||||
|
Root-Is-Purelib: false
|
||||||
|
Tag: cp312-cp312-win_amd64
|
||||||
|
|
||||||
|
|
@ -0,0 +1,2 @@
|
||||||
|
[console_scripts]
|
||||||
|
normalizer = charset_normalizer.cli:cli_detect
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
charset_normalizer
|
||||||
|
|
@ -0,0 +1,46 @@
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
"""
|
||||||
|
Charset-Normalizer
|
||||||
|
~~~~~~~~~~~~~~
|
||||||
|
The Real First Universal Charset Detector.
|
||||||
|
A library that helps you read text from an unknown charset encoding.
|
||||||
|
Motivated by chardet, This package is trying to resolve the issue by taking a new approach.
|
||||||
|
All IANA character set names for which the Python core library provides codecs are supported.
|
||||||
|
|
||||||
|
Basic usage:
|
||||||
|
>>> from charset_normalizer import from_bytes
|
||||||
|
>>> results = from_bytes('Bсеки човек има право на образование. Oбразованието!'.encode('utf_8'))
|
||||||
|
>>> best_guess = results.best()
|
||||||
|
>>> str(best_guess)
|
||||||
|
'Bсеки човек има право на образование. Oбразованието!'
|
||||||
|
|
||||||
|
Others methods and usages are available - see the full documentation
|
||||||
|
at <https://github.com/Ousret/charset_normalizer>.
|
||||||
|
:copyright: (c) 2021 by Ahmed TAHRI
|
||||||
|
:license: MIT, see LICENSE for more details.
|
||||||
|
"""
|
||||||
|
import logging
|
||||||
|
|
||||||
|
from .api import from_bytes, from_fp, from_path, is_binary
|
||||||
|
from .legacy import detect
|
||||||
|
from .models import CharsetMatch, CharsetMatches
|
||||||
|
from .utils import set_logging_handler
|
||||||
|
from .version import VERSION, __version__
|
||||||
|
|
||||||
|
__all__ = (
|
||||||
|
"from_fp",
|
||||||
|
"from_path",
|
||||||
|
"from_bytes",
|
||||||
|
"is_binary",
|
||||||
|
"detect",
|
||||||
|
"CharsetMatch",
|
||||||
|
"CharsetMatches",
|
||||||
|
"__version__",
|
||||||
|
"VERSION",
|
||||||
|
"set_logging_handler",
|
||||||
|
)
|
||||||
|
|
||||||
|
# Attach a NullHandler to the top level logger by default
|
||||||
|
# https://docs.python.org/3.3/howto/logging.html#configuring-logging-for-a-library
|
||||||
|
|
||||||
|
logging.getLogger("charset_normalizer").addHandler(logging.NullHandler())
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
from .cli import cli_detect
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
cli_detect()
|
||||||
|
|
@ -0,0 +1,626 @@
|
||||||
|
import logging
|
||||||
|
from os import PathLike
|
||||||
|
from typing import BinaryIO, List, Optional, Set, Union
|
||||||
|
|
||||||
|
from .cd import (
|
||||||
|
coherence_ratio,
|
||||||
|
encoding_languages,
|
||||||
|
mb_encoding_languages,
|
||||||
|
merge_coherence_ratios,
|
||||||
|
)
|
||||||
|
from .constant import IANA_SUPPORTED, TOO_BIG_SEQUENCE, TOO_SMALL_SEQUENCE, TRACE
|
||||||
|
from .md import mess_ratio
|
||||||
|
from .models import CharsetMatch, CharsetMatches
|
||||||
|
from .utils import (
|
||||||
|
any_specified_encoding,
|
||||||
|
cut_sequence_chunks,
|
||||||
|
iana_name,
|
||||||
|
identify_sig_or_bom,
|
||||||
|
is_cp_similar,
|
||||||
|
is_multi_byte_encoding,
|
||||||
|
should_strip_sig_or_bom,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Will most likely be controversial
|
||||||
|
# logging.addLevelName(TRACE, "TRACE")
|
||||||
|
logger = logging.getLogger("charset_normalizer")
|
||||||
|
explain_handler = logging.StreamHandler()
|
||||||
|
explain_handler.setFormatter(
|
||||||
|
logging.Formatter("%(asctime)s | %(levelname)s | %(message)s")
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def from_bytes(
|
||||||
|
sequences: Union[bytes, bytearray],
|
||||||
|
steps: int = 5,
|
||||||
|
chunk_size: int = 512,
|
||||||
|
threshold: float = 0.2,
|
||||||
|
cp_isolation: Optional[List[str]] = None,
|
||||||
|
cp_exclusion: Optional[List[str]] = None,
|
||||||
|
preemptive_behaviour: bool = True,
|
||||||
|
explain: bool = False,
|
||||||
|
language_threshold: float = 0.1,
|
||||||
|
enable_fallback: bool = True,
|
||||||
|
) -> CharsetMatches:
|
||||||
|
"""
|
||||||
|
Given a raw bytes sequence, return the best possibles charset usable to render str objects.
|
||||||
|
If there is no results, it is a strong indicator that the source is binary/not text.
|
||||||
|
By default, the process will extract 5 blocks of 512o each to assess the mess and coherence of a given sequence.
|
||||||
|
And will give up a particular code page after 20% of measured mess. Those criteria are customizable at will.
|
||||||
|
|
||||||
|
The preemptive behavior DOES NOT replace the traditional detection workflow, it prioritize a particular code page
|
||||||
|
but never take it for granted. Can improve the performance.
|
||||||
|
|
||||||
|
You may want to focus your attention to some code page or/and not others, use cp_isolation and cp_exclusion for that
|
||||||
|
purpose.
|
||||||
|
|
||||||
|
This function will strip the SIG in the payload/sequence every time except on UTF-16, UTF-32.
|
||||||
|
By default the library does not setup any handler other than the NullHandler, if you choose to set the 'explain'
|
||||||
|
toggle to True it will alter the logger configuration to add a StreamHandler that is suitable for debugging.
|
||||||
|
Custom logging format and handler can be set manually.
|
||||||
|
"""
|
||||||
|
|
||||||
|
if not isinstance(sequences, (bytearray, bytes)):
|
||||||
|
raise TypeError(
|
||||||
|
"Expected object of type bytes or bytearray, got: {0}".format(
|
||||||
|
type(sequences)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if explain:
|
||||||
|
previous_logger_level: int = logger.level
|
||||||
|
logger.addHandler(explain_handler)
|
||||||
|
logger.setLevel(TRACE)
|
||||||
|
|
||||||
|
length: int = len(sequences)
|
||||||
|
|
||||||
|
if length == 0:
|
||||||
|
logger.debug("Encoding detection on empty bytes, assuming utf_8 intention.")
|
||||||
|
if explain:
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level or logging.WARNING)
|
||||||
|
return CharsetMatches([CharsetMatch(sequences, "utf_8", 0.0, False, [], "")])
|
||||||
|
|
||||||
|
if cp_isolation is not None:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"cp_isolation is set. use this flag for debugging purpose. "
|
||||||
|
"limited list of encoding allowed : %s.",
|
||||||
|
", ".join(cp_isolation),
|
||||||
|
)
|
||||||
|
cp_isolation = [iana_name(cp, False) for cp in cp_isolation]
|
||||||
|
else:
|
||||||
|
cp_isolation = []
|
||||||
|
|
||||||
|
if cp_exclusion is not None:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"cp_exclusion is set. use this flag for debugging purpose. "
|
||||||
|
"limited list of encoding excluded : %s.",
|
||||||
|
", ".join(cp_exclusion),
|
||||||
|
)
|
||||||
|
cp_exclusion = [iana_name(cp, False) for cp in cp_exclusion]
|
||||||
|
else:
|
||||||
|
cp_exclusion = []
|
||||||
|
|
||||||
|
if length <= (chunk_size * steps):
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"override steps (%i) and chunk_size (%i) as content does not fit (%i byte(s) given) parameters.",
|
||||||
|
steps,
|
||||||
|
chunk_size,
|
||||||
|
length,
|
||||||
|
)
|
||||||
|
steps = 1
|
||||||
|
chunk_size = length
|
||||||
|
|
||||||
|
if steps > 1 and length / steps < chunk_size:
|
||||||
|
chunk_size = int(length / steps)
|
||||||
|
|
||||||
|
is_too_small_sequence: bool = len(sequences) < TOO_SMALL_SEQUENCE
|
||||||
|
is_too_large_sequence: bool = len(sequences) >= TOO_BIG_SEQUENCE
|
||||||
|
|
||||||
|
if is_too_small_sequence:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Trying to detect encoding from a tiny portion of ({}) byte(s).".format(
|
||||||
|
length
|
||||||
|
),
|
||||||
|
)
|
||||||
|
elif is_too_large_sequence:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Using lazy str decoding because the payload is quite large, ({}) byte(s).".format(
|
||||||
|
length
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
prioritized_encodings: List[str] = []
|
||||||
|
|
||||||
|
specified_encoding: Optional[str] = (
|
||||||
|
any_specified_encoding(sequences) if preemptive_behaviour else None
|
||||||
|
)
|
||||||
|
|
||||||
|
if specified_encoding is not None:
|
||||||
|
prioritized_encodings.append(specified_encoding)
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Detected declarative mark in sequence. Priority +1 given for %s.",
|
||||||
|
specified_encoding,
|
||||||
|
)
|
||||||
|
|
||||||
|
tested: Set[str] = set()
|
||||||
|
tested_but_hard_failure: List[str] = []
|
||||||
|
tested_but_soft_failure: List[str] = []
|
||||||
|
|
||||||
|
fallback_ascii: Optional[CharsetMatch] = None
|
||||||
|
fallback_u8: Optional[CharsetMatch] = None
|
||||||
|
fallback_specified: Optional[CharsetMatch] = None
|
||||||
|
|
||||||
|
results: CharsetMatches = CharsetMatches()
|
||||||
|
|
||||||
|
sig_encoding, sig_payload = identify_sig_or_bom(sequences)
|
||||||
|
|
||||||
|
if sig_encoding is not None:
|
||||||
|
prioritized_encodings.append(sig_encoding)
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Detected a SIG or BOM mark on first %i byte(s). Priority +1 given for %s.",
|
||||||
|
len(sig_payload),
|
||||||
|
sig_encoding,
|
||||||
|
)
|
||||||
|
|
||||||
|
prioritized_encodings.append("ascii")
|
||||||
|
|
||||||
|
if "utf_8" not in prioritized_encodings:
|
||||||
|
prioritized_encodings.append("utf_8")
|
||||||
|
|
||||||
|
for encoding_iana in prioritized_encodings + IANA_SUPPORTED:
|
||||||
|
if cp_isolation and encoding_iana not in cp_isolation:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if cp_exclusion and encoding_iana in cp_exclusion:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if encoding_iana in tested:
|
||||||
|
continue
|
||||||
|
|
||||||
|
tested.add(encoding_iana)
|
||||||
|
|
||||||
|
decoded_payload: Optional[str] = None
|
||||||
|
bom_or_sig_available: bool = sig_encoding == encoding_iana
|
||||||
|
strip_sig_or_bom: bool = bom_or_sig_available and should_strip_sig_or_bom(
|
||||||
|
encoding_iana
|
||||||
|
)
|
||||||
|
|
||||||
|
if encoding_iana in {"utf_16", "utf_32"} and not bom_or_sig_available:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Encoding %s won't be tested as-is because it require a BOM. Will try some sub-encoder LE/BE.",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
if encoding_iana in {"utf_7"} and not bom_or_sig_available:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Encoding %s won't be tested as-is because detection is unreliable without BOM/SIG.",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
is_multi_byte_decoder: bool = is_multi_byte_encoding(encoding_iana)
|
||||||
|
except (ModuleNotFoundError, ImportError):
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Encoding %s does not provide an IncrementalDecoder",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
if is_too_large_sequence and is_multi_byte_decoder is False:
|
||||||
|
str(
|
||||||
|
sequences[: int(50e4)]
|
||||||
|
if strip_sig_or_bom is False
|
||||||
|
else sequences[len(sig_payload) : int(50e4)],
|
||||||
|
encoding=encoding_iana,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
decoded_payload = str(
|
||||||
|
sequences
|
||||||
|
if strip_sig_or_bom is False
|
||||||
|
else sequences[len(sig_payload) :],
|
||||||
|
encoding=encoding_iana,
|
||||||
|
)
|
||||||
|
except (UnicodeDecodeError, LookupError) as e:
|
||||||
|
if not isinstance(e, LookupError):
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Code page %s does not fit given bytes sequence at ALL. %s",
|
||||||
|
encoding_iana,
|
||||||
|
str(e),
|
||||||
|
)
|
||||||
|
tested_but_hard_failure.append(encoding_iana)
|
||||||
|
continue
|
||||||
|
|
||||||
|
similar_soft_failure_test: bool = False
|
||||||
|
|
||||||
|
for encoding_soft_failed in tested_but_soft_failure:
|
||||||
|
if is_cp_similar(encoding_iana, encoding_soft_failed):
|
||||||
|
similar_soft_failure_test = True
|
||||||
|
break
|
||||||
|
|
||||||
|
if similar_soft_failure_test:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"%s is deemed too similar to code page %s and was consider unsuited already. Continuing!",
|
||||||
|
encoding_iana,
|
||||||
|
encoding_soft_failed,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
r_ = range(
|
||||||
|
0 if not bom_or_sig_available else len(sig_payload),
|
||||||
|
length,
|
||||||
|
int(length / steps),
|
||||||
|
)
|
||||||
|
|
||||||
|
multi_byte_bonus: bool = (
|
||||||
|
is_multi_byte_decoder
|
||||||
|
and decoded_payload is not None
|
||||||
|
and len(decoded_payload) < length
|
||||||
|
)
|
||||||
|
|
||||||
|
if multi_byte_bonus:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Code page %s is a multi byte encoding table and it appear that at least one character "
|
||||||
|
"was encoded using n-bytes.",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
|
||||||
|
max_chunk_gave_up: int = int(len(r_) / 4)
|
||||||
|
|
||||||
|
max_chunk_gave_up = max(max_chunk_gave_up, 2)
|
||||||
|
early_stop_count: int = 0
|
||||||
|
lazy_str_hard_failure = False
|
||||||
|
|
||||||
|
md_chunks: List[str] = []
|
||||||
|
md_ratios = []
|
||||||
|
|
||||||
|
try:
|
||||||
|
for chunk in cut_sequence_chunks(
|
||||||
|
sequences,
|
||||||
|
encoding_iana,
|
||||||
|
r_,
|
||||||
|
chunk_size,
|
||||||
|
bom_or_sig_available,
|
||||||
|
strip_sig_or_bom,
|
||||||
|
sig_payload,
|
||||||
|
is_multi_byte_decoder,
|
||||||
|
decoded_payload,
|
||||||
|
):
|
||||||
|
md_chunks.append(chunk)
|
||||||
|
|
||||||
|
md_ratios.append(
|
||||||
|
mess_ratio(
|
||||||
|
chunk,
|
||||||
|
threshold,
|
||||||
|
explain is True and 1 <= len(cp_isolation) <= 2,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if md_ratios[-1] >= threshold:
|
||||||
|
early_stop_count += 1
|
||||||
|
|
||||||
|
if (early_stop_count >= max_chunk_gave_up) or (
|
||||||
|
bom_or_sig_available and strip_sig_or_bom is False
|
||||||
|
):
|
||||||
|
break
|
||||||
|
except (
|
||||||
|
UnicodeDecodeError
|
||||||
|
) as e: # Lazy str loading may have missed something there
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"LazyStr Loading: After MD chunk decode, code page %s does not fit given bytes sequence at ALL. %s",
|
||||||
|
encoding_iana,
|
||||||
|
str(e),
|
||||||
|
)
|
||||||
|
early_stop_count = max_chunk_gave_up
|
||||||
|
lazy_str_hard_failure = True
|
||||||
|
|
||||||
|
# We might want to check the sequence again with the whole content
|
||||||
|
# Only if initial MD tests passes
|
||||||
|
if (
|
||||||
|
not lazy_str_hard_failure
|
||||||
|
and is_too_large_sequence
|
||||||
|
and not is_multi_byte_decoder
|
||||||
|
):
|
||||||
|
try:
|
||||||
|
sequences[int(50e3) :].decode(encoding_iana, errors="strict")
|
||||||
|
except UnicodeDecodeError as e:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"LazyStr Loading: After final lookup, code page %s does not fit given bytes sequence at ALL. %s",
|
||||||
|
encoding_iana,
|
||||||
|
str(e),
|
||||||
|
)
|
||||||
|
tested_but_hard_failure.append(encoding_iana)
|
||||||
|
continue
|
||||||
|
|
||||||
|
mean_mess_ratio: float = sum(md_ratios) / len(md_ratios) if md_ratios else 0.0
|
||||||
|
if mean_mess_ratio >= threshold or early_stop_count >= max_chunk_gave_up:
|
||||||
|
tested_but_soft_failure.append(encoding_iana)
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"%s was excluded because of initial chaos probing. Gave up %i time(s). "
|
||||||
|
"Computed mean chaos is %f %%.",
|
||||||
|
encoding_iana,
|
||||||
|
early_stop_count,
|
||||||
|
round(mean_mess_ratio * 100, ndigits=3),
|
||||||
|
)
|
||||||
|
# Preparing those fallbacks in case we got nothing.
|
||||||
|
if (
|
||||||
|
enable_fallback
|
||||||
|
and encoding_iana in ["ascii", "utf_8", specified_encoding]
|
||||||
|
and not lazy_str_hard_failure
|
||||||
|
):
|
||||||
|
fallback_entry = CharsetMatch(
|
||||||
|
sequences, encoding_iana, threshold, False, [], decoded_payload
|
||||||
|
)
|
||||||
|
if encoding_iana == specified_encoding:
|
||||||
|
fallback_specified = fallback_entry
|
||||||
|
elif encoding_iana == "ascii":
|
||||||
|
fallback_ascii = fallback_entry
|
||||||
|
else:
|
||||||
|
fallback_u8 = fallback_entry
|
||||||
|
continue
|
||||||
|
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"%s passed initial chaos probing. Mean measured chaos is %f %%",
|
||||||
|
encoding_iana,
|
||||||
|
round(mean_mess_ratio * 100, ndigits=3),
|
||||||
|
)
|
||||||
|
|
||||||
|
if not is_multi_byte_decoder:
|
||||||
|
target_languages: List[str] = encoding_languages(encoding_iana)
|
||||||
|
else:
|
||||||
|
target_languages = mb_encoding_languages(encoding_iana)
|
||||||
|
|
||||||
|
if target_languages:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"{} should target any language(s) of {}".format(
|
||||||
|
encoding_iana, str(target_languages)
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
cd_ratios = []
|
||||||
|
|
||||||
|
# We shall skip the CD when its about ASCII
|
||||||
|
# Most of the time its not relevant to run "language-detection" on it.
|
||||||
|
if encoding_iana != "ascii":
|
||||||
|
for chunk in md_chunks:
|
||||||
|
chunk_languages = coherence_ratio(
|
||||||
|
chunk,
|
||||||
|
language_threshold,
|
||||||
|
",".join(target_languages) if target_languages else None,
|
||||||
|
)
|
||||||
|
|
||||||
|
cd_ratios.append(chunk_languages)
|
||||||
|
|
||||||
|
cd_ratios_merged = merge_coherence_ratios(cd_ratios)
|
||||||
|
|
||||||
|
if cd_ratios_merged:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"We detected language {} using {}".format(
|
||||||
|
cd_ratios_merged, encoding_iana
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
results.append(
|
||||||
|
CharsetMatch(
|
||||||
|
sequences,
|
||||||
|
encoding_iana,
|
||||||
|
mean_mess_ratio,
|
||||||
|
bom_or_sig_available,
|
||||||
|
cd_ratios_merged,
|
||||||
|
decoded_payload,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if (
|
||||||
|
encoding_iana in [specified_encoding, "ascii", "utf_8"]
|
||||||
|
and mean_mess_ratio < 0.1
|
||||||
|
):
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: %s is most likely the one.", encoding_iana
|
||||||
|
)
|
||||||
|
if explain:
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level)
|
||||||
|
return CharsetMatches([results[encoding_iana]])
|
||||||
|
|
||||||
|
if encoding_iana == sig_encoding:
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: %s is most likely the one as we detected a BOM or SIG within "
|
||||||
|
"the beginning of the sequence.",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
if explain:
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level)
|
||||||
|
return CharsetMatches([results[encoding_iana]])
|
||||||
|
|
||||||
|
if len(results) == 0:
|
||||||
|
if fallback_u8 or fallback_ascii or fallback_specified:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Nothing got out of the detection process. Using ASCII/UTF-8/Specified fallback.",
|
||||||
|
)
|
||||||
|
|
||||||
|
if fallback_specified:
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: %s will be used as a fallback match",
|
||||||
|
fallback_specified.encoding,
|
||||||
|
)
|
||||||
|
results.append(fallback_specified)
|
||||||
|
elif (
|
||||||
|
(fallback_u8 and fallback_ascii is None)
|
||||||
|
or (
|
||||||
|
fallback_u8
|
||||||
|
and fallback_ascii
|
||||||
|
and fallback_u8.fingerprint != fallback_ascii.fingerprint
|
||||||
|
)
|
||||||
|
or (fallback_u8 is not None)
|
||||||
|
):
|
||||||
|
logger.debug("Encoding detection: utf_8 will be used as a fallback match")
|
||||||
|
results.append(fallback_u8)
|
||||||
|
elif fallback_ascii:
|
||||||
|
logger.debug("Encoding detection: ascii will be used as a fallback match")
|
||||||
|
results.append(fallback_ascii)
|
||||||
|
|
||||||
|
if results:
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: Found %s as plausible (best-candidate) for content. With %i alternatives.",
|
||||||
|
results.best().encoding, # type: ignore
|
||||||
|
len(results) - 1,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
logger.debug("Encoding detection: Unable to determine any suitable charset.")
|
||||||
|
|
||||||
|
if explain:
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level)
|
||||||
|
|
||||||
|
return results
|
||||||
|
|
||||||
|
|
||||||
|
def from_fp(
|
||||||
|
fp: BinaryIO,
|
||||||
|
steps: int = 5,
|
||||||
|
chunk_size: int = 512,
|
||||||
|
threshold: float = 0.20,
|
||||||
|
cp_isolation: Optional[List[str]] = None,
|
||||||
|
cp_exclusion: Optional[List[str]] = None,
|
||||||
|
preemptive_behaviour: bool = True,
|
||||||
|
explain: bool = False,
|
||||||
|
language_threshold: float = 0.1,
|
||||||
|
enable_fallback: bool = True,
|
||||||
|
) -> CharsetMatches:
|
||||||
|
"""
|
||||||
|
Same thing than the function from_bytes but using a file pointer that is already ready.
|
||||||
|
Will not close the file pointer.
|
||||||
|
"""
|
||||||
|
return from_bytes(
|
||||||
|
fp.read(),
|
||||||
|
steps,
|
||||||
|
chunk_size,
|
||||||
|
threshold,
|
||||||
|
cp_isolation,
|
||||||
|
cp_exclusion,
|
||||||
|
preemptive_behaviour,
|
||||||
|
explain,
|
||||||
|
language_threshold,
|
||||||
|
enable_fallback,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def from_path(
|
||||||
|
path: Union[str, bytes, PathLike], # type: ignore[type-arg]
|
||||||
|
steps: int = 5,
|
||||||
|
chunk_size: int = 512,
|
||||||
|
threshold: float = 0.20,
|
||||||
|
cp_isolation: Optional[List[str]] = None,
|
||||||
|
cp_exclusion: Optional[List[str]] = None,
|
||||||
|
preemptive_behaviour: bool = True,
|
||||||
|
explain: bool = False,
|
||||||
|
language_threshold: float = 0.1,
|
||||||
|
enable_fallback: bool = True,
|
||||||
|
) -> CharsetMatches:
|
||||||
|
"""
|
||||||
|
Same thing than the function from_bytes but with one extra step. Opening and reading given file path in binary mode.
|
||||||
|
Can raise IOError.
|
||||||
|
"""
|
||||||
|
with open(path, "rb") as fp:
|
||||||
|
return from_fp(
|
||||||
|
fp,
|
||||||
|
steps,
|
||||||
|
chunk_size,
|
||||||
|
threshold,
|
||||||
|
cp_isolation,
|
||||||
|
cp_exclusion,
|
||||||
|
preemptive_behaviour,
|
||||||
|
explain,
|
||||||
|
language_threshold,
|
||||||
|
enable_fallback,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def is_binary(
|
||||||
|
fp_or_path_or_payload: Union[PathLike, str, BinaryIO, bytes], # type: ignore[type-arg]
|
||||||
|
steps: int = 5,
|
||||||
|
chunk_size: int = 512,
|
||||||
|
threshold: float = 0.20,
|
||||||
|
cp_isolation: Optional[List[str]] = None,
|
||||||
|
cp_exclusion: Optional[List[str]] = None,
|
||||||
|
preemptive_behaviour: bool = True,
|
||||||
|
explain: bool = False,
|
||||||
|
language_threshold: float = 0.1,
|
||||||
|
enable_fallback: bool = False,
|
||||||
|
) -> bool:
|
||||||
|
"""
|
||||||
|
Detect if the given input (file, bytes, or path) points to a binary file. aka. not a string.
|
||||||
|
Based on the same main heuristic algorithms and default kwargs at the sole exception that fallbacks match
|
||||||
|
are disabled to be stricter around ASCII-compatible but unlikely to be a string.
|
||||||
|
"""
|
||||||
|
if isinstance(fp_or_path_or_payload, (str, PathLike)):
|
||||||
|
guesses = from_path(
|
||||||
|
fp_or_path_or_payload,
|
||||||
|
steps=steps,
|
||||||
|
chunk_size=chunk_size,
|
||||||
|
threshold=threshold,
|
||||||
|
cp_isolation=cp_isolation,
|
||||||
|
cp_exclusion=cp_exclusion,
|
||||||
|
preemptive_behaviour=preemptive_behaviour,
|
||||||
|
explain=explain,
|
||||||
|
language_threshold=language_threshold,
|
||||||
|
enable_fallback=enable_fallback,
|
||||||
|
)
|
||||||
|
elif isinstance(
|
||||||
|
fp_or_path_or_payload,
|
||||||
|
(
|
||||||
|
bytes,
|
||||||
|
bytearray,
|
||||||
|
),
|
||||||
|
):
|
||||||
|
guesses = from_bytes(
|
||||||
|
fp_or_path_or_payload,
|
||||||
|
steps=steps,
|
||||||
|
chunk_size=chunk_size,
|
||||||
|
threshold=threshold,
|
||||||
|
cp_isolation=cp_isolation,
|
||||||
|
cp_exclusion=cp_exclusion,
|
||||||
|
preemptive_behaviour=preemptive_behaviour,
|
||||||
|
explain=explain,
|
||||||
|
language_threshold=language_threshold,
|
||||||
|
enable_fallback=enable_fallback,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
guesses = from_fp(
|
||||||
|
fp_or_path_or_payload,
|
||||||
|
steps=steps,
|
||||||
|
chunk_size=chunk_size,
|
||||||
|
threshold=threshold,
|
||||||
|
cp_isolation=cp_isolation,
|
||||||
|
cp_exclusion=cp_exclusion,
|
||||||
|
preemptive_behaviour=preemptive_behaviour,
|
||||||
|
explain=explain,
|
||||||
|
language_threshold=language_threshold,
|
||||||
|
enable_fallback=enable_fallback,
|
||||||
|
)
|
||||||
|
|
||||||
|
return not guesses
|
||||||
|
|
@ -0,0 +1,395 @@
|
||||||
|
import importlib
|
||||||
|
from codecs import IncrementalDecoder
|
||||||
|
from collections import Counter
|
||||||
|
from functools import lru_cache
|
||||||
|
from typing import Counter as TypeCounter, Dict, List, Optional, Tuple
|
||||||
|
|
||||||
|
from .constant import (
|
||||||
|
FREQUENCIES,
|
||||||
|
KO_NAMES,
|
||||||
|
LANGUAGE_SUPPORTED_COUNT,
|
||||||
|
TOO_SMALL_SEQUENCE,
|
||||||
|
ZH_NAMES,
|
||||||
|
)
|
||||||
|
from .md import is_suspiciously_successive_range
|
||||||
|
from .models import CoherenceMatches
|
||||||
|
from .utils import (
|
||||||
|
is_accentuated,
|
||||||
|
is_latin,
|
||||||
|
is_multi_byte_encoding,
|
||||||
|
is_unicode_range_secondary,
|
||||||
|
unicode_range,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def encoding_unicode_range(iana_name: str) -> List[str]:
|
||||||
|
"""
|
||||||
|
Return associated unicode ranges in a single byte code page.
|
||||||
|
"""
|
||||||
|
if is_multi_byte_encoding(iana_name):
|
||||||
|
raise IOError("Function not supported on multi-byte code page")
|
||||||
|
|
||||||
|
decoder = importlib.import_module(
|
||||||
|
"encodings.{}".format(iana_name)
|
||||||
|
).IncrementalDecoder
|
||||||
|
|
||||||
|
p: IncrementalDecoder = decoder(errors="ignore")
|
||||||
|
seen_ranges: Dict[str, int] = {}
|
||||||
|
character_count: int = 0
|
||||||
|
|
||||||
|
for i in range(0x40, 0xFF):
|
||||||
|
chunk: str = p.decode(bytes([i]))
|
||||||
|
|
||||||
|
if chunk:
|
||||||
|
character_range: Optional[str] = unicode_range(chunk)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if is_unicode_range_secondary(character_range) is False:
|
||||||
|
if character_range not in seen_ranges:
|
||||||
|
seen_ranges[character_range] = 0
|
||||||
|
seen_ranges[character_range] += 1
|
||||||
|
character_count += 1
|
||||||
|
|
||||||
|
return sorted(
|
||||||
|
[
|
||||||
|
character_range
|
||||||
|
for character_range in seen_ranges
|
||||||
|
if seen_ranges[character_range] / character_count >= 0.15
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def unicode_range_languages(primary_range: str) -> List[str]:
|
||||||
|
"""
|
||||||
|
Return inferred languages used with a unicode range.
|
||||||
|
"""
|
||||||
|
languages: List[str] = []
|
||||||
|
|
||||||
|
for language, characters in FREQUENCIES.items():
|
||||||
|
for character in characters:
|
||||||
|
if unicode_range(character) == primary_range:
|
||||||
|
languages.append(language)
|
||||||
|
break
|
||||||
|
|
||||||
|
return languages
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache()
|
||||||
|
def encoding_languages(iana_name: str) -> List[str]:
|
||||||
|
"""
|
||||||
|
Single-byte encoding language association. Some code page are heavily linked to particular language(s).
|
||||||
|
This function does the correspondence.
|
||||||
|
"""
|
||||||
|
unicode_ranges: List[str] = encoding_unicode_range(iana_name)
|
||||||
|
primary_range: Optional[str] = None
|
||||||
|
|
||||||
|
for specified_range in unicode_ranges:
|
||||||
|
if "Latin" not in specified_range:
|
||||||
|
primary_range = specified_range
|
||||||
|
break
|
||||||
|
|
||||||
|
if primary_range is None:
|
||||||
|
return ["Latin Based"]
|
||||||
|
|
||||||
|
return unicode_range_languages(primary_range)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache()
|
||||||
|
def mb_encoding_languages(iana_name: str) -> List[str]:
|
||||||
|
"""
|
||||||
|
Multi-byte encoding language association. Some code page are heavily linked to particular language(s).
|
||||||
|
This function does the correspondence.
|
||||||
|
"""
|
||||||
|
if (
|
||||||
|
iana_name.startswith("shift_")
|
||||||
|
or iana_name.startswith("iso2022_jp")
|
||||||
|
or iana_name.startswith("euc_j")
|
||||||
|
or iana_name == "cp932"
|
||||||
|
):
|
||||||
|
return ["Japanese"]
|
||||||
|
if iana_name.startswith("gb") or iana_name in ZH_NAMES:
|
||||||
|
return ["Chinese"]
|
||||||
|
if iana_name.startswith("iso2022_kr") or iana_name in KO_NAMES:
|
||||||
|
return ["Korean"]
|
||||||
|
|
||||||
|
return []
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=LANGUAGE_SUPPORTED_COUNT)
|
||||||
|
def get_target_features(language: str) -> Tuple[bool, bool]:
|
||||||
|
"""
|
||||||
|
Determine main aspects from a supported language if it contains accents and if is pure Latin.
|
||||||
|
"""
|
||||||
|
target_have_accents: bool = False
|
||||||
|
target_pure_latin: bool = True
|
||||||
|
|
||||||
|
for character in FREQUENCIES[language]:
|
||||||
|
if not target_have_accents and is_accentuated(character):
|
||||||
|
target_have_accents = True
|
||||||
|
if target_pure_latin and is_latin(character) is False:
|
||||||
|
target_pure_latin = False
|
||||||
|
|
||||||
|
return target_have_accents, target_pure_latin
|
||||||
|
|
||||||
|
|
||||||
|
def alphabet_languages(
|
||||||
|
characters: List[str], ignore_non_latin: bool = False
|
||||||
|
) -> List[str]:
|
||||||
|
"""
|
||||||
|
Return associated languages associated to given characters.
|
||||||
|
"""
|
||||||
|
languages: List[Tuple[str, float]] = []
|
||||||
|
|
||||||
|
source_have_accents = any(is_accentuated(character) for character in characters)
|
||||||
|
|
||||||
|
for language, language_characters in FREQUENCIES.items():
|
||||||
|
target_have_accents, target_pure_latin = get_target_features(language)
|
||||||
|
|
||||||
|
if ignore_non_latin and target_pure_latin is False:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if target_have_accents is False and source_have_accents:
|
||||||
|
continue
|
||||||
|
|
||||||
|
character_count: int = len(language_characters)
|
||||||
|
|
||||||
|
character_match_count: int = len(
|
||||||
|
[c for c in language_characters if c in characters]
|
||||||
|
)
|
||||||
|
|
||||||
|
ratio: float = character_match_count / character_count
|
||||||
|
|
||||||
|
if ratio >= 0.2:
|
||||||
|
languages.append((language, ratio))
|
||||||
|
|
||||||
|
languages = sorted(languages, key=lambda x: x[1], reverse=True)
|
||||||
|
|
||||||
|
return [compatible_language[0] for compatible_language in languages]
|
||||||
|
|
||||||
|
|
||||||
|
def characters_popularity_compare(
|
||||||
|
language: str, ordered_characters: List[str]
|
||||||
|
) -> float:
|
||||||
|
"""
|
||||||
|
Determine if a ordered characters list (by occurrence from most appearance to rarest) match a particular language.
|
||||||
|
The result is a ratio between 0. (absolutely no correspondence) and 1. (near perfect fit).
|
||||||
|
Beware that is function is not strict on the match in order to ease the detection. (Meaning close match is 1.)
|
||||||
|
"""
|
||||||
|
if language not in FREQUENCIES:
|
||||||
|
raise ValueError("{} not available".format(language))
|
||||||
|
|
||||||
|
character_approved_count: int = 0
|
||||||
|
FREQUENCIES_language_set = set(FREQUENCIES[language])
|
||||||
|
|
||||||
|
ordered_characters_count: int = len(ordered_characters)
|
||||||
|
target_language_characters_count: int = len(FREQUENCIES[language])
|
||||||
|
|
||||||
|
large_alphabet: bool = target_language_characters_count > 26
|
||||||
|
|
||||||
|
for character, character_rank in zip(
|
||||||
|
ordered_characters, range(0, ordered_characters_count)
|
||||||
|
):
|
||||||
|
if character not in FREQUENCIES_language_set:
|
||||||
|
continue
|
||||||
|
|
||||||
|
character_rank_in_language: int = FREQUENCIES[language].index(character)
|
||||||
|
expected_projection_ratio: float = (
|
||||||
|
target_language_characters_count / ordered_characters_count
|
||||||
|
)
|
||||||
|
character_rank_projection: int = int(character_rank * expected_projection_ratio)
|
||||||
|
|
||||||
|
if (
|
||||||
|
large_alphabet is False
|
||||||
|
and abs(character_rank_projection - character_rank_in_language) > 4
|
||||||
|
):
|
||||||
|
continue
|
||||||
|
|
||||||
|
if (
|
||||||
|
large_alphabet is True
|
||||||
|
and abs(character_rank_projection - character_rank_in_language)
|
||||||
|
< target_language_characters_count / 3
|
||||||
|
):
|
||||||
|
character_approved_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
characters_before_source: List[str] = FREQUENCIES[language][
|
||||||
|
0:character_rank_in_language
|
||||||
|
]
|
||||||
|
characters_after_source: List[str] = FREQUENCIES[language][
|
||||||
|
character_rank_in_language:
|
||||||
|
]
|
||||||
|
characters_before: List[str] = ordered_characters[0:character_rank]
|
||||||
|
characters_after: List[str] = ordered_characters[character_rank:]
|
||||||
|
|
||||||
|
before_match_count: int = len(
|
||||||
|
set(characters_before) & set(characters_before_source)
|
||||||
|
)
|
||||||
|
|
||||||
|
after_match_count: int = len(
|
||||||
|
set(characters_after) & set(characters_after_source)
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(characters_before_source) == 0 and before_match_count <= 4:
|
||||||
|
character_approved_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
if len(characters_after_source) == 0 and after_match_count <= 4:
|
||||||
|
character_approved_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
if (
|
||||||
|
before_match_count / len(characters_before_source) >= 0.4
|
||||||
|
or after_match_count / len(characters_after_source) >= 0.4
|
||||||
|
):
|
||||||
|
character_approved_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
return character_approved_count / len(ordered_characters)
|
||||||
|
|
||||||
|
|
||||||
|
def alpha_unicode_split(decoded_sequence: str) -> List[str]:
|
||||||
|
"""
|
||||||
|
Given a decoded text sequence, return a list of str. Unicode range / alphabet separation.
|
||||||
|
Ex. a text containing English/Latin with a bit a Hebrew will return two items in the resulting list;
|
||||||
|
One containing the latin letters and the other hebrew.
|
||||||
|
"""
|
||||||
|
layers: Dict[str, str] = {}
|
||||||
|
|
||||||
|
for character in decoded_sequence:
|
||||||
|
if character.isalpha() is False:
|
||||||
|
continue
|
||||||
|
|
||||||
|
character_range: Optional[str] = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
continue
|
||||||
|
|
||||||
|
layer_target_range: Optional[str] = None
|
||||||
|
|
||||||
|
for discovered_range in layers:
|
||||||
|
if (
|
||||||
|
is_suspiciously_successive_range(discovered_range, character_range)
|
||||||
|
is False
|
||||||
|
):
|
||||||
|
layer_target_range = discovered_range
|
||||||
|
break
|
||||||
|
|
||||||
|
if layer_target_range is None:
|
||||||
|
layer_target_range = character_range
|
||||||
|
|
||||||
|
if layer_target_range not in layers:
|
||||||
|
layers[layer_target_range] = character.lower()
|
||||||
|
continue
|
||||||
|
|
||||||
|
layers[layer_target_range] += character.lower()
|
||||||
|
|
||||||
|
return list(layers.values())
|
||||||
|
|
||||||
|
|
||||||
|
def merge_coherence_ratios(results: List[CoherenceMatches]) -> CoherenceMatches:
|
||||||
|
"""
|
||||||
|
This function merge results previously given by the function coherence_ratio.
|
||||||
|
The return type is the same as coherence_ratio.
|
||||||
|
"""
|
||||||
|
per_language_ratios: Dict[str, List[float]] = {}
|
||||||
|
for result in results:
|
||||||
|
for sub_result in result:
|
||||||
|
language, ratio = sub_result
|
||||||
|
if language not in per_language_ratios:
|
||||||
|
per_language_ratios[language] = [ratio]
|
||||||
|
continue
|
||||||
|
per_language_ratios[language].append(ratio)
|
||||||
|
|
||||||
|
merge = [
|
||||||
|
(
|
||||||
|
language,
|
||||||
|
round(
|
||||||
|
sum(per_language_ratios[language]) / len(per_language_ratios[language]),
|
||||||
|
4,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
for language in per_language_ratios
|
||||||
|
]
|
||||||
|
|
||||||
|
return sorted(merge, key=lambda x: x[1], reverse=True)
|
||||||
|
|
||||||
|
|
||||||
|
def filter_alt_coherence_matches(results: CoherenceMatches) -> CoherenceMatches:
|
||||||
|
"""
|
||||||
|
We shall NOT return "English—" in CoherenceMatches because it is an alternative
|
||||||
|
of "English". This function only keeps the best match and remove the em-dash in it.
|
||||||
|
"""
|
||||||
|
index_results: Dict[str, List[float]] = dict()
|
||||||
|
|
||||||
|
for result in results:
|
||||||
|
language, ratio = result
|
||||||
|
no_em_name: str = language.replace("—", "")
|
||||||
|
|
||||||
|
if no_em_name not in index_results:
|
||||||
|
index_results[no_em_name] = []
|
||||||
|
|
||||||
|
index_results[no_em_name].append(ratio)
|
||||||
|
|
||||||
|
if any(len(index_results[e]) > 1 for e in index_results):
|
||||||
|
filtered_results: CoherenceMatches = []
|
||||||
|
|
||||||
|
for language in index_results:
|
||||||
|
filtered_results.append((language, max(index_results[language])))
|
||||||
|
|
||||||
|
return filtered_results
|
||||||
|
|
||||||
|
return results
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=2048)
|
||||||
|
def coherence_ratio(
|
||||||
|
decoded_sequence: str, threshold: float = 0.1, lg_inclusion: Optional[str] = None
|
||||||
|
) -> CoherenceMatches:
|
||||||
|
"""
|
||||||
|
Detect ANY language that can be identified in given sequence. The sequence will be analysed by layers.
|
||||||
|
A layer = Character extraction by alphabets/ranges.
|
||||||
|
"""
|
||||||
|
|
||||||
|
results: List[Tuple[str, float]] = []
|
||||||
|
ignore_non_latin: bool = False
|
||||||
|
|
||||||
|
sufficient_match_count: int = 0
|
||||||
|
|
||||||
|
lg_inclusion_list = lg_inclusion.split(",") if lg_inclusion is not None else []
|
||||||
|
if "Latin Based" in lg_inclusion_list:
|
||||||
|
ignore_non_latin = True
|
||||||
|
lg_inclusion_list.remove("Latin Based")
|
||||||
|
|
||||||
|
for layer in alpha_unicode_split(decoded_sequence):
|
||||||
|
sequence_frequencies: TypeCounter[str] = Counter(layer)
|
||||||
|
most_common = sequence_frequencies.most_common()
|
||||||
|
|
||||||
|
character_count: int = sum(o for c, o in most_common)
|
||||||
|
|
||||||
|
if character_count <= TOO_SMALL_SEQUENCE:
|
||||||
|
continue
|
||||||
|
|
||||||
|
popular_character_ordered: List[str] = [c for c, o in most_common]
|
||||||
|
|
||||||
|
for language in lg_inclusion_list or alphabet_languages(
|
||||||
|
popular_character_ordered, ignore_non_latin
|
||||||
|
):
|
||||||
|
ratio: float = characters_popularity_compare(
|
||||||
|
language, popular_character_ordered
|
||||||
|
)
|
||||||
|
|
||||||
|
if ratio < threshold:
|
||||||
|
continue
|
||||||
|
elif ratio >= 0.8:
|
||||||
|
sufficient_match_count += 1
|
||||||
|
|
||||||
|
results.append((language, round(ratio, 4)))
|
||||||
|
|
||||||
|
if sufficient_match_count >= 3:
|
||||||
|
break
|
||||||
|
|
||||||
|
return sorted(
|
||||||
|
filter_alt_coherence_matches(results), key=lambda x: x[1], reverse=True
|
||||||
|
)
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
from .__main__ import cli_detect, query_yes_no
|
||||||
|
|
||||||
|
__all__ = (
|
||||||
|
"cli_detect",
|
||||||
|
"query_yes_no",
|
||||||
|
)
|
||||||
|
|
@ -0,0 +1,296 @@
|
||||||
|
import argparse
|
||||||
|
import sys
|
||||||
|
from json import dumps
|
||||||
|
from os.path import abspath, basename, dirname, join, realpath
|
||||||
|
from platform import python_version
|
||||||
|
from typing import List, Optional
|
||||||
|
from unicodedata import unidata_version
|
||||||
|
|
||||||
|
import charset_normalizer.md as md_module
|
||||||
|
from charset_normalizer import from_fp
|
||||||
|
from charset_normalizer.models import CliDetectionResult
|
||||||
|
from charset_normalizer.version import __version__
|
||||||
|
|
||||||
|
|
||||||
|
def query_yes_no(question: str, default: str = "yes") -> bool:
|
||||||
|
"""Ask a yes/no question via input() and return their answer.
|
||||||
|
|
||||||
|
"question" is a string that is presented to the user.
|
||||||
|
"default" is the presumed answer if the user just hits <Enter>.
|
||||||
|
It must be "yes" (the default), "no" or None (meaning
|
||||||
|
an answer is required of the user).
|
||||||
|
|
||||||
|
The "answer" return value is True for "yes" or False for "no".
|
||||||
|
|
||||||
|
Credit goes to (c) https://stackoverflow.com/questions/3041986/apt-command-line-interface-like-yes-no-input
|
||||||
|
"""
|
||||||
|
valid = {"yes": True, "y": True, "ye": True, "no": False, "n": False}
|
||||||
|
if default is None:
|
||||||
|
prompt = " [y/n] "
|
||||||
|
elif default == "yes":
|
||||||
|
prompt = " [Y/n] "
|
||||||
|
elif default == "no":
|
||||||
|
prompt = " [y/N] "
|
||||||
|
else:
|
||||||
|
raise ValueError("invalid default answer: '%s'" % default)
|
||||||
|
|
||||||
|
while True:
|
||||||
|
sys.stdout.write(question + prompt)
|
||||||
|
choice = input().lower()
|
||||||
|
if default is not None and choice == "":
|
||||||
|
return valid[default]
|
||||||
|
elif choice in valid:
|
||||||
|
return valid[choice]
|
||||||
|
else:
|
||||||
|
sys.stdout.write("Please respond with 'yes' or 'no' " "(or 'y' or 'n').\n")
|
||||||
|
|
||||||
|
|
||||||
|
def cli_detect(argv: Optional[List[str]] = None) -> int:
|
||||||
|
"""
|
||||||
|
CLI assistant using ARGV and ArgumentParser
|
||||||
|
:param argv:
|
||||||
|
:return: 0 if everything is fine, anything else equal trouble
|
||||||
|
"""
|
||||||
|
parser = argparse.ArgumentParser(
|
||||||
|
description="The Real First Universal Charset Detector. "
|
||||||
|
"Discover originating encoding used on text file. "
|
||||||
|
"Normalize text to unicode."
|
||||||
|
)
|
||||||
|
|
||||||
|
parser.add_argument(
|
||||||
|
"files", type=argparse.FileType("rb"), nargs="+", help="File(s) to be analysed"
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-v",
|
||||||
|
"--verbose",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="verbose",
|
||||||
|
help="Display complementary information about file if any. "
|
||||||
|
"Stdout will contain logs about the detection process.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-a",
|
||||||
|
"--with-alternative",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="alternatives",
|
||||||
|
help="Output complementary possibilities if any. Top-level JSON WILL be a list.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-n",
|
||||||
|
"--normalize",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="normalize",
|
||||||
|
help="Permit to normalize input file. If not set, program does not write anything.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-m",
|
||||||
|
"--minimal",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="minimal",
|
||||||
|
help="Only output the charset detected to STDOUT. Disabling JSON output.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-r",
|
||||||
|
"--replace",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="replace",
|
||||||
|
help="Replace file when trying to normalize it instead of creating a new one.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-f",
|
||||||
|
"--force",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="force",
|
||||||
|
help="Replace file without asking if you are sure, use this flag with caution.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-t",
|
||||||
|
"--threshold",
|
||||||
|
action="store",
|
||||||
|
default=0.2,
|
||||||
|
type=float,
|
||||||
|
dest="threshold",
|
||||||
|
help="Define a custom maximum amount of chaos allowed in decoded content. 0. <= chaos <= 1.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--version",
|
||||||
|
action="version",
|
||||||
|
version="Charset-Normalizer {} - Python {} - Unicode {} - SpeedUp {}".format(
|
||||||
|
__version__,
|
||||||
|
python_version(),
|
||||||
|
unidata_version,
|
||||||
|
"OFF" if md_module.__file__.lower().endswith(".py") else "ON",
|
||||||
|
),
|
||||||
|
help="Show version information and exit.",
|
||||||
|
)
|
||||||
|
|
||||||
|
args = parser.parse_args(argv)
|
||||||
|
|
||||||
|
if args.replace is True and args.normalize is False:
|
||||||
|
print("Use --replace in addition of --normalize only.", file=sys.stderr)
|
||||||
|
return 1
|
||||||
|
|
||||||
|
if args.force is True and args.replace is False:
|
||||||
|
print("Use --force in addition of --replace only.", file=sys.stderr)
|
||||||
|
return 1
|
||||||
|
|
||||||
|
if args.threshold < 0.0 or args.threshold > 1.0:
|
||||||
|
print("--threshold VALUE should be between 0. AND 1.", file=sys.stderr)
|
||||||
|
return 1
|
||||||
|
|
||||||
|
x_ = []
|
||||||
|
|
||||||
|
for my_file in args.files:
|
||||||
|
matches = from_fp(my_file, threshold=args.threshold, explain=args.verbose)
|
||||||
|
|
||||||
|
best_guess = matches.best()
|
||||||
|
|
||||||
|
if best_guess is None:
|
||||||
|
print(
|
||||||
|
'Unable to identify originating encoding for "{}". {}'.format(
|
||||||
|
my_file.name,
|
||||||
|
"Maybe try increasing maximum amount of chaos."
|
||||||
|
if args.threshold < 1.0
|
||||||
|
else "",
|
||||||
|
),
|
||||||
|
file=sys.stderr,
|
||||||
|
)
|
||||||
|
x_.append(
|
||||||
|
CliDetectionResult(
|
||||||
|
abspath(my_file.name),
|
||||||
|
None,
|
||||||
|
[],
|
||||||
|
[],
|
||||||
|
"Unknown",
|
||||||
|
[],
|
||||||
|
False,
|
||||||
|
1.0,
|
||||||
|
0.0,
|
||||||
|
None,
|
||||||
|
True,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
x_.append(
|
||||||
|
CliDetectionResult(
|
||||||
|
abspath(my_file.name),
|
||||||
|
best_guess.encoding,
|
||||||
|
best_guess.encoding_aliases,
|
||||||
|
[
|
||||||
|
cp
|
||||||
|
for cp in best_guess.could_be_from_charset
|
||||||
|
if cp != best_guess.encoding
|
||||||
|
],
|
||||||
|
best_guess.language,
|
||||||
|
best_guess.alphabets,
|
||||||
|
best_guess.bom,
|
||||||
|
best_guess.percent_chaos,
|
||||||
|
best_guess.percent_coherence,
|
||||||
|
None,
|
||||||
|
True,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(matches) > 1 and args.alternatives:
|
||||||
|
for el in matches:
|
||||||
|
if el != best_guess:
|
||||||
|
x_.append(
|
||||||
|
CliDetectionResult(
|
||||||
|
abspath(my_file.name),
|
||||||
|
el.encoding,
|
||||||
|
el.encoding_aliases,
|
||||||
|
[
|
||||||
|
cp
|
||||||
|
for cp in el.could_be_from_charset
|
||||||
|
if cp != el.encoding
|
||||||
|
],
|
||||||
|
el.language,
|
||||||
|
el.alphabets,
|
||||||
|
el.bom,
|
||||||
|
el.percent_chaos,
|
||||||
|
el.percent_coherence,
|
||||||
|
None,
|
||||||
|
False,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if args.normalize is True:
|
||||||
|
if best_guess.encoding.startswith("utf") is True:
|
||||||
|
print(
|
||||||
|
'"{}" file does not need to be normalized, as it already came from unicode.'.format(
|
||||||
|
my_file.name
|
||||||
|
),
|
||||||
|
file=sys.stderr,
|
||||||
|
)
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
continue
|
||||||
|
|
||||||
|
dir_path = dirname(realpath(my_file.name))
|
||||||
|
file_name = basename(realpath(my_file.name))
|
||||||
|
|
||||||
|
o_: List[str] = file_name.split(".")
|
||||||
|
|
||||||
|
if args.replace is False:
|
||||||
|
o_.insert(-1, best_guess.encoding)
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
elif (
|
||||||
|
args.force is False
|
||||||
|
and query_yes_no(
|
||||||
|
'Are you sure to normalize "{}" by replacing it ?'.format(
|
||||||
|
my_file.name
|
||||||
|
),
|
||||||
|
"no",
|
||||||
|
)
|
||||||
|
is False
|
||||||
|
):
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
x_[0].unicode_path = join(dir_path, ".".join(o_))
|
||||||
|
|
||||||
|
with open(x_[0].unicode_path, "w", encoding="utf-8") as fp:
|
||||||
|
fp.write(str(best_guess))
|
||||||
|
except IOError as e:
|
||||||
|
print(str(e), file=sys.stderr)
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
return 2
|
||||||
|
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
|
||||||
|
if args.minimal is False:
|
||||||
|
print(
|
||||||
|
dumps(
|
||||||
|
[el.__dict__ for el in x_] if len(x_) > 1 else x_[0].__dict__,
|
||||||
|
ensure_ascii=True,
|
||||||
|
indent=4,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
for my_file in args.files:
|
||||||
|
print(
|
||||||
|
", ".join(
|
||||||
|
[
|
||||||
|
el.encoding or "undefined"
|
||||||
|
for el in x_
|
||||||
|
if el.path == abspath(my_file.name)
|
||||||
|
]
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
return 0
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
cli_detect()
|
||||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,54 @@
|
||||||
|
from typing import Any, Dict, Optional, Union
|
||||||
|
from warnings import warn
|
||||||
|
|
||||||
|
from .api import from_bytes
|
||||||
|
from .constant import CHARDET_CORRESPONDENCE
|
||||||
|
|
||||||
|
|
||||||
|
def detect(
|
||||||
|
byte_str: bytes, should_rename_legacy: bool = False, **kwargs: Any
|
||||||
|
) -> Dict[str, Optional[Union[str, float]]]:
|
||||||
|
"""
|
||||||
|
chardet legacy method
|
||||||
|
Detect the encoding of the given byte string. It should be mostly backward-compatible.
|
||||||
|
Encoding name will match Chardet own writing whenever possible. (Not on encoding name unsupported by it)
|
||||||
|
This function is deprecated and should be used to migrate your project easily, consult the documentation for
|
||||||
|
further information. Not planned for removal.
|
||||||
|
|
||||||
|
:param byte_str: The byte sequence to examine.
|
||||||
|
:param should_rename_legacy: Should we rename legacy encodings
|
||||||
|
to their more modern equivalents?
|
||||||
|
"""
|
||||||
|
if len(kwargs):
|
||||||
|
warn(
|
||||||
|
f"charset-normalizer disregard arguments '{','.join(list(kwargs.keys()))}' in legacy function detect()"
|
||||||
|
)
|
||||||
|
|
||||||
|
if not isinstance(byte_str, (bytearray, bytes)):
|
||||||
|
raise TypeError( # pragma: nocover
|
||||||
|
"Expected object of type bytes or bytearray, got: "
|
||||||
|
"{0}".format(type(byte_str))
|
||||||
|
)
|
||||||
|
|
||||||
|
if isinstance(byte_str, bytearray):
|
||||||
|
byte_str = bytes(byte_str)
|
||||||
|
|
||||||
|
r = from_bytes(byte_str).best()
|
||||||
|
|
||||||
|
encoding = r.encoding if r is not None else None
|
||||||
|
language = r.language if r is not None and r.language != "Unknown" else ""
|
||||||
|
confidence = 1.0 - r.chaos if r is not None else None
|
||||||
|
|
||||||
|
# Note: CharsetNormalizer does not return 'UTF-8-SIG' as the sig get stripped in the detection/normalization process
|
||||||
|
# but chardet does return 'utf-8-sig' and it is a valid codec name.
|
||||||
|
if r is not None and encoding == "utf_8" and r.bom:
|
||||||
|
encoding += "_sig"
|
||||||
|
|
||||||
|
if should_rename_legacy is False and encoding in CHARDET_CORRESPONDENCE:
|
||||||
|
encoding = CHARDET_CORRESPONDENCE[encoding]
|
||||||
|
|
||||||
|
return {
|
||||||
|
"encoding": encoding,
|
||||||
|
"language": language,
|
||||||
|
"confidence": confidence,
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1,615 @@
|
||||||
|
from functools import lru_cache
|
||||||
|
from logging import getLogger
|
||||||
|
from typing import List, Optional
|
||||||
|
|
||||||
|
from .constant import (
|
||||||
|
COMMON_SAFE_ASCII_CHARACTERS,
|
||||||
|
TRACE,
|
||||||
|
UNICODE_SECONDARY_RANGE_KEYWORD,
|
||||||
|
)
|
||||||
|
from .utils import (
|
||||||
|
is_accentuated,
|
||||||
|
is_arabic,
|
||||||
|
is_arabic_isolated_form,
|
||||||
|
is_case_variable,
|
||||||
|
is_cjk,
|
||||||
|
is_emoticon,
|
||||||
|
is_hangul,
|
||||||
|
is_hiragana,
|
||||||
|
is_katakana,
|
||||||
|
is_latin,
|
||||||
|
is_punctuation,
|
||||||
|
is_separator,
|
||||||
|
is_symbol,
|
||||||
|
is_thai,
|
||||||
|
is_unprintable,
|
||||||
|
remove_accent,
|
||||||
|
unicode_range,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class MessDetectorPlugin:
|
||||||
|
"""
|
||||||
|
Base abstract class used for mess detection plugins.
|
||||||
|
All detectors MUST extend and implement given methods.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
"""
|
||||||
|
Determine if given character should be fed in.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError # pragma: nocover
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
"""
|
||||||
|
The main routine to be executed upon character.
|
||||||
|
Insert the logic in witch the text would be considered chaotic.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError # pragma: nocover
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
"""
|
||||||
|
Permit to reset the plugin to the initial state.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
"""
|
||||||
|
Compute the chaos ratio based on what your feed() has seen.
|
||||||
|
Must NOT be lower than 0.; No restriction gt 0.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError # pragma: nocover
|
||||||
|
|
||||||
|
|
||||||
|
class TooManySymbolOrPunctuationPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._punctuation_count: int = 0
|
||||||
|
self._symbol_count: int = 0
|
||||||
|
self._character_count: int = 0
|
||||||
|
|
||||||
|
self._last_printable_char: Optional[str] = None
|
||||||
|
self._frenzy_symbol_in_word: bool = False
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return character.isprintable()
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if (
|
||||||
|
character != self._last_printable_char
|
||||||
|
and character not in COMMON_SAFE_ASCII_CHARACTERS
|
||||||
|
):
|
||||||
|
if is_punctuation(character):
|
||||||
|
self._punctuation_count += 1
|
||||||
|
elif (
|
||||||
|
character.isdigit() is False
|
||||||
|
and is_symbol(character)
|
||||||
|
and is_emoticon(character) is False
|
||||||
|
):
|
||||||
|
self._symbol_count += 2
|
||||||
|
|
||||||
|
self._last_printable_char = character
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._punctuation_count = 0
|
||||||
|
self._character_count = 0
|
||||||
|
self._symbol_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
ratio_of_punctuation: float = (
|
||||||
|
self._punctuation_count + self._symbol_count
|
||||||
|
) / self._character_count
|
||||||
|
|
||||||
|
return ratio_of_punctuation if ratio_of_punctuation >= 0.3 else 0.0
|
||||||
|
|
||||||
|
|
||||||
|
class TooManyAccentuatedPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._accentuated_count: int = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return character.isalpha()
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if is_accentuated(character):
|
||||||
|
self._accentuated_count += 1
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._character_count = 0
|
||||||
|
self._accentuated_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count < 8:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
ratio_of_accentuation: float = self._accentuated_count / self._character_count
|
||||||
|
return ratio_of_accentuation if ratio_of_accentuation >= 0.35 else 0.0
|
||||||
|
|
||||||
|
|
||||||
|
class UnprintablePlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._unprintable_count: int = 0
|
||||||
|
self._character_count: int = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
if is_unprintable(character):
|
||||||
|
self._unprintable_count += 1
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._unprintable_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
return (self._unprintable_count * 8) / self._character_count
|
||||||
|
|
||||||
|
|
||||||
|
class SuspiciousDuplicateAccentPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._successive_count: int = 0
|
||||||
|
self._character_count: int = 0
|
||||||
|
|
||||||
|
self._last_latin_character: Optional[str] = None
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return character.isalpha() and is_latin(character)
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
if (
|
||||||
|
self._last_latin_character is not None
|
||||||
|
and is_accentuated(character)
|
||||||
|
and is_accentuated(self._last_latin_character)
|
||||||
|
):
|
||||||
|
if character.isupper() and self._last_latin_character.isupper():
|
||||||
|
self._successive_count += 1
|
||||||
|
# Worse if its the same char duplicated with different accent.
|
||||||
|
if remove_accent(character) == remove_accent(self._last_latin_character):
|
||||||
|
self._successive_count += 1
|
||||||
|
self._last_latin_character = character
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._successive_count = 0
|
||||||
|
self._character_count = 0
|
||||||
|
self._last_latin_character = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
return (self._successive_count * 2) / self._character_count
|
||||||
|
|
||||||
|
|
||||||
|
class SuspiciousRange(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._suspicious_successive_range_count: int = 0
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._last_printable_seen: Optional[str] = None
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return character.isprintable()
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if (
|
||||||
|
character.isspace()
|
||||||
|
or is_punctuation(character)
|
||||||
|
or character in COMMON_SAFE_ASCII_CHARACTERS
|
||||||
|
):
|
||||||
|
self._last_printable_seen = None
|
||||||
|
return
|
||||||
|
|
||||||
|
if self._last_printable_seen is None:
|
||||||
|
self._last_printable_seen = character
|
||||||
|
return
|
||||||
|
|
||||||
|
unicode_range_a: Optional[str] = unicode_range(self._last_printable_seen)
|
||||||
|
unicode_range_b: Optional[str] = unicode_range(character)
|
||||||
|
|
||||||
|
if is_suspiciously_successive_range(unicode_range_a, unicode_range_b):
|
||||||
|
self._suspicious_successive_range_count += 1
|
||||||
|
|
||||||
|
self._last_printable_seen = character
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._character_count = 0
|
||||||
|
self._suspicious_successive_range_count = 0
|
||||||
|
self._last_printable_seen = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count <= 24:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
ratio_of_suspicious_range_usage: float = (
|
||||||
|
self._suspicious_successive_range_count * 2
|
||||||
|
) / self._character_count
|
||||||
|
|
||||||
|
return ratio_of_suspicious_range_usage
|
||||||
|
|
||||||
|
|
||||||
|
class SuperWeirdWordPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._word_count: int = 0
|
||||||
|
self._bad_word_count: int = 0
|
||||||
|
self._foreign_long_count: int = 0
|
||||||
|
|
||||||
|
self._is_current_word_bad: bool = False
|
||||||
|
self._foreign_long_watch: bool = False
|
||||||
|
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._bad_character_count: int = 0
|
||||||
|
|
||||||
|
self._buffer: str = ""
|
||||||
|
self._buffer_accent_count: int = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
if character.isalpha():
|
||||||
|
self._buffer += character
|
||||||
|
if is_accentuated(character):
|
||||||
|
self._buffer_accent_count += 1
|
||||||
|
if (
|
||||||
|
self._foreign_long_watch is False
|
||||||
|
and (is_latin(character) is False or is_accentuated(character))
|
||||||
|
and is_cjk(character) is False
|
||||||
|
and is_hangul(character) is False
|
||||||
|
and is_katakana(character) is False
|
||||||
|
and is_hiragana(character) is False
|
||||||
|
and is_thai(character) is False
|
||||||
|
):
|
||||||
|
self._foreign_long_watch = True
|
||||||
|
return
|
||||||
|
if not self._buffer:
|
||||||
|
return
|
||||||
|
if (
|
||||||
|
character.isspace() or is_punctuation(character) or is_separator(character)
|
||||||
|
) and self._buffer:
|
||||||
|
self._word_count += 1
|
||||||
|
buffer_length: int = len(self._buffer)
|
||||||
|
|
||||||
|
self._character_count += buffer_length
|
||||||
|
|
||||||
|
if buffer_length >= 4:
|
||||||
|
if self._buffer_accent_count / buffer_length > 0.34:
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
# Word/Buffer ending with an upper case accentuated letter are so rare,
|
||||||
|
# that we will consider them all as suspicious. Same weight as foreign_long suspicious.
|
||||||
|
if (
|
||||||
|
is_accentuated(self._buffer[-1])
|
||||||
|
and self._buffer[-1].isupper()
|
||||||
|
and all(_.isupper() for _ in self._buffer) is False
|
||||||
|
):
|
||||||
|
self._foreign_long_count += 1
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
if buffer_length >= 24 and self._foreign_long_watch:
|
||||||
|
camel_case_dst = [
|
||||||
|
i
|
||||||
|
for c, i in zip(self._buffer, range(0, buffer_length))
|
||||||
|
if c.isupper()
|
||||||
|
]
|
||||||
|
probable_camel_cased: bool = False
|
||||||
|
|
||||||
|
if camel_case_dst and (len(camel_case_dst) / buffer_length <= 0.3):
|
||||||
|
probable_camel_cased = True
|
||||||
|
|
||||||
|
if not probable_camel_cased:
|
||||||
|
self._foreign_long_count += 1
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
|
||||||
|
if self._is_current_word_bad:
|
||||||
|
self._bad_word_count += 1
|
||||||
|
self._bad_character_count += len(self._buffer)
|
||||||
|
self._is_current_word_bad = False
|
||||||
|
|
||||||
|
self._foreign_long_watch = False
|
||||||
|
self._buffer = ""
|
||||||
|
self._buffer_accent_count = 0
|
||||||
|
elif (
|
||||||
|
character not in {"<", ">", "-", "=", "~", "|", "_"}
|
||||||
|
and character.isdigit() is False
|
||||||
|
and is_symbol(character)
|
||||||
|
):
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
self._buffer += character
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._buffer = ""
|
||||||
|
self._is_current_word_bad = False
|
||||||
|
self._foreign_long_watch = False
|
||||||
|
self._bad_word_count = 0
|
||||||
|
self._word_count = 0
|
||||||
|
self._character_count = 0
|
||||||
|
self._bad_character_count = 0
|
||||||
|
self._foreign_long_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._word_count <= 10 and self._foreign_long_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
return self._bad_character_count / self._character_count
|
||||||
|
|
||||||
|
|
||||||
|
class CjkInvalidStopPlugin(MessDetectorPlugin):
|
||||||
|
"""
|
||||||
|
GB(Chinese) based encoding often render the stop incorrectly when the content does not fit and
|
||||||
|
can be easily detected. Searching for the overuse of '丅' and '丄'.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._wrong_stop_count: int = 0
|
||||||
|
self._cjk_character_count: int = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
if character in {"丅", "丄"}:
|
||||||
|
self._wrong_stop_count += 1
|
||||||
|
return
|
||||||
|
if is_cjk(character):
|
||||||
|
self._cjk_character_count += 1
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._wrong_stop_count = 0
|
||||||
|
self._cjk_character_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._cjk_character_count < 16:
|
||||||
|
return 0.0
|
||||||
|
return self._wrong_stop_count / self._cjk_character_count
|
||||||
|
|
||||||
|
|
||||||
|
class ArchaicUpperLowerPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._buf: bool = False
|
||||||
|
|
||||||
|
self._character_count_since_last_sep: int = 0
|
||||||
|
|
||||||
|
self._successive_upper_lower_count: int = 0
|
||||||
|
self._successive_upper_lower_count_final: int = 0
|
||||||
|
|
||||||
|
self._character_count: int = 0
|
||||||
|
|
||||||
|
self._last_alpha_seen: Optional[str] = None
|
||||||
|
self._current_ascii_only: bool = True
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
is_concerned = character.isalpha() and is_case_variable(character)
|
||||||
|
chunk_sep = is_concerned is False
|
||||||
|
|
||||||
|
if chunk_sep and self._character_count_since_last_sep > 0:
|
||||||
|
if (
|
||||||
|
self._character_count_since_last_sep <= 64
|
||||||
|
and character.isdigit() is False
|
||||||
|
and self._current_ascii_only is False
|
||||||
|
):
|
||||||
|
self._successive_upper_lower_count_final += (
|
||||||
|
self._successive_upper_lower_count
|
||||||
|
)
|
||||||
|
|
||||||
|
self._successive_upper_lower_count = 0
|
||||||
|
self._character_count_since_last_sep = 0
|
||||||
|
self._last_alpha_seen = None
|
||||||
|
self._buf = False
|
||||||
|
self._character_count += 1
|
||||||
|
self._current_ascii_only = True
|
||||||
|
|
||||||
|
return
|
||||||
|
|
||||||
|
if self._current_ascii_only is True and character.isascii() is False:
|
||||||
|
self._current_ascii_only = False
|
||||||
|
|
||||||
|
if self._last_alpha_seen is not None:
|
||||||
|
if (character.isupper() and self._last_alpha_seen.islower()) or (
|
||||||
|
character.islower() and self._last_alpha_seen.isupper()
|
||||||
|
):
|
||||||
|
if self._buf is True:
|
||||||
|
self._successive_upper_lower_count += 2
|
||||||
|
self._buf = False
|
||||||
|
else:
|
||||||
|
self._buf = True
|
||||||
|
else:
|
||||||
|
self._buf = False
|
||||||
|
|
||||||
|
self._character_count += 1
|
||||||
|
self._character_count_since_last_sep += 1
|
||||||
|
self._last_alpha_seen = character
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._character_count = 0
|
||||||
|
self._character_count_since_last_sep = 0
|
||||||
|
self._successive_upper_lower_count = 0
|
||||||
|
self._successive_upper_lower_count_final = 0
|
||||||
|
self._last_alpha_seen = None
|
||||||
|
self._buf = False
|
||||||
|
self._current_ascii_only = True
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
return self._successive_upper_lower_count_final / self._character_count
|
||||||
|
|
||||||
|
|
||||||
|
class ArabicIsolatedFormPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._isolated_form_count: int = 0
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
self._character_count = 0
|
||||||
|
self._isolated_form_count = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return is_arabic(character)
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if is_arabic_isolated_form(character):
|
||||||
|
self._isolated_form_count += 1
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count < 8:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
isolated_form_usage: float = self._isolated_form_count / self._character_count
|
||||||
|
|
||||||
|
return isolated_form_usage
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=1024)
|
||||||
|
def is_suspiciously_successive_range(
|
||||||
|
unicode_range_a: Optional[str], unicode_range_b: Optional[str]
|
||||||
|
) -> bool:
|
||||||
|
"""
|
||||||
|
Determine if two Unicode range seen next to each other can be considered as suspicious.
|
||||||
|
"""
|
||||||
|
if unicode_range_a is None or unicode_range_b is None:
|
||||||
|
return True
|
||||||
|
|
||||||
|
if unicode_range_a == unicode_range_b:
|
||||||
|
return False
|
||||||
|
|
||||||
|
if "Latin" in unicode_range_a and "Latin" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
|
||||||
|
if "Emoticons" in unicode_range_a or "Emoticons" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Latin characters can be accompanied with a combining diacritical mark
|
||||||
|
# eg. Vietnamese.
|
||||||
|
if ("Latin" in unicode_range_a or "Latin" in unicode_range_b) and (
|
||||||
|
"Combining" in unicode_range_a or "Combining" in unicode_range_b
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
|
||||||
|
keywords_range_a, keywords_range_b = unicode_range_a.split(
|
||||||
|
" "
|
||||||
|
), unicode_range_b.split(" ")
|
||||||
|
|
||||||
|
for el in keywords_range_a:
|
||||||
|
if el in UNICODE_SECONDARY_RANGE_KEYWORD:
|
||||||
|
continue
|
||||||
|
if el in keywords_range_b:
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Japanese Exception
|
||||||
|
range_a_jp_chars, range_b_jp_chars = (
|
||||||
|
unicode_range_a
|
||||||
|
in (
|
||||||
|
"Hiragana",
|
||||||
|
"Katakana",
|
||||||
|
),
|
||||||
|
unicode_range_b in ("Hiragana", "Katakana"),
|
||||||
|
)
|
||||||
|
if (range_a_jp_chars or range_b_jp_chars) and (
|
||||||
|
"CJK" in unicode_range_a or "CJK" in unicode_range_b
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
if range_a_jp_chars and range_b_jp_chars:
|
||||||
|
return False
|
||||||
|
|
||||||
|
if "Hangul" in unicode_range_a or "Hangul" in unicode_range_b:
|
||||||
|
if "CJK" in unicode_range_a or "CJK" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
if unicode_range_a == "Basic Latin" or unicode_range_b == "Basic Latin":
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Chinese/Japanese use dedicated range for punctuation and/or separators.
|
||||||
|
if ("CJK" in unicode_range_a or "CJK" in unicode_range_b) or (
|
||||||
|
unicode_range_a in ["Katakana", "Hiragana"]
|
||||||
|
and unicode_range_b in ["Katakana", "Hiragana"]
|
||||||
|
):
|
||||||
|
if "Punctuation" in unicode_range_a or "Punctuation" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
if "Forms" in unicode_range_a or "Forms" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
if unicode_range_a == "Basic Latin" or unicode_range_b == "Basic Latin":
|
||||||
|
return False
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=2048)
|
||||||
|
def mess_ratio(
|
||||||
|
decoded_sequence: str, maximum_threshold: float = 0.2, debug: bool = False
|
||||||
|
) -> float:
|
||||||
|
"""
|
||||||
|
Compute a mess ratio given a decoded bytes sequence. The maximum threshold does stop the computation earlier.
|
||||||
|
"""
|
||||||
|
|
||||||
|
detectors: List[MessDetectorPlugin] = [
|
||||||
|
md_class() for md_class in MessDetectorPlugin.__subclasses__()
|
||||||
|
]
|
||||||
|
|
||||||
|
length: int = len(decoded_sequence) + 1
|
||||||
|
|
||||||
|
mean_mess_ratio: float = 0.0
|
||||||
|
|
||||||
|
if length < 512:
|
||||||
|
intermediary_mean_mess_ratio_calc: int = 32
|
||||||
|
elif length <= 1024:
|
||||||
|
intermediary_mean_mess_ratio_calc = 64
|
||||||
|
else:
|
||||||
|
intermediary_mean_mess_ratio_calc = 128
|
||||||
|
|
||||||
|
for character, index in zip(decoded_sequence + "\n", range(length)):
|
||||||
|
for detector in detectors:
|
||||||
|
if detector.eligible(character):
|
||||||
|
detector.feed(character)
|
||||||
|
|
||||||
|
if (
|
||||||
|
index > 0 and index % intermediary_mean_mess_ratio_calc == 0
|
||||||
|
) or index == length - 1:
|
||||||
|
mean_mess_ratio = sum(dt.ratio for dt in detectors)
|
||||||
|
|
||||||
|
if mean_mess_ratio >= maximum_threshold:
|
||||||
|
break
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
logger = getLogger("charset_normalizer")
|
||||||
|
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Mess-detector extended-analysis start. "
|
||||||
|
f"intermediary_mean_mess_ratio_calc={intermediary_mean_mess_ratio_calc} mean_mess_ratio={mean_mess_ratio} "
|
||||||
|
f"maximum_threshold={maximum_threshold}",
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(decoded_sequence) > 16:
|
||||||
|
logger.log(TRACE, f"Starting with: {decoded_sequence[:16]}")
|
||||||
|
logger.log(TRACE, f"Ending with: {decoded_sequence[-16::]}")
|
||||||
|
|
||||||
|
for dt in detectors: # pragma: nocover
|
||||||
|
logger.log(TRACE, f"{dt.__class__}: {dt.ratio}")
|
||||||
|
|
||||||
|
return round(mean_mess_ratio, 3)
|
||||||
|
|
@ -0,0 +1,340 @@
|
||||||
|
from encodings.aliases import aliases
|
||||||
|
from hashlib import sha256
|
||||||
|
from json import dumps
|
||||||
|
from typing import Any, Dict, Iterator, List, Optional, Tuple, Union
|
||||||
|
|
||||||
|
from .constant import TOO_BIG_SEQUENCE
|
||||||
|
from .utils import iana_name, is_multi_byte_encoding, unicode_range
|
||||||
|
|
||||||
|
|
||||||
|
class CharsetMatch:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
payload: bytes,
|
||||||
|
guessed_encoding: str,
|
||||||
|
mean_mess_ratio: float,
|
||||||
|
has_sig_or_bom: bool,
|
||||||
|
languages: "CoherenceMatches",
|
||||||
|
decoded_payload: Optional[str] = None,
|
||||||
|
):
|
||||||
|
self._payload: bytes = payload
|
||||||
|
|
||||||
|
self._encoding: str = guessed_encoding
|
||||||
|
self._mean_mess_ratio: float = mean_mess_ratio
|
||||||
|
self._languages: CoherenceMatches = languages
|
||||||
|
self._has_sig_or_bom: bool = has_sig_or_bom
|
||||||
|
self._unicode_ranges: Optional[List[str]] = None
|
||||||
|
|
||||||
|
self._leaves: List[CharsetMatch] = []
|
||||||
|
self._mean_coherence_ratio: float = 0.0
|
||||||
|
|
||||||
|
self._output_payload: Optional[bytes] = None
|
||||||
|
self._output_encoding: Optional[str] = None
|
||||||
|
|
||||||
|
self._string: Optional[str] = decoded_payload
|
||||||
|
|
||||||
|
def __eq__(self, other: object) -> bool:
|
||||||
|
if not isinstance(other, CharsetMatch):
|
||||||
|
raise TypeError(
|
||||||
|
"__eq__ cannot be invoked on {} and {}.".format(
|
||||||
|
str(other.__class__), str(self.__class__)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
return self.encoding == other.encoding and self.fingerprint == other.fingerprint
|
||||||
|
|
||||||
|
def __lt__(self, other: object) -> bool:
|
||||||
|
"""
|
||||||
|
Implemented to make sorted available upon CharsetMatches items.
|
||||||
|
"""
|
||||||
|
if not isinstance(other, CharsetMatch):
|
||||||
|
raise ValueError
|
||||||
|
|
||||||
|
chaos_difference: float = abs(self.chaos - other.chaos)
|
||||||
|
coherence_difference: float = abs(self.coherence - other.coherence)
|
||||||
|
|
||||||
|
# Below 1% difference --> Use Coherence
|
||||||
|
if chaos_difference < 0.01 and coherence_difference > 0.02:
|
||||||
|
return self.coherence > other.coherence
|
||||||
|
elif chaos_difference < 0.01 and coherence_difference <= 0.02:
|
||||||
|
# When having a difficult decision, use the result that decoded as many multi-byte as possible.
|
||||||
|
# preserve RAM usage!
|
||||||
|
if len(self._payload) >= TOO_BIG_SEQUENCE:
|
||||||
|
return self.chaos < other.chaos
|
||||||
|
return self.multi_byte_usage > other.multi_byte_usage
|
||||||
|
|
||||||
|
return self.chaos < other.chaos
|
||||||
|
|
||||||
|
@property
|
||||||
|
def multi_byte_usage(self) -> float:
|
||||||
|
return 1.0 - (len(str(self)) / len(self.raw))
|
||||||
|
|
||||||
|
def __str__(self) -> str:
|
||||||
|
# Lazy Str Loading
|
||||||
|
if self._string is None:
|
||||||
|
self._string = str(self._payload, self._encoding, "strict")
|
||||||
|
return self._string
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
return "<CharsetMatch '{}' bytes({})>".format(self.encoding, self.fingerprint)
|
||||||
|
|
||||||
|
def add_submatch(self, other: "CharsetMatch") -> None:
|
||||||
|
if not isinstance(other, CharsetMatch) or other == self:
|
||||||
|
raise ValueError(
|
||||||
|
"Unable to add instance <{}> as a submatch of a CharsetMatch".format(
|
||||||
|
other.__class__
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
other._string = None # Unload RAM usage; dirty trick.
|
||||||
|
self._leaves.append(other)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def encoding(self) -> str:
|
||||||
|
return self._encoding
|
||||||
|
|
||||||
|
@property
|
||||||
|
def encoding_aliases(self) -> List[str]:
|
||||||
|
"""
|
||||||
|
Encoding name are known by many name, using this could help when searching for IBM855 when it's listed as CP855.
|
||||||
|
"""
|
||||||
|
also_known_as: List[str] = []
|
||||||
|
for u, p in aliases.items():
|
||||||
|
if self.encoding == u:
|
||||||
|
also_known_as.append(p)
|
||||||
|
elif self.encoding == p:
|
||||||
|
also_known_as.append(u)
|
||||||
|
return also_known_as
|
||||||
|
|
||||||
|
@property
|
||||||
|
def bom(self) -> bool:
|
||||||
|
return self._has_sig_or_bom
|
||||||
|
|
||||||
|
@property
|
||||||
|
def byte_order_mark(self) -> bool:
|
||||||
|
return self._has_sig_or_bom
|
||||||
|
|
||||||
|
@property
|
||||||
|
def languages(self) -> List[str]:
|
||||||
|
"""
|
||||||
|
Return the complete list of possible languages found in decoded sequence.
|
||||||
|
Usually not really useful. Returned list may be empty even if 'language' property return something != 'Unknown'.
|
||||||
|
"""
|
||||||
|
return [e[0] for e in self._languages]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def language(self) -> str:
|
||||||
|
"""
|
||||||
|
Most probable language found in decoded sequence. If none were detected or inferred, the property will return
|
||||||
|
"Unknown".
|
||||||
|
"""
|
||||||
|
if not self._languages:
|
||||||
|
# Trying to infer the language based on the given encoding
|
||||||
|
# Its either English or we should not pronounce ourselves in certain cases.
|
||||||
|
if "ascii" in self.could_be_from_charset:
|
||||||
|
return "English"
|
||||||
|
|
||||||
|
# doing it there to avoid circular import
|
||||||
|
from charset_normalizer.cd import encoding_languages, mb_encoding_languages
|
||||||
|
|
||||||
|
languages = (
|
||||||
|
mb_encoding_languages(self.encoding)
|
||||||
|
if is_multi_byte_encoding(self.encoding)
|
||||||
|
else encoding_languages(self.encoding)
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(languages) == 0 or "Latin Based" in languages:
|
||||||
|
return "Unknown"
|
||||||
|
|
||||||
|
return languages[0]
|
||||||
|
|
||||||
|
return self._languages[0][0]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def chaos(self) -> float:
|
||||||
|
return self._mean_mess_ratio
|
||||||
|
|
||||||
|
@property
|
||||||
|
def coherence(self) -> float:
|
||||||
|
if not self._languages:
|
||||||
|
return 0.0
|
||||||
|
return self._languages[0][1]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def percent_chaos(self) -> float:
|
||||||
|
return round(self.chaos * 100, ndigits=3)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def percent_coherence(self) -> float:
|
||||||
|
return round(self.coherence * 100, ndigits=3)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def raw(self) -> bytes:
|
||||||
|
"""
|
||||||
|
Original untouched bytes.
|
||||||
|
"""
|
||||||
|
return self._payload
|
||||||
|
|
||||||
|
@property
|
||||||
|
def submatch(self) -> List["CharsetMatch"]:
|
||||||
|
return self._leaves
|
||||||
|
|
||||||
|
@property
|
||||||
|
def has_submatch(self) -> bool:
|
||||||
|
return len(self._leaves) > 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def alphabets(self) -> List[str]:
|
||||||
|
if self._unicode_ranges is not None:
|
||||||
|
return self._unicode_ranges
|
||||||
|
# list detected ranges
|
||||||
|
detected_ranges: List[Optional[str]] = [
|
||||||
|
unicode_range(char) for char in str(self)
|
||||||
|
]
|
||||||
|
# filter and sort
|
||||||
|
self._unicode_ranges = sorted(list({r for r in detected_ranges if r}))
|
||||||
|
return self._unicode_ranges
|
||||||
|
|
||||||
|
@property
|
||||||
|
def could_be_from_charset(self) -> List[str]:
|
||||||
|
"""
|
||||||
|
The complete list of encoding that output the exact SAME str result and therefore could be the originating
|
||||||
|
encoding.
|
||||||
|
This list does include the encoding available in property 'encoding'.
|
||||||
|
"""
|
||||||
|
return [self._encoding] + [m.encoding for m in self._leaves]
|
||||||
|
|
||||||
|
def output(self, encoding: str = "utf_8") -> bytes:
|
||||||
|
"""
|
||||||
|
Method to get re-encoded bytes payload using given target encoding. Default to UTF-8.
|
||||||
|
Any errors will be simply ignored by the encoder NOT replaced.
|
||||||
|
"""
|
||||||
|
if self._output_encoding is None or self._output_encoding != encoding:
|
||||||
|
self._output_encoding = encoding
|
||||||
|
self._output_payload = str(self).encode(encoding, "replace")
|
||||||
|
|
||||||
|
return self._output_payload # type: ignore
|
||||||
|
|
||||||
|
@property
|
||||||
|
def fingerprint(self) -> str:
|
||||||
|
"""
|
||||||
|
Retrieve the unique SHA256 computed using the transformed (re-encoded) payload. Not the original one.
|
||||||
|
"""
|
||||||
|
return sha256(self.output()).hexdigest()
|
||||||
|
|
||||||
|
|
||||||
|
class CharsetMatches:
|
||||||
|
"""
|
||||||
|
Container with every CharsetMatch items ordered by default from most probable to the less one.
|
||||||
|
Act like a list(iterable) but does not implements all related methods.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, results: Optional[List[CharsetMatch]] = None):
|
||||||
|
self._results: List[CharsetMatch] = sorted(results) if results else []
|
||||||
|
|
||||||
|
def __iter__(self) -> Iterator[CharsetMatch]:
|
||||||
|
yield from self._results
|
||||||
|
|
||||||
|
def __getitem__(self, item: Union[int, str]) -> CharsetMatch:
|
||||||
|
"""
|
||||||
|
Retrieve a single item either by its position or encoding name (alias may be used here).
|
||||||
|
Raise KeyError upon invalid index or encoding not present in results.
|
||||||
|
"""
|
||||||
|
if isinstance(item, int):
|
||||||
|
return self._results[item]
|
||||||
|
if isinstance(item, str):
|
||||||
|
item = iana_name(item, False)
|
||||||
|
for result in self._results:
|
||||||
|
if item in result.could_be_from_charset:
|
||||||
|
return result
|
||||||
|
raise KeyError
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
return len(self._results)
|
||||||
|
|
||||||
|
def __bool__(self) -> bool:
|
||||||
|
return len(self._results) > 0
|
||||||
|
|
||||||
|
def append(self, item: CharsetMatch) -> None:
|
||||||
|
"""
|
||||||
|
Insert a single match. Will be inserted accordingly to preserve sort.
|
||||||
|
Can be inserted as a submatch.
|
||||||
|
"""
|
||||||
|
if not isinstance(item, CharsetMatch):
|
||||||
|
raise ValueError(
|
||||||
|
"Cannot append instance '{}' to CharsetMatches".format(
|
||||||
|
str(item.__class__)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
# We should disable the submatch factoring when the input file is too heavy (conserve RAM usage)
|
||||||
|
if len(item.raw) <= TOO_BIG_SEQUENCE:
|
||||||
|
for match in self._results:
|
||||||
|
if match.fingerprint == item.fingerprint and match.chaos == item.chaos:
|
||||||
|
match.add_submatch(item)
|
||||||
|
return
|
||||||
|
self._results.append(item)
|
||||||
|
self._results = sorted(self._results)
|
||||||
|
|
||||||
|
def best(self) -> Optional["CharsetMatch"]:
|
||||||
|
"""
|
||||||
|
Simply return the first match. Strict equivalent to matches[0].
|
||||||
|
"""
|
||||||
|
if not self._results:
|
||||||
|
return None
|
||||||
|
return self._results[0]
|
||||||
|
|
||||||
|
def first(self) -> Optional["CharsetMatch"]:
|
||||||
|
"""
|
||||||
|
Redundant method, call the method best(). Kept for BC reasons.
|
||||||
|
"""
|
||||||
|
return self.best()
|
||||||
|
|
||||||
|
|
||||||
|
CoherenceMatch = Tuple[str, float]
|
||||||
|
CoherenceMatches = List[CoherenceMatch]
|
||||||
|
|
||||||
|
|
||||||
|
class CliDetectionResult:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
path: str,
|
||||||
|
encoding: Optional[str],
|
||||||
|
encoding_aliases: List[str],
|
||||||
|
alternative_encodings: List[str],
|
||||||
|
language: str,
|
||||||
|
alphabets: List[str],
|
||||||
|
has_sig_or_bom: bool,
|
||||||
|
chaos: float,
|
||||||
|
coherence: float,
|
||||||
|
unicode_path: Optional[str],
|
||||||
|
is_preferred: bool,
|
||||||
|
):
|
||||||
|
self.path: str = path
|
||||||
|
self.unicode_path: Optional[str] = unicode_path
|
||||||
|
self.encoding: Optional[str] = encoding
|
||||||
|
self.encoding_aliases: List[str] = encoding_aliases
|
||||||
|
self.alternative_encodings: List[str] = alternative_encodings
|
||||||
|
self.language: str = language
|
||||||
|
self.alphabets: List[str] = alphabets
|
||||||
|
self.has_sig_or_bom: bool = has_sig_or_bom
|
||||||
|
self.chaos: float = chaos
|
||||||
|
self.coherence: float = coherence
|
||||||
|
self.is_preferred: bool = is_preferred
|
||||||
|
|
||||||
|
@property
|
||||||
|
def __dict__(self) -> Dict[str, Any]: # type: ignore
|
||||||
|
return {
|
||||||
|
"path": self.path,
|
||||||
|
"encoding": self.encoding,
|
||||||
|
"encoding_aliases": self.encoding_aliases,
|
||||||
|
"alternative_encodings": self.alternative_encodings,
|
||||||
|
"language": self.language,
|
||||||
|
"alphabets": self.alphabets,
|
||||||
|
"has_sig_or_bom": self.has_sig_or_bom,
|
||||||
|
"chaos": self.chaos,
|
||||||
|
"coherence": self.coherence,
|
||||||
|
"unicode_path": self.unicode_path,
|
||||||
|
"is_preferred": self.is_preferred,
|
||||||
|
}
|
||||||
|
|
||||||
|
def to_json(self) -> str:
|
||||||
|
return dumps(self.__dict__, ensure_ascii=True, indent=4)
|
||||||
|
|
@ -0,0 +1,421 @@
|
||||||
|
import importlib
|
||||||
|
import logging
|
||||||
|
import unicodedata
|
||||||
|
from codecs import IncrementalDecoder
|
||||||
|
from encodings.aliases import aliases
|
||||||
|
from functools import lru_cache
|
||||||
|
from re import findall
|
||||||
|
from typing import Generator, List, Optional, Set, Tuple, Union
|
||||||
|
|
||||||
|
from _multibytecodec import MultibyteIncrementalDecoder
|
||||||
|
|
||||||
|
from .constant import (
|
||||||
|
ENCODING_MARKS,
|
||||||
|
IANA_SUPPORTED_SIMILAR,
|
||||||
|
RE_POSSIBLE_ENCODING_INDICATION,
|
||||||
|
UNICODE_RANGES_COMBINED,
|
||||||
|
UNICODE_SECONDARY_RANGE_KEYWORD,
|
||||||
|
UTF8_MAXIMAL_ALLOCATION,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_accentuated(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
description: str = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
return (
|
||||||
|
"WITH GRAVE" in description
|
||||||
|
or "WITH ACUTE" in description
|
||||||
|
or "WITH CEDILLA" in description
|
||||||
|
or "WITH DIAERESIS" in description
|
||||||
|
or "WITH CIRCUMFLEX" in description
|
||||||
|
or "WITH TILDE" in description
|
||||||
|
or "WITH MACRON" in description
|
||||||
|
or "WITH RING ABOVE" in description
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def remove_accent(character: str) -> str:
|
||||||
|
decomposed: str = unicodedata.decomposition(character)
|
||||||
|
if not decomposed:
|
||||||
|
return character
|
||||||
|
|
||||||
|
codes: List[str] = decomposed.split(" ")
|
||||||
|
|
||||||
|
return chr(int(codes[0], 16))
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def unicode_range(character: str) -> Optional[str]:
|
||||||
|
"""
|
||||||
|
Retrieve the Unicode range official name from a single character.
|
||||||
|
"""
|
||||||
|
character_ord: int = ord(character)
|
||||||
|
|
||||||
|
for range_name, ord_range in UNICODE_RANGES_COMBINED.items():
|
||||||
|
if character_ord in ord_range:
|
||||||
|
return range_name
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_latin(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
description: str = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
return "LATIN" in description
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_punctuation(character: str) -> bool:
|
||||||
|
character_category: str = unicodedata.category(character)
|
||||||
|
|
||||||
|
if "P" in character_category:
|
||||||
|
return True
|
||||||
|
|
||||||
|
character_range: Optional[str] = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "Punctuation" in character_range
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_symbol(character: str) -> bool:
|
||||||
|
character_category: str = unicodedata.category(character)
|
||||||
|
|
||||||
|
if "S" in character_category or "N" in character_category:
|
||||||
|
return True
|
||||||
|
|
||||||
|
character_range: Optional[str] = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "Forms" in character_range and character_category != "Lo"
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_emoticon(character: str) -> bool:
|
||||||
|
character_range: Optional[str] = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "Emoticons" in character_range or "Pictographs" in character_range
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_separator(character: str) -> bool:
|
||||||
|
if character.isspace() or character in {"|", "+", "<", ">"}:
|
||||||
|
return True
|
||||||
|
|
||||||
|
character_category: str = unicodedata.category(character)
|
||||||
|
|
||||||
|
return "Z" in character_category or character_category in {"Po", "Pd", "Pc"}
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_case_variable(character: str) -> bool:
|
||||||
|
return character.islower() != character.isupper()
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_cjk(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "CJK" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_hiragana(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "HIRAGANA" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_katakana(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "KATAKANA" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_hangul(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "HANGUL" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_thai(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "THAI" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_arabic(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "ARABIC" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_arabic_isolated_form(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "ARABIC" in character_name and "ISOLATED FORM" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=len(UNICODE_RANGES_COMBINED))
|
||||||
|
def is_unicode_range_secondary(range_name: str) -> bool:
|
||||||
|
return any(keyword in range_name for keyword in UNICODE_SECONDARY_RANGE_KEYWORD)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_unprintable(character: str) -> bool:
|
||||||
|
return (
|
||||||
|
character.isspace() is False # includes \n \t \r \v
|
||||||
|
and character.isprintable() is False
|
||||||
|
and character != "\x1A" # Why? Its the ASCII substitute character.
|
||||||
|
and character != "\ufeff" # bug discovered in Python,
|
||||||
|
# Zero Width No-Break Space located in Arabic Presentation Forms-B, Unicode 1.1 not acknowledged as space.
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def any_specified_encoding(sequence: bytes, search_zone: int = 8192) -> Optional[str]:
|
||||||
|
"""
|
||||||
|
Extract using ASCII-only decoder any specified encoding in the first n-bytes.
|
||||||
|
"""
|
||||||
|
if not isinstance(sequence, bytes):
|
||||||
|
raise TypeError
|
||||||
|
|
||||||
|
seq_len: int = len(sequence)
|
||||||
|
|
||||||
|
results: List[str] = findall(
|
||||||
|
RE_POSSIBLE_ENCODING_INDICATION,
|
||||||
|
sequence[: min(seq_len, search_zone)].decode("ascii", errors="ignore"),
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(results) == 0:
|
||||||
|
return None
|
||||||
|
|
||||||
|
for specified_encoding in results:
|
||||||
|
specified_encoding = specified_encoding.lower().replace("-", "_")
|
||||||
|
|
||||||
|
encoding_alias: str
|
||||||
|
encoding_iana: str
|
||||||
|
|
||||||
|
for encoding_alias, encoding_iana in aliases.items():
|
||||||
|
if encoding_alias == specified_encoding:
|
||||||
|
return encoding_iana
|
||||||
|
if encoding_iana == specified_encoding:
|
||||||
|
return encoding_iana
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=128)
|
||||||
|
def is_multi_byte_encoding(name: str) -> bool:
|
||||||
|
"""
|
||||||
|
Verify is a specific encoding is a multi byte one based on it IANA name
|
||||||
|
"""
|
||||||
|
return name in {
|
||||||
|
"utf_8",
|
||||||
|
"utf_8_sig",
|
||||||
|
"utf_16",
|
||||||
|
"utf_16_be",
|
||||||
|
"utf_16_le",
|
||||||
|
"utf_32",
|
||||||
|
"utf_32_le",
|
||||||
|
"utf_32_be",
|
||||||
|
"utf_7",
|
||||||
|
} or issubclass(
|
||||||
|
importlib.import_module("encodings.{}".format(name)).IncrementalDecoder,
|
||||||
|
MultibyteIncrementalDecoder,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def identify_sig_or_bom(sequence: bytes) -> Tuple[Optional[str], bytes]:
|
||||||
|
"""
|
||||||
|
Identify and extract SIG/BOM in given sequence.
|
||||||
|
"""
|
||||||
|
|
||||||
|
for iana_encoding in ENCODING_MARKS:
|
||||||
|
marks: Union[bytes, List[bytes]] = ENCODING_MARKS[iana_encoding]
|
||||||
|
|
||||||
|
if isinstance(marks, bytes):
|
||||||
|
marks = [marks]
|
||||||
|
|
||||||
|
for mark in marks:
|
||||||
|
if sequence.startswith(mark):
|
||||||
|
return iana_encoding, mark
|
||||||
|
|
||||||
|
return None, b""
|
||||||
|
|
||||||
|
|
||||||
|
def should_strip_sig_or_bom(iana_encoding: str) -> bool:
|
||||||
|
return iana_encoding not in {"utf_16", "utf_32"}
|
||||||
|
|
||||||
|
|
||||||
|
def iana_name(cp_name: str, strict: bool = True) -> str:
|
||||||
|
cp_name = cp_name.lower().replace("-", "_")
|
||||||
|
|
||||||
|
encoding_alias: str
|
||||||
|
encoding_iana: str
|
||||||
|
|
||||||
|
for encoding_alias, encoding_iana in aliases.items():
|
||||||
|
if cp_name in [encoding_alias, encoding_iana]:
|
||||||
|
return encoding_iana
|
||||||
|
|
||||||
|
if strict:
|
||||||
|
raise ValueError("Unable to retrieve IANA for '{}'".format(cp_name))
|
||||||
|
|
||||||
|
return cp_name
|
||||||
|
|
||||||
|
|
||||||
|
def range_scan(decoded_sequence: str) -> List[str]:
|
||||||
|
ranges: Set[str] = set()
|
||||||
|
|
||||||
|
for character in decoded_sequence:
|
||||||
|
character_range: Optional[str] = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
continue
|
||||||
|
|
||||||
|
ranges.add(character_range)
|
||||||
|
|
||||||
|
return list(ranges)
|
||||||
|
|
||||||
|
|
||||||
|
def cp_similarity(iana_name_a: str, iana_name_b: str) -> float:
|
||||||
|
if is_multi_byte_encoding(iana_name_a) or is_multi_byte_encoding(iana_name_b):
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
decoder_a = importlib.import_module(
|
||||||
|
"encodings.{}".format(iana_name_a)
|
||||||
|
).IncrementalDecoder
|
||||||
|
decoder_b = importlib.import_module(
|
||||||
|
"encodings.{}".format(iana_name_b)
|
||||||
|
).IncrementalDecoder
|
||||||
|
|
||||||
|
id_a: IncrementalDecoder = decoder_a(errors="ignore")
|
||||||
|
id_b: IncrementalDecoder = decoder_b(errors="ignore")
|
||||||
|
|
||||||
|
character_match_count: int = 0
|
||||||
|
|
||||||
|
for i in range(255):
|
||||||
|
to_be_decoded: bytes = bytes([i])
|
||||||
|
if id_a.decode(to_be_decoded) == id_b.decode(to_be_decoded):
|
||||||
|
character_match_count += 1
|
||||||
|
|
||||||
|
return character_match_count / 254
|
||||||
|
|
||||||
|
|
||||||
|
def is_cp_similar(iana_name_a: str, iana_name_b: str) -> bool:
|
||||||
|
"""
|
||||||
|
Determine if two code page are at least 80% similar. IANA_SUPPORTED_SIMILAR dict was generated using
|
||||||
|
the function cp_similarity.
|
||||||
|
"""
|
||||||
|
return (
|
||||||
|
iana_name_a in IANA_SUPPORTED_SIMILAR
|
||||||
|
and iana_name_b in IANA_SUPPORTED_SIMILAR[iana_name_a]
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def set_logging_handler(
|
||||||
|
name: str = "charset_normalizer",
|
||||||
|
level: int = logging.INFO,
|
||||||
|
format_string: str = "%(asctime)s | %(levelname)s | %(message)s",
|
||||||
|
) -> None:
|
||||||
|
logger = logging.getLogger(name)
|
||||||
|
logger.setLevel(level)
|
||||||
|
|
||||||
|
handler = logging.StreamHandler()
|
||||||
|
handler.setFormatter(logging.Formatter(format_string))
|
||||||
|
logger.addHandler(handler)
|
||||||
|
|
||||||
|
|
||||||
|
def cut_sequence_chunks(
|
||||||
|
sequences: bytes,
|
||||||
|
encoding_iana: str,
|
||||||
|
offsets: range,
|
||||||
|
chunk_size: int,
|
||||||
|
bom_or_sig_available: bool,
|
||||||
|
strip_sig_or_bom: bool,
|
||||||
|
sig_payload: bytes,
|
||||||
|
is_multi_byte_decoder: bool,
|
||||||
|
decoded_payload: Optional[str] = None,
|
||||||
|
) -> Generator[str, None, None]:
|
||||||
|
if decoded_payload and is_multi_byte_decoder is False:
|
||||||
|
for i in offsets:
|
||||||
|
chunk = decoded_payload[i : i + chunk_size]
|
||||||
|
if not chunk:
|
||||||
|
break
|
||||||
|
yield chunk
|
||||||
|
else:
|
||||||
|
for i in offsets:
|
||||||
|
chunk_end = i + chunk_size
|
||||||
|
if chunk_end > len(sequences) + 8:
|
||||||
|
continue
|
||||||
|
|
||||||
|
cut_sequence = sequences[i : i + chunk_size]
|
||||||
|
|
||||||
|
if bom_or_sig_available and strip_sig_or_bom is False:
|
||||||
|
cut_sequence = sig_payload + cut_sequence
|
||||||
|
|
||||||
|
chunk = cut_sequence.decode(
|
||||||
|
encoding_iana,
|
||||||
|
errors="ignore" if is_multi_byte_decoder else "strict",
|
||||||
|
)
|
||||||
|
|
||||||
|
# multi-byte bad cutting detector and adjustment
|
||||||
|
# not the cleanest way to perform that fix but clever enough for now.
|
||||||
|
if is_multi_byte_decoder and i > 0:
|
||||||
|
chunk_partial_size_chk: int = min(chunk_size, 16)
|
||||||
|
|
||||||
|
if (
|
||||||
|
decoded_payload
|
||||||
|
and chunk[:chunk_partial_size_chk] not in decoded_payload
|
||||||
|
):
|
||||||
|
for j in range(i, i - 4, -1):
|
||||||
|
cut_sequence = sequences[j:chunk_end]
|
||||||
|
|
||||||
|
if bom_or_sig_available and strip_sig_or_bom is False:
|
||||||
|
cut_sequence = sig_payload + cut_sequence
|
||||||
|
|
||||||
|
chunk = cut_sequence.decode(encoding_iana, errors="ignore")
|
||||||
|
|
||||||
|
if chunk[:chunk_partial_size_chk] in decoded_payload:
|
||||||
|
break
|
||||||
|
|
||||||
|
yield chunk
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
"""
|
||||||
|
Expose version
|
||||||
|
"""
|
||||||
|
|
||||||
|
__version__ = "3.3.2"
|
||||||
|
VERSION = __version__.split(".")
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
pip
|
||||||
|
|
@ -0,0 +1,31 @@
|
||||||
|
BSD 3-Clause License
|
||||||
|
|
||||||
|
Copyright (c) 2013-2023, Kim Davies and contributors.
|
||||||
|
All rights reserved.
|
||||||
|
|
||||||
|
Redistribution and use in source and binary forms, with or without
|
||||||
|
modification, are permitted provided that the following conditions are
|
||||||
|
met:
|
||||||
|
|
||||||
|
1. Redistributions of source code must retain the above copyright
|
||||||
|
notice, this list of conditions and the following disclaimer.
|
||||||
|
|
||||||
|
2. Redistributions in binary form must reproduce the above copyright
|
||||||
|
notice, this list of conditions and the following disclaimer in the
|
||||||
|
documentation and/or other materials provided with the distribution.
|
||||||
|
|
||||||
|
3. Neither the name of the copyright holder nor the names of its
|
||||||
|
contributors may be used to endorse or promote products derived from
|
||||||
|
this software without specific prior written permission.
|
||||||
|
|
||||||
|
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||||
|
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||||
|
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||||
|
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||||
|
HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||||
|
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED
|
||||||
|
TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
||||||
|
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
|
||||||
|
LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
|
||||||
|
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
|
||||||
|
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||||
|
|
@ -0,0 +1,243 @@
|
||||||
|
Metadata-Version: 2.1
|
||||||
|
Name: idna
|
||||||
|
Version: 3.6
|
||||||
|
Summary: Internationalized Domain Names in Applications (IDNA)
|
||||||
|
Author-email: Kim Davies <kim+pypi@gumleaf.org>
|
||||||
|
Requires-Python: >=3.5
|
||||||
|
Description-Content-Type: text/x-rst
|
||||||
|
Classifier: Development Status :: 5 - Production/Stable
|
||||||
|
Classifier: Intended Audience :: Developers
|
||||||
|
Classifier: Intended Audience :: System Administrators
|
||||||
|
Classifier: License :: OSI Approved :: BSD License
|
||||||
|
Classifier: Operating System :: OS Independent
|
||||||
|
Classifier: Programming Language :: Python
|
||||||
|
Classifier: Programming Language :: Python :: 3
|
||||||
|
Classifier: Programming Language :: Python :: 3 :: Only
|
||||||
|
Classifier: Programming Language :: Python :: 3.5
|
||||||
|
Classifier: Programming Language :: Python :: 3.6
|
||||||
|
Classifier: Programming Language :: Python :: 3.7
|
||||||
|
Classifier: Programming Language :: Python :: 3.8
|
||||||
|
Classifier: Programming Language :: Python :: 3.9
|
||||||
|
Classifier: Programming Language :: Python :: 3.10
|
||||||
|
Classifier: Programming Language :: Python :: 3.11
|
||||||
|
Classifier: Programming Language :: Python :: 3.12
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: CPython
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
||||||
|
Classifier: Topic :: Internet :: Name Service (DNS)
|
||||||
|
Classifier: Topic :: Software Development :: Libraries :: Python Modules
|
||||||
|
Classifier: Topic :: Utilities
|
||||||
|
Project-URL: Changelog, https://github.com/kjd/idna/blob/master/HISTORY.rst
|
||||||
|
Project-URL: Issue tracker, https://github.com/kjd/idna/issues
|
||||||
|
Project-URL: Source, https://github.com/kjd/idna
|
||||||
|
|
||||||
|
Internationalized Domain Names in Applications (IDNA)
|
||||||
|
=====================================================
|
||||||
|
|
||||||
|
Support for the Internationalized Domain Names in
|
||||||
|
Applications (IDNA) protocol as specified in `RFC 5891
|
||||||
|
<https://tools.ietf.org/html/rfc5891>`_. This is the latest version of
|
||||||
|
the protocol and is sometimes referred to as “IDNA 2008”.
|
||||||
|
|
||||||
|
This library also provides support for Unicode Technical
|
||||||
|
Standard 46, `Unicode IDNA Compatibility Processing
|
||||||
|
<https://unicode.org/reports/tr46/>`_.
|
||||||
|
|
||||||
|
This acts as a suitable replacement for the “encodings.idna”
|
||||||
|
module that comes with the Python standard library, but which
|
||||||
|
only supports the older superseded IDNA specification (`RFC 3490
|
||||||
|
<https://tools.ietf.org/html/rfc3490>`_).
|
||||||
|
|
||||||
|
Basic functions are simply executed:
|
||||||
|
|
||||||
|
.. code-block:: pycon
|
||||||
|
|
||||||
|
>>> import idna
|
||||||
|
>>> idna.encode('ドメイン.テスト')
|
||||||
|
b'xn--eckwd4c7c.xn--zckzah'
|
||||||
|
>>> print(idna.decode('xn--eckwd4c7c.xn--zckzah'))
|
||||||
|
ドメイン.テスト
|
||||||
|
|
||||||
|
|
||||||
|
Installation
|
||||||
|
------------
|
||||||
|
|
||||||
|
This package is available for installation from PyPI:
|
||||||
|
|
||||||
|
.. code-block:: bash
|
||||||
|
|
||||||
|
$ python3 -m pip install idna
|
||||||
|
|
||||||
|
|
||||||
|
Usage
|
||||||
|
-----
|
||||||
|
|
||||||
|
For typical usage, the ``encode`` and ``decode`` functions will take a
|
||||||
|
domain name argument and perform a conversion to A-labels or U-labels
|
||||||
|
respectively.
|
||||||
|
|
||||||
|
.. code-block:: pycon
|
||||||
|
|
||||||
|
>>> import idna
|
||||||
|
>>> idna.encode('ドメイン.テスト')
|
||||||
|
b'xn--eckwd4c7c.xn--zckzah'
|
||||||
|
>>> print(idna.decode('xn--eckwd4c7c.xn--zckzah'))
|
||||||
|
ドメイン.テスト
|
||||||
|
|
||||||
|
You may use the codec encoding and decoding methods using the
|
||||||
|
``idna.codec`` module:
|
||||||
|
|
||||||
|
.. code-block:: pycon
|
||||||
|
|
||||||
|
>>> import idna.codec
|
||||||
|
>>> print('домен.испытание'.encode('idna2008'))
|
||||||
|
b'xn--d1acufc.xn--80akhbyknj4f'
|
||||||
|
>>> print(b'xn--d1acufc.xn--80akhbyknj4f'.decode('idna2008'))
|
||||||
|
домен.испытание
|
||||||
|
|
||||||
|
Conversions can be applied at a per-label basis using the ``ulabel`` or
|
||||||
|
``alabel`` functions if necessary:
|
||||||
|
|
||||||
|
.. code-block:: pycon
|
||||||
|
|
||||||
|
>>> idna.alabel('测试')
|
||||||
|
b'xn--0zwm56d'
|
||||||
|
|
||||||
|
Compatibility Mapping (UTS #46)
|
||||||
|
+++++++++++++++++++++++++++++++
|
||||||
|
|
||||||
|
As described in `RFC 5895 <https://tools.ietf.org/html/rfc5895>`_, the
|
||||||
|
IDNA specification does not normalize input from different potential
|
||||||
|
ways a user may input a domain name. This functionality, known as
|
||||||
|
a “mapping”, is considered by the specification to be a local
|
||||||
|
user-interface issue distinct from IDNA conversion functionality.
|
||||||
|
|
||||||
|
This library provides one such mapping that was developed by the
|
||||||
|
Unicode Consortium. Known as `Unicode IDNA Compatibility Processing
|
||||||
|
<https://unicode.org/reports/tr46/>`_, it provides for both a regular
|
||||||
|
mapping for typical applications, as well as a transitional mapping to
|
||||||
|
help migrate from older IDNA 2003 applications.
|
||||||
|
|
||||||
|
For example, “Königsgäßchen” is not a permissible label as *LATIN
|
||||||
|
CAPITAL LETTER K* is not allowed (nor are capital letters in general).
|
||||||
|
UTS 46 will convert this into lower case prior to applying the IDNA
|
||||||
|
conversion.
|
||||||
|
|
||||||
|
.. code-block:: pycon
|
||||||
|
|
||||||
|
>>> import idna
|
||||||
|
>>> idna.encode('Königsgäßchen')
|
||||||
|
...
|
||||||
|
idna.core.InvalidCodepoint: Codepoint U+004B at position 1 of 'Königsgäßchen' not allowed
|
||||||
|
>>> idna.encode('Königsgäßchen', uts46=True)
|
||||||
|
b'xn--knigsgchen-b4a3dun'
|
||||||
|
>>> print(idna.decode('xn--knigsgchen-b4a3dun'))
|
||||||
|
königsgäßchen
|
||||||
|
|
||||||
|
Transitional processing provides conversions to help transition from
|
||||||
|
the older 2003 standard to the current standard. For example, in the
|
||||||
|
original IDNA specification, the *LATIN SMALL LETTER SHARP S* (ß) was
|
||||||
|
converted into two *LATIN SMALL LETTER S* (ss), whereas in the current
|
||||||
|
IDNA specification this conversion is not performed.
|
||||||
|
|
||||||
|
.. code-block:: pycon
|
||||||
|
|
||||||
|
>>> idna.encode('Königsgäßchen', uts46=True, transitional=True)
|
||||||
|
'xn--knigsgsschen-lcb0w'
|
||||||
|
|
||||||
|
Implementers should use transitional processing with caution, only in
|
||||||
|
rare cases where conversion from legacy labels to current labels must be
|
||||||
|
performed (i.e. IDNA implementations that pre-date 2008). For typical
|
||||||
|
applications that just need to convert labels, transitional processing
|
||||||
|
is unlikely to be beneficial and could produce unexpected incompatible
|
||||||
|
results.
|
||||||
|
|
||||||
|
``encodings.idna`` Compatibility
|
||||||
|
++++++++++++++++++++++++++++++++
|
||||||
|
|
||||||
|
Function calls from the Python built-in ``encodings.idna`` module are
|
||||||
|
mapped to their IDNA 2008 equivalents using the ``idna.compat`` module.
|
||||||
|
Simply substitute the ``import`` clause in your code to refer to the new
|
||||||
|
module name.
|
||||||
|
|
||||||
|
Exceptions
|
||||||
|
----------
|
||||||
|
|
||||||
|
All errors raised during the conversion following the specification
|
||||||
|
should raise an exception derived from the ``idna.IDNAError`` base
|
||||||
|
class.
|
||||||
|
|
||||||
|
More specific exceptions that may be generated as ``idna.IDNABidiError``
|
||||||
|
when the error reflects an illegal combination of left-to-right and
|
||||||
|
right-to-left characters in a label; ``idna.InvalidCodepoint`` when
|
||||||
|
a specific codepoint is an illegal character in an IDN label (i.e.
|
||||||
|
INVALID); and ``idna.InvalidCodepointContext`` when the codepoint is
|
||||||
|
illegal based on its positional context (i.e. it is CONTEXTO or CONTEXTJ
|
||||||
|
but the contextual requirements are not satisfied.)
|
||||||
|
|
||||||
|
Building and Diagnostics
|
||||||
|
------------------------
|
||||||
|
|
||||||
|
The IDNA and UTS 46 functionality relies upon pre-calculated lookup
|
||||||
|
tables for performance. These tables are derived from computing against
|
||||||
|
eligibility criteria in the respective standards. These tables are
|
||||||
|
computed using the command-line script ``tools/idna-data``.
|
||||||
|
|
||||||
|
This tool will fetch relevant codepoint data from the Unicode repository
|
||||||
|
and perform the required calculations to identify eligibility. There are
|
||||||
|
three main modes:
|
||||||
|
|
||||||
|
* ``idna-data make-libdata``. Generates ``idnadata.py`` and
|
||||||
|
``uts46data.py``, the pre-calculated lookup tables used for IDNA and
|
||||||
|
UTS 46 conversions. Implementers who wish to track this library against
|
||||||
|
a different Unicode version may use this tool to manually generate a
|
||||||
|
different version of the ``idnadata.py`` and ``uts46data.py`` files.
|
||||||
|
|
||||||
|
* ``idna-data make-table``. Generate a table of the IDNA disposition
|
||||||
|
(e.g. PVALID, CONTEXTJ, CONTEXTO) in the format found in Appendix
|
||||||
|
B.1 of RFC 5892 and the pre-computed tables published by `IANA
|
||||||
|
<https://www.iana.org/>`_.
|
||||||
|
|
||||||
|
* ``idna-data U+0061``. Prints debugging output on the various
|
||||||
|
properties associated with an individual Unicode codepoint (in this
|
||||||
|
case, U+0061), that are used to assess the IDNA and UTS 46 status of a
|
||||||
|
codepoint. This is helpful in debugging or analysis.
|
||||||
|
|
||||||
|
The tool accepts a number of arguments, described using ``idna-data
|
||||||
|
-h``. Most notably, the ``--version`` argument allows the specification
|
||||||
|
of the version of Unicode to be used in computing the table data. For
|
||||||
|
example, ``idna-data --version 9.0.0 make-libdata`` will generate
|
||||||
|
library data against Unicode 9.0.0.
|
||||||
|
|
||||||
|
|
||||||
|
Additional Notes
|
||||||
|
----------------
|
||||||
|
|
||||||
|
* **Packages**. The latest tagged release version is published in the
|
||||||
|
`Python Package Index <https://pypi.org/project/idna/>`_.
|
||||||
|
|
||||||
|
* **Version support**. This library supports Python 3.5 and higher.
|
||||||
|
As this library serves as a low-level toolkit for a variety of
|
||||||
|
applications, many of which strive for broad compatibility with older
|
||||||
|
Python versions, there is no rush to remove older interpreter support.
|
||||||
|
Removing support for older versions should be well justified in that the
|
||||||
|
maintenance burden has become too high.
|
||||||
|
|
||||||
|
* **Python 2**. Python 2 is supported by version 2.x of this library.
|
||||||
|
While active development of the version 2.x series has ended, notable
|
||||||
|
issues being corrected may be backported to 2.x. Use "idna<3" in your
|
||||||
|
requirements file if you need this library for a Python 2 application.
|
||||||
|
|
||||||
|
* **Testing**. The library has a test suite based on each rule of the
|
||||||
|
IDNA specification, as well as tests that are provided as part of the
|
||||||
|
Unicode Technical Standard 46, `Unicode IDNA Compatibility Processing
|
||||||
|
<https://unicode.org/reports/tr46/>`_.
|
||||||
|
|
||||||
|
* **Emoji**. It is an occasional request to support emoji domains in
|
||||||
|
this library. Encoding of symbols like emoji is expressly prohibited by
|
||||||
|
the technical standard IDNA 2008 and emoji domains are broadly phased
|
||||||
|
out across the domain industry due to associated security risks. For
|
||||||
|
now, applications that need to support these non-compliant labels
|
||||||
|
may wish to consider trying the encode/decode operation in this library
|
||||||
|
first, and then falling back to using `encodings.idna`. See `the Github
|
||||||
|
project <https://github.com/kjd/idna/issues/18>`_ for more discussion.
|
||||||
|
|
||||||
|
|
@ -0,0 +1,22 @@
|
||||||
|
idna-3.6.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
||||||
|
idna-3.6.dist-info/LICENSE.md,sha256=yy-vDKGMbTh-x8tm8yGTn7puZ-nawJ0xR3y52NP-aJk,1541
|
||||||
|
idna-3.6.dist-info/METADATA,sha256=N93B509dkvvkd_Y0E_VxCHPkVkrD6InxoyfXvX4egds,9888
|
||||||
|
idna-3.6.dist-info/RECORD,,
|
||||||
|
idna-3.6.dist-info/WHEEL,sha256=EZbGkh7Ie4PoZfRQ8I0ZuP9VklN_TvcZ6DSE5Uar4z4,81
|
||||||
|
idna/__init__.py,sha256=KJQN1eQBr8iIK5SKrJ47lXvxG0BJ7Lm38W4zT0v_8lk,849
|
||||||
|
idna/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
idna/__pycache__/codec.cpython-312.pyc,,
|
||||||
|
idna/__pycache__/compat.cpython-312.pyc,,
|
||||||
|
idna/__pycache__/core.cpython-312.pyc,,
|
||||||
|
idna/__pycache__/idnadata.cpython-312.pyc,,
|
||||||
|
idna/__pycache__/intranges.cpython-312.pyc,,
|
||||||
|
idna/__pycache__/package_data.cpython-312.pyc,,
|
||||||
|
idna/__pycache__/uts46data.cpython-312.pyc,,
|
||||||
|
idna/codec.py,sha256=PS6m-XmdST7Wj7J7ulRMakPDt5EBJyYrT3CPtjh-7t4,3426
|
||||||
|
idna/compat.py,sha256=0_sOEUMT4CVw9doD3vyRhX80X19PwqFoUBs7gWsFME4,321
|
||||||
|
idna/core.py,sha256=Bxz9L1rH0N5U-yukGfPuDRTxR2jDUl96NCq1ql3YAUw,12908
|
||||||
|
idna/idnadata.py,sha256=9u3Ec_GRrhlcbs7QM3pAZ2ObEQzPIOm99FaVOm91UGg,44351
|
||||||
|
idna/intranges.py,sha256=YBr4fRYuWH7kTKS2tXlFjM24ZF1Pdvcir-aywniInqg,1881
|
||||||
|
idna/package_data.py,sha256=y-iv-qJdmHsWVR5FszYwsMo1AQg8qpdU2aU5nT-S2oQ,21
|
||||||
|
idna/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
||||||
|
idna/uts46data.py,sha256=1KuksWqLuccPXm2uyRVkhfiFLNIhM_H2m4azCcnOqEU,206503
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
Wheel-Version: 1.0
|
||||||
|
Generator: flit 3.9.0
|
||||||
|
Root-Is-Purelib: true
|
||||||
|
Tag: py3-none-any
|
||||||
|
|
@ -0,0 +1,44 @@
|
||||||
|
from .package_data import __version__
|
||||||
|
from .core import (
|
||||||
|
IDNABidiError,
|
||||||
|
IDNAError,
|
||||||
|
InvalidCodepoint,
|
||||||
|
InvalidCodepointContext,
|
||||||
|
alabel,
|
||||||
|
check_bidi,
|
||||||
|
check_hyphen_ok,
|
||||||
|
check_initial_combiner,
|
||||||
|
check_label,
|
||||||
|
check_nfc,
|
||||||
|
decode,
|
||||||
|
encode,
|
||||||
|
ulabel,
|
||||||
|
uts46_remap,
|
||||||
|
valid_contextj,
|
||||||
|
valid_contexto,
|
||||||
|
valid_label_length,
|
||||||
|
valid_string_length,
|
||||||
|
)
|
||||||
|
from .intranges import intranges_contain
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"IDNABidiError",
|
||||||
|
"IDNAError",
|
||||||
|
"InvalidCodepoint",
|
||||||
|
"InvalidCodepointContext",
|
||||||
|
"alabel",
|
||||||
|
"check_bidi",
|
||||||
|
"check_hyphen_ok",
|
||||||
|
"check_initial_combiner",
|
||||||
|
"check_label",
|
||||||
|
"check_nfc",
|
||||||
|
"decode",
|
||||||
|
"encode",
|
||||||
|
"intranges_contain",
|
||||||
|
"ulabel",
|
||||||
|
"uts46_remap",
|
||||||
|
"valid_contextj",
|
||||||
|
"valid_contexto",
|
||||||
|
"valid_label_length",
|
||||||
|
"valid_string_length",
|
||||||
|
]
|
||||||
|
|
@ -0,0 +1,118 @@
|
||||||
|
from .core import encode, decode, alabel, ulabel, IDNAError
|
||||||
|
import codecs
|
||||||
|
import re
|
||||||
|
from typing import Any, Tuple, Optional
|
||||||
|
|
||||||
|
_unicode_dots_re = re.compile('[\u002e\u3002\uff0e\uff61]')
|
||||||
|
|
||||||
|
class Codec(codecs.Codec):
|
||||||
|
|
||||||
|
def encode(self, data: str, errors: str = 'strict') -> Tuple[bytes, int]:
|
||||||
|
if errors != 'strict':
|
||||||
|
raise IDNAError('Unsupported error handling \"{}\"'.format(errors))
|
||||||
|
|
||||||
|
if not data:
|
||||||
|
return b"", 0
|
||||||
|
|
||||||
|
return encode(data), len(data)
|
||||||
|
|
||||||
|
def decode(self, data: bytes, errors: str = 'strict') -> Tuple[str, int]:
|
||||||
|
if errors != 'strict':
|
||||||
|
raise IDNAError('Unsupported error handling \"{}\"'.format(errors))
|
||||||
|
|
||||||
|
if not data:
|
||||||
|
return '', 0
|
||||||
|
|
||||||
|
return decode(data), len(data)
|
||||||
|
|
||||||
|
class IncrementalEncoder(codecs.BufferedIncrementalEncoder):
|
||||||
|
def _buffer_encode(self, data: str, errors: str, final: bool) -> Tuple[bytes, int]:
|
||||||
|
if errors != 'strict':
|
||||||
|
raise IDNAError('Unsupported error handling \"{}\"'.format(errors))
|
||||||
|
|
||||||
|
if not data:
|
||||||
|
return b'', 0
|
||||||
|
|
||||||
|
labels = _unicode_dots_re.split(data)
|
||||||
|
trailing_dot = b''
|
||||||
|
if labels:
|
||||||
|
if not labels[-1]:
|
||||||
|
trailing_dot = b'.'
|
||||||
|
del labels[-1]
|
||||||
|
elif not final:
|
||||||
|
# Keep potentially unfinished label until the next call
|
||||||
|
del labels[-1]
|
||||||
|
if labels:
|
||||||
|
trailing_dot = b'.'
|
||||||
|
|
||||||
|
result = []
|
||||||
|
size = 0
|
||||||
|
for label in labels:
|
||||||
|
result.append(alabel(label))
|
||||||
|
if size:
|
||||||
|
size += 1
|
||||||
|
size += len(label)
|
||||||
|
|
||||||
|
# Join with U+002E
|
||||||
|
result_bytes = b'.'.join(result) + trailing_dot
|
||||||
|
size += len(trailing_dot)
|
||||||
|
return result_bytes, size
|
||||||
|
|
||||||
|
class IncrementalDecoder(codecs.BufferedIncrementalDecoder):
|
||||||
|
def _buffer_decode(self, data: Any, errors: str, final: bool) -> Tuple[str, int]:
|
||||||
|
if errors != 'strict':
|
||||||
|
raise IDNAError('Unsupported error handling \"{}\"'.format(errors))
|
||||||
|
|
||||||
|
if not data:
|
||||||
|
return ('', 0)
|
||||||
|
|
||||||
|
if not isinstance(data, str):
|
||||||
|
data = str(data, 'ascii')
|
||||||
|
|
||||||
|
labels = _unicode_dots_re.split(data)
|
||||||
|
trailing_dot = ''
|
||||||
|
if labels:
|
||||||
|
if not labels[-1]:
|
||||||
|
trailing_dot = '.'
|
||||||
|
del labels[-1]
|
||||||
|
elif not final:
|
||||||
|
# Keep potentially unfinished label until the next call
|
||||||
|
del labels[-1]
|
||||||
|
if labels:
|
||||||
|
trailing_dot = '.'
|
||||||
|
|
||||||
|
result = []
|
||||||
|
size = 0
|
||||||
|
for label in labels:
|
||||||
|
result.append(ulabel(label))
|
||||||
|
if size:
|
||||||
|
size += 1
|
||||||
|
size += len(label)
|
||||||
|
|
||||||
|
result_str = '.'.join(result) + trailing_dot
|
||||||
|
size += len(trailing_dot)
|
||||||
|
return (result_str, size)
|
||||||
|
|
||||||
|
|
||||||
|
class StreamWriter(Codec, codecs.StreamWriter):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class StreamReader(Codec, codecs.StreamReader):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
def search_function(name: str) -> Optional[codecs.CodecInfo]:
|
||||||
|
if name != 'idna2008':
|
||||||
|
return None
|
||||||
|
return codecs.CodecInfo(
|
||||||
|
name=name,
|
||||||
|
encode=Codec().encode,
|
||||||
|
decode=Codec().decode,
|
||||||
|
incrementalencoder=IncrementalEncoder,
|
||||||
|
incrementaldecoder=IncrementalDecoder,
|
||||||
|
streamwriter=StreamWriter,
|
||||||
|
streamreader=StreamReader,
|
||||||
|
)
|
||||||
|
|
||||||
|
codecs.register(search_function)
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
from .core import *
|
||||||
|
from .codec import *
|
||||||
|
from typing import Any, Union
|
||||||
|
|
||||||
|
def ToASCII(label: str) -> bytes:
|
||||||
|
return encode(label)
|
||||||
|
|
||||||
|
def ToUnicode(label: Union[bytes, bytearray]) -> str:
|
||||||
|
return decode(label)
|
||||||
|
|
||||||
|
def nameprep(s: Any) -> None:
|
||||||
|
raise NotImplementedError('IDNA 2008 does not utilise nameprep protocol')
|
||||||
|
|
||||||
|
|
@ -0,0 +1,400 @@
|
||||||
|
from . import idnadata
|
||||||
|
import bisect
|
||||||
|
import unicodedata
|
||||||
|
import re
|
||||||
|
from typing import Union, Optional
|
||||||
|
from .intranges import intranges_contain
|
||||||
|
|
||||||
|
_virama_combining_class = 9
|
||||||
|
_alabel_prefix = b'xn--'
|
||||||
|
_unicode_dots_re = re.compile('[\u002e\u3002\uff0e\uff61]')
|
||||||
|
|
||||||
|
class IDNAError(UnicodeError):
|
||||||
|
""" Base exception for all IDNA-encoding related problems """
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class IDNABidiError(IDNAError):
|
||||||
|
""" Exception when bidirectional requirements are not satisfied """
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidCodepoint(IDNAError):
|
||||||
|
""" Exception when a disallowed or unallocated codepoint is used """
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidCodepointContext(IDNAError):
|
||||||
|
""" Exception when the codepoint is not valid in the context it is used """
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
def _combining_class(cp: int) -> int:
|
||||||
|
v = unicodedata.combining(chr(cp))
|
||||||
|
if v == 0:
|
||||||
|
if not unicodedata.name(chr(cp)):
|
||||||
|
raise ValueError('Unknown character in unicodedata')
|
||||||
|
return v
|
||||||
|
|
||||||
|
def _is_script(cp: str, script: str) -> bool:
|
||||||
|
return intranges_contain(ord(cp), idnadata.scripts[script])
|
||||||
|
|
||||||
|
def _punycode(s: str) -> bytes:
|
||||||
|
return s.encode('punycode')
|
||||||
|
|
||||||
|
def _unot(s: int) -> str:
|
||||||
|
return 'U+{:04X}'.format(s)
|
||||||
|
|
||||||
|
|
||||||
|
def valid_label_length(label: Union[bytes, str]) -> bool:
|
||||||
|
if len(label) > 63:
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def valid_string_length(label: Union[bytes, str], trailing_dot: bool) -> bool:
|
||||||
|
if len(label) > (254 if trailing_dot else 253):
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def check_bidi(label: str, check_ltr: bool = False) -> bool:
|
||||||
|
# Bidi rules should only be applied if string contains RTL characters
|
||||||
|
bidi_label = False
|
||||||
|
for (idx, cp) in enumerate(label, 1):
|
||||||
|
direction = unicodedata.bidirectional(cp)
|
||||||
|
if direction == '':
|
||||||
|
# String likely comes from a newer version of Unicode
|
||||||
|
raise IDNABidiError('Unknown directionality in label {} at position {}'.format(repr(label), idx))
|
||||||
|
if direction in ['R', 'AL', 'AN']:
|
||||||
|
bidi_label = True
|
||||||
|
if not bidi_label and not check_ltr:
|
||||||
|
return True
|
||||||
|
|
||||||
|
# Bidi rule 1
|
||||||
|
direction = unicodedata.bidirectional(label[0])
|
||||||
|
if direction in ['R', 'AL']:
|
||||||
|
rtl = True
|
||||||
|
elif direction == 'L':
|
||||||
|
rtl = False
|
||||||
|
else:
|
||||||
|
raise IDNABidiError('First codepoint in label {} must be directionality L, R or AL'.format(repr(label)))
|
||||||
|
|
||||||
|
valid_ending = False
|
||||||
|
number_type = None # type: Optional[str]
|
||||||
|
for (idx, cp) in enumerate(label, 1):
|
||||||
|
direction = unicodedata.bidirectional(cp)
|
||||||
|
|
||||||
|
if rtl:
|
||||||
|
# Bidi rule 2
|
||||||
|
if not direction in ['R', 'AL', 'AN', 'EN', 'ES', 'CS', 'ET', 'ON', 'BN', 'NSM']:
|
||||||
|
raise IDNABidiError('Invalid direction for codepoint at position {} in a right-to-left label'.format(idx))
|
||||||
|
# Bidi rule 3
|
||||||
|
if direction in ['R', 'AL', 'EN', 'AN']:
|
||||||
|
valid_ending = True
|
||||||
|
elif direction != 'NSM':
|
||||||
|
valid_ending = False
|
||||||
|
# Bidi rule 4
|
||||||
|
if direction in ['AN', 'EN']:
|
||||||
|
if not number_type:
|
||||||
|
number_type = direction
|
||||||
|
else:
|
||||||
|
if number_type != direction:
|
||||||
|
raise IDNABidiError('Can not mix numeral types in a right-to-left label')
|
||||||
|
else:
|
||||||
|
# Bidi rule 5
|
||||||
|
if not direction in ['L', 'EN', 'ES', 'CS', 'ET', 'ON', 'BN', 'NSM']:
|
||||||
|
raise IDNABidiError('Invalid direction for codepoint at position {} in a left-to-right label'.format(idx))
|
||||||
|
# Bidi rule 6
|
||||||
|
if direction in ['L', 'EN']:
|
||||||
|
valid_ending = True
|
||||||
|
elif direction != 'NSM':
|
||||||
|
valid_ending = False
|
||||||
|
|
||||||
|
if not valid_ending:
|
||||||
|
raise IDNABidiError('Label ends with illegal codepoint directionality')
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def check_initial_combiner(label: str) -> bool:
|
||||||
|
if unicodedata.category(label[0])[0] == 'M':
|
||||||
|
raise IDNAError('Label begins with an illegal combining character')
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def check_hyphen_ok(label: str) -> bool:
|
||||||
|
if label[2:4] == '--':
|
||||||
|
raise IDNAError('Label has disallowed hyphens in 3rd and 4th position')
|
||||||
|
if label[0] == '-' or label[-1] == '-':
|
||||||
|
raise IDNAError('Label must not start or end with a hyphen')
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def check_nfc(label: str) -> None:
|
||||||
|
if unicodedata.normalize('NFC', label) != label:
|
||||||
|
raise IDNAError('Label must be in Normalization Form C')
|
||||||
|
|
||||||
|
|
||||||
|
def valid_contextj(label: str, pos: int) -> bool:
|
||||||
|
cp_value = ord(label[pos])
|
||||||
|
|
||||||
|
if cp_value == 0x200c:
|
||||||
|
|
||||||
|
if pos > 0:
|
||||||
|
if _combining_class(ord(label[pos - 1])) == _virama_combining_class:
|
||||||
|
return True
|
||||||
|
|
||||||
|
ok = False
|
||||||
|
for i in range(pos-1, -1, -1):
|
||||||
|
joining_type = idnadata.joining_types.get(ord(label[i]))
|
||||||
|
if joining_type == ord('T'):
|
||||||
|
continue
|
||||||
|
if joining_type in [ord('L'), ord('D')]:
|
||||||
|
ok = True
|
||||||
|
break
|
||||||
|
|
||||||
|
if not ok:
|
||||||
|
return False
|
||||||
|
|
||||||
|
ok = False
|
||||||
|
for i in range(pos+1, len(label)):
|
||||||
|
joining_type = idnadata.joining_types.get(ord(label[i]))
|
||||||
|
if joining_type == ord('T'):
|
||||||
|
continue
|
||||||
|
if joining_type in [ord('R'), ord('D')]:
|
||||||
|
ok = True
|
||||||
|
break
|
||||||
|
return ok
|
||||||
|
|
||||||
|
if cp_value == 0x200d:
|
||||||
|
|
||||||
|
if pos > 0:
|
||||||
|
if _combining_class(ord(label[pos - 1])) == _virama_combining_class:
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
else:
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def valid_contexto(label: str, pos: int, exception: bool = False) -> bool:
|
||||||
|
cp_value = ord(label[pos])
|
||||||
|
|
||||||
|
if cp_value == 0x00b7:
|
||||||
|
if 0 < pos < len(label)-1:
|
||||||
|
if ord(label[pos - 1]) == 0x006c and ord(label[pos + 1]) == 0x006c:
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
elif cp_value == 0x0375:
|
||||||
|
if pos < len(label)-1 and len(label) > 1:
|
||||||
|
return _is_script(label[pos + 1], 'Greek')
|
||||||
|
return False
|
||||||
|
|
||||||
|
elif cp_value == 0x05f3 or cp_value == 0x05f4:
|
||||||
|
if pos > 0:
|
||||||
|
return _is_script(label[pos - 1], 'Hebrew')
|
||||||
|
return False
|
||||||
|
|
||||||
|
elif cp_value == 0x30fb:
|
||||||
|
for cp in label:
|
||||||
|
if cp == '\u30fb':
|
||||||
|
continue
|
||||||
|
if _is_script(cp, 'Hiragana') or _is_script(cp, 'Katakana') or _is_script(cp, 'Han'):
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
elif 0x660 <= cp_value <= 0x669:
|
||||||
|
for cp in label:
|
||||||
|
if 0x6f0 <= ord(cp) <= 0x06f9:
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
elif 0x6f0 <= cp_value <= 0x6f9:
|
||||||
|
for cp in label:
|
||||||
|
if 0x660 <= ord(cp) <= 0x0669:
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def check_label(label: Union[str, bytes, bytearray]) -> None:
|
||||||
|
if isinstance(label, (bytes, bytearray)):
|
||||||
|
label = label.decode('utf-8')
|
||||||
|
if len(label) == 0:
|
||||||
|
raise IDNAError('Empty Label')
|
||||||
|
|
||||||
|
check_nfc(label)
|
||||||
|
check_hyphen_ok(label)
|
||||||
|
check_initial_combiner(label)
|
||||||
|
|
||||||
|
for (pos, cp) in enumerate(label):
|
||||||
|
cp_value = ord(cp)
|
||||||
|
if intranges_contain(cp_value, idnadata.codepoint_classes['PVALID']):
|
||||||
|
continue
|
||||||
|
elif intranges_contain(cp_value, idnadata.codepoint_classes['CONTEXTJ']):
|
||||||
|
try:
|
||||||
|
if not valid_contextj(label, pos):
|
||||||
|
raise InvalidCodepointContext('Joiner {} not allowed at position {} in {}'.format(
|
||||||
|
_unot(cp_value), pos+1, repr(label)))
|
||||||
|
except ValueError:
|
||||||
|
raise IDNAError('Unknown codepoint adjacent to joiner {} at position {} in {}'.format(
|
||||||
|
_unot(cp_value), pos+1, repr(label)))
|
||||||
|
elif intranges_contain(cp_value, idnadata.codepoint_classes['CONTEXTO']):
|
||||||
|
if not valid_contexto(label, pos):
|
||||||
|
raise InvalidCodepointContext('Codepoint {} not allowed at position {} in {}'.format(_unot(cp_value), pos+1, repr(label)))
|
||||||
|
else:
|
||||||
|
raise InvalidCodepoint('Codepoint {} at position {} of {} not allowed'.format(_unot(cp_value), pos+1, repr(label)))
|
||||||
|
|
||||||
|
check_bidi(label)
|
||||||
|
|
||||||
|
|
||||||
|
def alabel(label: str) -> bytes:
|
||||||
|
try:
|
||||||
|
label_bytes = label.encode('ascii')
|
||||||
|
ulabel(label_bytes)
|
||||||
|
if not valid_label_length(label_bytes):
|
||||||
|
raise IDNAError('Label too long')
|
||||||
|
return label_bytes
|
||||||
|
except UnicodeEncodeError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if not label:
|
||||||
|
raise IDNAError('No Input')
|
||||||
|
|
||||||
|
label = str(label)
|
||||||
|
check_label(label)
|
||||||
|
label_bytes = _punycode(label)
|
||||||
|
label_bytes = _alabel_prefix + label_bytes
|
||||||
|
|
||||||
|
if not valid_label_length(label_bytes):
|
||||||
|
raise IDNAError('Label too long')
|
||||||
|
|
||||||
|
return label_bytes
|
||||||
|
|
||||||
|
|
||||||
|
def ulabel(label: Union[str, bytes, bytearray]) -> str:
|
||||||
|
if not isinstance(label, (bytes, bytearray)):
|
||||||
|
try:
|
||||||
|
label_bytes = label.encode('ascii')
|
||||||
|
except UnicodeEncodeError:
|
||||||
|
check_label(label)
|
||||||
|
return label
|
||||||
|
else:
|
||||||
|
label_bytes = label
|
||||||
|
|
||||||
|
label_bytes = label_bytes.lower()
|
||||||
|
if label_bytes.startswith(_alabel_prefix):
|
||||||
|
label_bytes = label_bytes[len(_alabel_prefix):]
|
||||||
|
if not label_bytes:
|
||||||
|
raise IDNAError('Malformed A-label, no Punycode eligible content found')
|
||||||
|
if label_bytes.decode('ascii')[-1] == '-':
|
||||||
|
raise IDNAError('A-label must not end with a hyphen')
|
||||||
|
else:
|
||||||
|
check_label(label_bytes)
|
||||||
|
return label_bytes.decode('ascii')
|
||||||
|
|
||||||
|
try:
|
||||||
|
label = label_bytes.decode('punycode')
|
||||||
|
except UnicodeError:
|
||||||
|
raise IDNAError('Invalid A-label')
|
||||||
|
check_label(label)
|
||||||
|
return label
|
||||||
|
|
||||||
|
|
||||||
|
def uts46_remap(domain: str, std3_rules: bool = True, transitional: bool = False) -> str:
|
||||||
|
"""Re-map the characters in the string according to UTS46 processing."""
|
||||||
|
from .uts46data import uts46data
|
||||||
|
output = ''
|
||||||
|
|
||||||
|
for pos, char in enumerate(domain):
|
||||||
|
code_point = ord(char)
|
||||||
|
try:
|
||||||
|
uts46row = uts46data[code_point if code_point < 256 else
|
||||||
|
bisect.bisect_left(uts46data, (code_point, 'Z')) - 1]
|
||||||
|
status = uts46row[1]
|
||||||
|
replacement = None # type: Optional[str]
|
||||||
|
if len(uts46row) == 3:
|
||||||
|
replacement = uts46row[2]
|
||||||
|
if (status == 'V' or
|
||||||
|
(status == 'D' and not transitional) or
|
||||||
|
(status == '3' and not std3_rules and replacement is None)):
|
||||||
|
output += char
|
||||||
|
elif replacement is not None and (status == 'M' or
|
||||||
|
(status == '3' and not std3_rules) or
|
||||||
|
(status == 'D' and transitional)):
|
||||||
|
output += replacement
|
||||||
|
elif status != 'I':
|
||||||
|
raise IndexError()
|
||||||
|
except IndexError:
|
||||||
|
raise InvalidCodepoint(
|
||||||
|
'Codepoint {} not allowed at position {} in {}'.format(
|
||||||
|
_unot(code_point), pos + 1, repr(domain)))
|
||||||
|
|
||||||
|
return unicodedata.normalize('NFC', output)
|
||||||
|
|
||||||
|
|
||||||
|
def encode(s: Union[str, bytes, bytearray], strict: bool = False, uts46: bool = False, std3_rules: bool = False, transitional: bool = False) -> bytes:
|
||||||
|
if not isinstance(s, str):
|
||||||
|
try:
|
||||||
|
s = str(s, 'ascii')
|
||||||
|
except UnicodeDecodeError:
|
||||||
|
raise IDNAError('should pass a unicode string to the function rather than a byte string.')
|
||||||
|
if uts46:
|
||||||
|
s = uts46_remap(s, std3_rules, transitional)
|
||||||
|
trailing_dot = False
|
||||||
|
result = []
|
||||||
|
if strict:
|
||||||
|
labels = s.split('.')
|
||||||
|
else:
|
||||||
|
labels = _unicode_dots_re.split(s)
|
||||||
|
if not labels or labels == ['']:
|
||||||
|
raise IDNAError('Empty domain')
|
||||||
|
if labels[-1] == '':
|
||||||
|
del labels[-1]
|
||||||
|
trailing_dot = True
|
||||||
|
for label in labels:
|
||||||
|
s = alabel(label)
|
||||||
|
if s:
|
||||||
|
result.append(s)
|
||||||
|
else:
|
||||||
|
raise IDNAError('Empty label')
|
||||||
|
if trailing_dot:
|
||||||
|
result.append(b'')
|
||||||
|
s = b'.'.join(result)
|
||||||
|
if not valid_string_length(s, trailing_dot):
|
||||||
|
raise IDNAError('Domain too long')
|
||||||
|
return s
|
||||||
|
|
||||||
|
|
||||||
|
def decode(s: Union[str, bytes, bytearray], strict: bool = False, uts46: bool = False, std3_rules: bool = False) -> str:
|
||||||
|
try:
|
||||||
|
if not isinstance(s, str):
|
||||||
|
s = str(s, 'ascii')
|
||||||
|
except UnicodeDecodeError:
|
||||||
|
raise IDNAError('Invalid ASCII in A-label')
|
||||||
|
if uts46:
|
||||||
|
s = uts46_remap(s, std3_rules, False)
|
||||||
|
trailing_dot = False
|
||||||
|
result = []
|
||||||
|
if not strict:
|
||||||
|
labels = _unicode_dots_re.split(s)
|
||||||
|
else:
|
||||||
|
labels = s.split('.')
|
||||||
|
if not labels or labels == ['']:
|
||||||
|
raise IDNAError('Empty domain')
|
||||||
|
if not labels[-1]:
|
||||||
|
del labels[-1]
|
||||||
|
trailing_dot = True
|
||||||
|
for label in labels:
|
||||||
|
s = ulabel(label)
|
||||||
|
if s:
|
||||||
|
result.append(s)
|
||||||
|
else:
|
||||||
|
raise IDNAError('Empty label')
|
||||||
|
if trailing_dot:
|
||||||
|
result.append('')
|
||||||
|
return '.'.join(result)
|
||||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,54 @@
|
||||||
|
"""
|
||||||
|
Given a list of integers, made up of (hopefully) a small number of long runs
|
||||||
|
of consecutive integers, compute a representation of the form
|
||||||
|
((start1, end1), (start2, end2) ...). Then answer the question "was x present
|
||||||
|
in the original list?" in time O(log(# runs)).
|
||||||
|
"""
|
||||||
|
|
||||||
|
import bisect
|
||||||
|
from typing import List, Tuple
|
||||||
|
|
||||||
|
def intranges_from_list(list_: List[int]) -> Tuple[int, ...]:
|
||||||
|
"""Represent a list of integers as a sequence of ranges:
|
||||||
|
((start_0, end_0), (start_1, end_1), ...), such that the original
|
||||||
|
integers are exactly those x such that start_i <= x < end_i for some i.
|
||||||
|
|
||||||
|
Ranges are encoded as single integers (start << 32 | end), not as tuples.
|
||||||
|
"""
|
||||||
|
|
||||||
|
sorted_list = sorted(list_)
|
||||||
|
ranges = []
|
||||||
|
last_write = -1
|
||||||
|
for i in range(len(sorted_list)):
|
||||||
|
if i+1 < len(sorted_list):
|
||||||
|
if sorted_list[i] == sorted_list[i+1]-1:
|
||||||
|
continue
|
||||||
|
current_range = sorted_list[last_write+1:i+1]
|
||||||
|
ranges.append(_encode_range(current_range[0], current_range[-1] + 1))
|
||||||
|
last_write = i
|
||||||
|
|
||||||
|
return tuple(ranges)
|
||||||
|
|
||||||
|
def _encode_range(start: int, end: int) -> int:
|
||||||
|
return (start << 32) | end
|
||||||
|
|
||||||
|
def _decode_range(r: int) -> Tuple[int, int]:
|
||||||
|
return (r >> 32), (r & ((1 << 32) - 1))
|
||||||
|
|
||||||
|
|
||||||
|
def intranges_contain(int_: int, ranges: Tuple[int, ...]) -> bool:
|
||||||
|
"""Determine if `int_` falls into one of the ranges in `ranges`."""
|
||||||
|
tuple_ = _encode_range(int_, 0)
|
||||||
|
pos = bisect.bisect_left(ranges, tuple_)
|
||||||
|
# we could be immediately ahead of a tuple (start, end)
|
||||||
|
# with start < int_ <= end
|
||||||
|
if pos > 0:
|
||||||
|
left, right = _decode_range(ranges[pos-1])
|
||||||
|
if left <= int_ < right:
|
||||||
|
return True
|
||||||
|
# or we could be immediately behind a tuple (int_, end)
|
||||||
|
if pos < len(ranges):
|
||||||
|
left, _ = _decode_range(ranges[pos])
|
||||||
|
if left == int_:
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
@ -0,0 +1,2 @@
|
||||||
|
__version__ = '3.6'
|
||||||
|
|
||||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1 @@
|
||||||
|
pip
|
||||||
|
|
@ -0,0 +1,175 @@
|
||||||
|
|
||||||
|
Apache License
|
||||||
|
Version 2.0, January 2004
|
||||||
|
http://www.apache.org/licenses/
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||||
|
|
||||||
|
1. Definitions.
|
||||||
|
|
||||||
|
"License" shall mean the terms and conditions for use, reproduction,
|
||||||
|
and distribution as defined by Sections 1 through 9 of this document.
|
||||||
|
|
||||||
|
"Licensor" shall mean the copyright owner or entity authorized by
|
||||||
|
the copyright owner that is granting the License.
|
||||||
|
|
||||||
|
"Legal Entity" shall mean the union of the acting entity and all
|
||||||
|
other entities that control, are controlled by, or are under common
|
||||||
|
control with that entity. For the purposes of this definition,
|
||||||
|
"control" means (i) the power, direct or indirect, to cause the
|
||||||
|
direction or management of such entity, whether by contract or
|
||||||
|
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||||
|
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||||
|
|
||||||
|
"You" (or "Your") shall mean an individual or Legal Entity
|
||||||
|
exercising permissions granted by this License.
|
||||||
|
|
||||||
|
"Source" form shall mean the preferred form for making modifications,
|
||||||
|
including but not limited to software source code, documentation
|
||||||
|
source, and configuration files.
|
||||||
|
|
||||||
|
"Object" form shall mean any form resulting from mechanical
|
||||||
|
transformation or translation of a Source form, including but
|
||||||
|
not limited to compiled object code, generated documentation,
|
||||||
|
and conversions to other media types.
|
||||||
|
|
||||||
|
"Work" shall mean the work of authorship, whether in Source or
|
||||||
|
Object form, made available under the License, as indicated by a
|
||||||
|
copyright notice that is included in or attached to the work
|
||||||
|
(an example is provided in the Appendix below).
|
||||||
|
|
||||||
|
"Derivative Works" shall mean any work, whether in Source or Object
|
||||||
|
form, that is based on (or derived from) the Work and for which the
|
||||||
|
editorial revisions, annotations, elaborations, or other modifications
|
||||||
|
represent, as a whole, an original work of authorship. For the purposes
|
||||||
|
of this License, Derivative Works shall not include works that remain
|
||||||
|
separable from, or merely link (or bind by name) to the interfaces of,
|
||||||
|
the Work and Derivative Works thereof.
|
||||||
|
|
||||||
|
"Contribution" shall mean any work of authorship, including
|
||||||
|
the original version of the Work and any modifications or additions
|
||||||
|
to that Work or Derivative Works thereof, that is intentionally
|
||||||
|
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||||
|
or by an individual or Legal Entity authorized to submit on behalf of
|
||||||
|
the copyright owner. For the purposes of this definition, "submitted"
|
||||||
|
means any form of electronic, verbal, or written communication sent
|
||||||
|
to the Licensor or its representatives, including but not limited to
|
||||||
|
communication on electronic mailing lists, source code control systems,
|
||||||
|
and issue tracking systems that are managed by, or on behalf of, the
|
||||||
|
Licensor for the purpose of discussing and improving the Work, but
|
||||||
|
excluding communication that is conspicuously marked or otherwise
|
||||||
|
designated in writing by the copyright owner as "Not a Contribution."
|
||||||
|
|
||||||
|
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||||
|
on behalf of whom a Contribution has been received by Licensor and
|
||||||
|
subsequently incorporated within the Work.
|
||||||
|
|
||||||
|
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
copyright license to reproduce, prepare Derivative Works of,
|
||||||
|
publicly display, publicly perform, sublicense, and distribute the
|
||||||
|
Work and such Derivative Works in Source or Object form.
|
||||||
|
|
||||||
|
3. Grant of Patent License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
(except as stated in this section) patent license to make, have made,
|
||||||
|
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||||
|
where such license applies only to those patent claims licensable
|
||||||
|
by such Contributor that are necessarily infringed by their
|
||||||
|
Contribution(s) alone or by combination of their Contribution(s)
|
||||||
|
with the Work to which such Contribution(s) was submitted. If You
|
||||||
|
institute patent litigation against any entity (including a
|
||||||
|
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||||
|
or a Contribution incorporated within the Work constitutes direct
|
||||||
|
or contributory patent infringement, then any patent licenses
|
||||||
|
granted to You under this License for that Work shall terminate
|
||||||
|
as of the date such litigation is filed.
|
||||||
|
|
||||||
|
4. Redistribution. You may reproduce and distribute copies of the
|
||||||
|
Work or Derivative Works thereof in any medium, with or without
|
||||||
|
modifications, and in Source or Object form, provided that You
|
||||||
|
meet the following conditions:
|
||||||
|
|
||||||
|
(a) You must give any other recipients of the Work or
|
||||||
|
Derivative Works a copy of this License; and
|
||||||
|
|
||||||
|
(b) You must cause any modified files to carry prominent notices
|
||||||
|
stating that You changed the files; and
|
||||||
|
|
||||||
|
(c) You must retain, in the Source form of any Derivative Works
|
||||||
|
that You distribute, all copyright, patent, trademark, and
|
||||||
|
attribution notices from the Source form of the Work,
|
||||||
|
excluding those notices that do not pertain to any part of
|
||||||
|
the Derivative Works; and
|
||||||
|
|
||||||
|
(d) If the Work includes a "NOTICE" text file as part of its
|
||||||
|
distribution, then any Derivative Works that You distribute must
|
||||||
|
include a readable copy of the attribution notices contained
|
||||||
|
within such NOTICE file, excluding those notices that do not
|
||||||
|
pertain to any part of the Derivative Works, in at least one
|
||||||
|
of the following places: within a NOTICE text file distributed
|
||||||
|
as part of the Derivative Works; within the Source form or
|
||||||
|
documentation, if provided along with the Derivative Works; or,
|
||||||
|
within a display generated by the Derivative Works, if and
|
||||||
|
wherever such third-party notices normally appear. The contents
|
||||||
|
of the NOTICE file are for informational purposes only and
|
||||||
|
do not modify the License. You may add Your own attribution
|
||||||
|
notices within Derivative Works that You distribute, alongside
|
||||||
|
or as an addendum to the NOTICE text from the Work, provided
|
||||||
|
that such additional attribution notices cannot be construed
|
||||||
|
as modifying the License.
|
||||||
|
|
||||||
|
You may add Your own copyright statement to Your modifications and
|
||||||
|
may provide additional or different license terms and conditions
|
||||||
|
for use, reproduction, or distribution of Your modifications, or
|
||||||
|
for any such Derivative Works as a whole, provided Your use,
|
||||||
|
reproduction, and distribution of the Work otherwise complies with
|
||||||
|
the conditions stated in this License.
|
||||||
|
|
||||||
|
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||||
|
any Contribution intentionally submitted for inclusion in the Work
|
||||||
|
by You to the Licensor shall be under the terms and conditions of
|
||||||
|
this License, without any additional terms or conditions.
|
||||||
|
Notwithstanding the above, nothing herein shall supersede or modify
|
||||||
|
the terms of any separate license agreement you may have executed
|
||||||
|
with Licensor regarding such Contributions.
|
||||||
|
|
||||||
|
6. Trademarks. This License does not grant permission to use the trade
|
||||||
|
names, trademarks, service marks, or product names of the Licensor,
|
||||||
|
except as required for reasonable and customary use in describing the
|
||||||
|
origin of the Work and reproducing the content of the NOTICE file.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||||
|
agreed to in writing, Licensor provides the Work (and each
|
||||||
|
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||||
|
implied, including, without limitation, any warranties or conditions
|
||||||
|
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||||
|
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||||
|
appropriateness of using or redistributing the Work and assume any
|
||||||
|
risks associated with Your exercise of permissions under this License.
|
||||||
|
|
||||||
|
8. Limitation of Liability. In no event and under no legal theory,
|
||||||
|
whether in tort (including negligence), contract, or otherwise,
|
||||||
|
unless required by applicable law (such as deliberate and grossly
|
||||||
|
negligent acts) or agreed to in writing, shall any Contributor be
|
||||||
|
liable to You for damages, including any direct, indirect, special,
|
||||||
|
incidental, or consequential damages of any character arising as a
|
||||||
|
result of this License or out of the use or inability to use the
|
||||||
|
Work (including but not limited to damages for loss of goodwill,
|
||||||
|
work stoppage, computer failure or malfunction, or any and all
|
||||||
|
other commercial damages or losses), even if such Contributor
|
||||||
|
has been advised of the possibility of such damages.
|
||||||
|
|
||||||
|
9. Accepting Warranty or Additional Liability. While redistributing
|
||||||
|
the Work or Derivative Works thereof, You may choose to offer,
|
||||||
|
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||||
|
or other liability obligations and/or rights consistent with this
|
||||||
|
License. However, in accepting such obligations, You may act only
|
||||||
|
on Your own behalf and on Your sole responsibility, not on behalf
|
||||||
|
of any other Contributor, and only if You agree to indemnify,
|
||||||
|
defend, and hold each Contributor harmless for any liability
|
||||||
|
incurred by, or claims asserted against, such Contributor by reason
|
||||||
|
of your accepting any such warranty or additional liability.
|
||||||
|
|
@ -0,0 +1,122 @@
|
||||||
|
Metadata-Version: 2.1
|
||||||
|
Name: requests
|
||||||
|
Version: 2.31.0
|
||||||
|
Summary: Python HTTP for Humans.
|
||||||
|
Home-page: https://requests.readthedocs.io
|
||||||
|
Author: Kenneth Reitz
|
||||||
|
Author-email: me@kennethreitz.org
|
||||||
|
License: Apache 2.0
|
||||||
|
Project-URL: Documentation, https://requests.readthedocs.io
|
||||||
|
Project-URL: Source, https://github.com/psf/requests
|
||||||
|
Platform: UNKNOWN
|
||||||
|
Classifier: Development Status :: 5 - Production/Stable
|
||||||
|
Classifier: Environment :: Web Environment
|
||||||
|
Classifier: Intended Audience :: Developers
|
||||||
|
Classifier: License :: OSI Approved :: Apache Software License
|
||||||
|
Classifier: Natural Language :: English
|
||||||
|
Classifier: Operating System :: OS Independent
|
||||||
|
Classifier: Programming Language :: Python
|
||||||
|
Classifier: Programming Language :: Python :: 3
|
||||||
|
Classifier: Programming Language :: Python :: 3.7
|
||||||
|
Classifier: Programming Language :: Python :: 3.8
|
||||||
|
Classifier: Programming Language :: Python :: 3.9
|
||||||
|
Classifier: Programming Language :: Python :: 3.10
|
||||||
|
Classifier: Programming Language :: Python :: 3.11
|
||||||
|
Classifier: Programming Language :: Python :: 3 :: Only
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: CPython
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
||||||
|
Classifier: Topic :: Internet :: WWW/HTTP
|
||||||
|
Classifier: Topic :: Software Development :: Libraries
|
||||||
|
Requires-Python: >=3.7
|
||||||
|
Description-Content-Type: text/markdown
|
||||||
|
License-File: LICENSE
|
||||||
|
Requires-Dist: charset-normalizer (<4,>=2)
|
||||||
|
Requires-Dist: idna (<4,>=2.5)
|
||||||
|
Requires-Dist: urllib3 (<3,>=1.21.1)
|
||||||
|
Requires-Dist: certifi (>=2017.4.17)
|
||||||
|
Provides-Extra: security
|
||||||
|
Provides-Extra: socks
|
||||||
|
Requires-Dist: PySocks (!=1.5.7,>=1.5.6) ; extra == 'socks'
|
||||||
|
Provides-Extra: use_chardet_on_py3
|
||||||
|
Requires-Dist: chardet (<6,>=3.0.2) ; extra == 'use_chardet_on_py3'
|
||||||
|
|
||||||
|
# Requests
|
||||||
|
|
||||||
|
**Requests** is a simple, yet elegant, HTTP library.
|
||||||
|
|
||||||
|
```python
|
||||||
|
>>> import requests
|
||||||
|
>>> r = requests.get('https://httpbin.org/basic-auth/user/pass', auth=('user', 'pass'))
|
||||||
|
>>> r.status_code
|
||||||
|
200
|
||||||
|
>>> r.headers['content-type']
|
||||||
|
'application/json; charset=utf8'
|
||||||
|
>>> r.encoding
|
||||||
|
'utf-8'
|
||||||
|
>>> r.text
|
||||||
|
'{"authenticated": true, ...'
|
||||||
|
>>> r.json()
|
||||||
|
{'authenticated': True, ...}
|
||||||
|
```
|
||||||
|
|
||||||
|
Requests allows you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs, or to form-encode your `PUT` & `POST` data — but nowadays, just use the `json` method!
|
||||||
|
|
||||||
|
Requests is one of the most downloaded Python packages today, pulling in around `30M downloads / week`— according to GitHub, Requests is currently [depended upon](https://github.com/psf/requests/network/dependents?package_id=UGFja2FnZS01NzA4OTExNg%3D%3D) by `1,000,000+` repositories. You may certainly put your trust in this code.
|
||||||
|
|
||||||
|
[](https://pepy.tech/project/requests)
|
||||||
|
[](https://pypi.org/project/requests)
|
||||||
|
[](https://github.com/psf/requests/graphs/contributors)
|
||||||
|
|
||||||
|
## Installing Requests and Supported Versions
|
||||||
|
|
||||||
|
Requests is available on PyPI:
|
||||||
|
|
||||||
|
```console
|
||||||
|
$ python -m pip install requests
|
||||||
|
```
|
||||||
|
|
||||||
|
Requests officially supports Python 3.7+.
|
||||||
|
|
||||||
|
## Supported Features & Best–Practices
|
||||||
|
|
||||||
|
Requests is ready for the demands of building robust and reliable HTTP–speaking applications, for the needs of today.
|
||||||
|
|
||||||
|
- Keep-Alive & Connection Pooling
|
||||||
|
- International Domains and URLs
|
||||||
|
- Sessions with Cookie Persistence
|
||||||
|
- Browser-style TLS/SSL Verification
|
||||||
|
- Basic & Digest Authentication
|
||||||
|
- Familiar `dict`–like Cookies
|
||||||
|
- Automatic Content Decompression and Decoding
|
||||||
|
- Multi-part File Uploads
|
||||||
|
- SOCKS Proxy Support
|
||||||
|
- Connection Timeouts
|
||||||
|
- Streaming Downloads
|
||||||
|
- Automatic honoring of `.netrc`
|
||||||
|
- Chunked HTTP Requests
|
||||||
|
|
||||||
|
## API Reference and User Guide available on [Read the Docs](https://requests.readthedocs.io)
|
||||||
|
|
||||||
|
[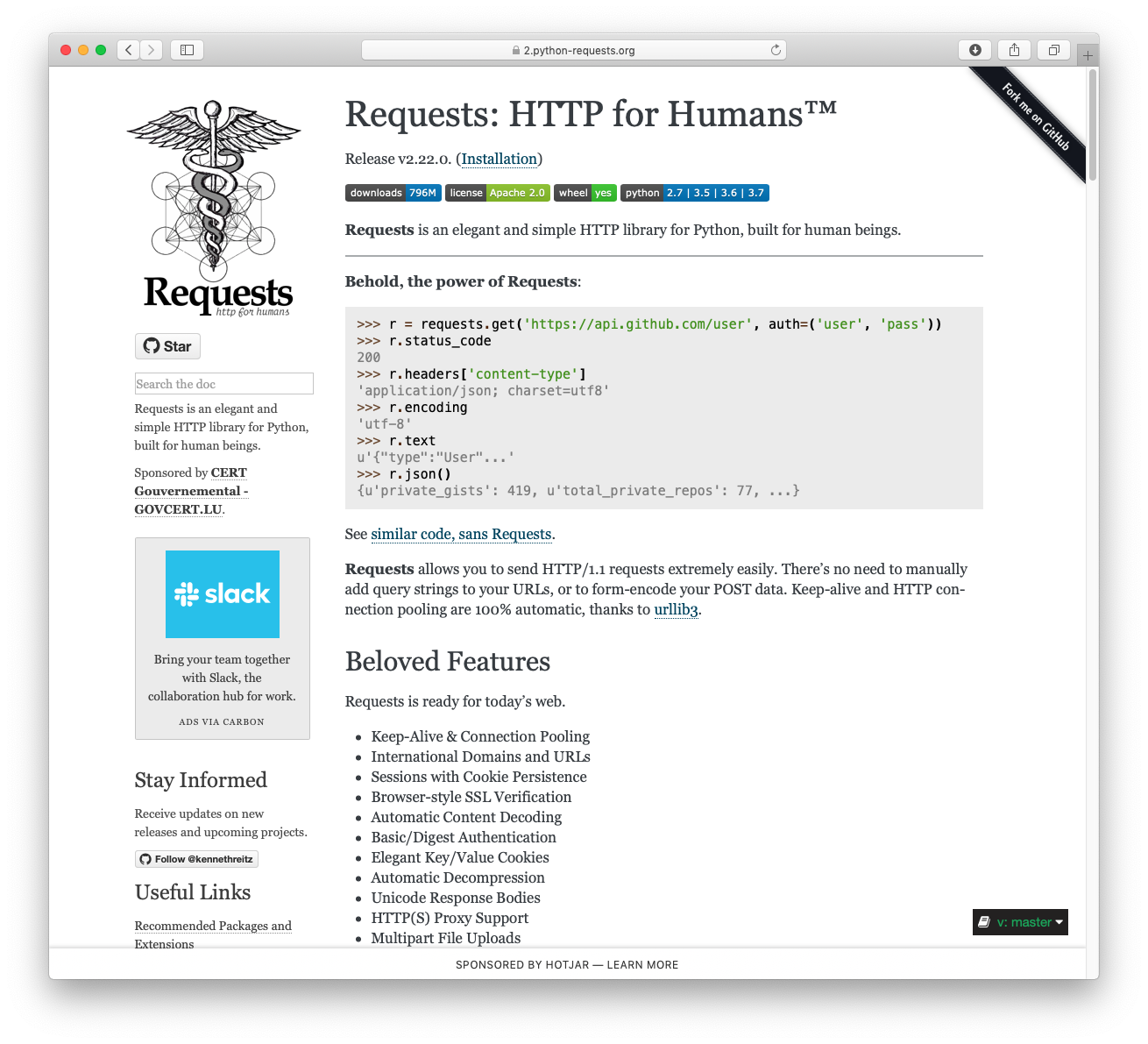](https://requests.readthedocs.io)
|
||||||
|
|
||||||
|
## Cloning the repository
|
||||||
|
|
||||||
|
When cloning the Requests repository, you may need to add the `-c
|
||||||
|
fetch.fsck.badTimezone=ignore` flag to avoid an error about a bad commit (see
|
||||||
|
[this issue](https://github.com/psf/requests/issues/2690) for more background):
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git clone -c fetch.fsck.badTimezone=ignore https://github.com/psf/requests.git
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also apply this setting to your global Git config:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git config --global fetch.fsck.badTimezone ignore
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
[](https://kennethreitz.org) [](https://www.python.org/psf)
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -0,0 +1,43 @@
|
||||||
|
requests-2.31.0.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
||||||
|
requests-2.31.0.dist-info/LICENSE,sha256=CeipvOyAZxBGUsFoaFqwkx54aPnIKEtm9a5u2uXxEws,10142
|
||||||
|
requests-2.31.0.dist-info/METADATA,sha256=eCPokOnbb0FROLrfl0R5EpDvdufsb9CaN4noJH__54I,4634
|
||||||
|
requests-2.31.0.dist-info/RECORD,,
|
||||||
|
requests-2.31.0.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
||||||
|
requests-2.31.0.dist-info/WHEEL,sha256=pkctZYzUS4AYVn6dJ-7367OJZivF2e8RA9b_ZBjif18,92
|
||||||
|
requests-2.31.0.dist-info/top_level.txt,sha256=fMSVmHfb5rbGOo6xv-O_tUX6j-WyixssE-SnwcDRxNQ,9
|
||||||
|
requests/__init__.py,sha256=LvmKhjIz8mHaKXthC2Mv5ykZ1d92voyf3oJpd-VuAig,4963
|
||||||
|
requests/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/__version__.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/_internal_utils.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/adapters.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/api.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/auth.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/certs.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/compat.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/cookies.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/exceptions.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/help.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/hooks.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/models.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/packages.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/sessions.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/status_codes.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/structures.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/utils.cpython-312.pyc,,
|
||||||
|
requests/__version__.py,sha256=ssI3Ezt7PaxgkOW45GhtwPUclo_SO_ygtIm4A74IOfw,435
|
||||||
|
requests/_internal_utils.py,sha256=nMQymr4hs32TqVo5AbCrmcJEhvPUh7xXlluyqwslLiQ,1495
|
||||||
|
requests/adapters.py,sha256=v_FmjU5KZ76k-YttShZYB5RprIzhhL8Y3zgW9p4eBQ8,19553
|
||||||
|
requests/api.py,sha256=q61xcXq4tmiImrvcSVLTbFyCiD2F-L_-hWKGbz4y8vg,6449
|
||||||
|
requests/auth.py,sha256=h-HLlVx9j8rKV5hfSAycP2ApOSglTz77R0tz7qCbbEE,10187
|
||||||
|
requests/certs.py,sha256=Z9Sb410Anv6jUFTyss0jFFhU6xst8ctELqfy8Ev23gw,429
|
||||||
|
requests/compat.py,sha256=yxntVOSEHGMrn7FNr_32EEam1ZNAdPRdSE13_yaHzTk,1451
|
||||||
|
requests/cookies.py,sha256=kD3kNEcCj-mxbtf5fJsSaT86eGoEYpD3X0CSgpzl7BM,18560
|
||||||
|
requests/exceptions.py,sha256=DhveFBclVjTRxhRduVpO-GbMYMID2gmjdLfNEqNpI_U,3811
|
||||||
|
requests/help.py,sha256=gPX5d_H7Xd88aDABejhqGgl9B1VFRTt5BmiYvL3PzIQ,3875
|
||||||
|
requests/hooks.py,sha256=CiuysiHA39V5UfcCBXFIx83IrDpuwfN9RcTUgv28ftQ,733
|
||||||
|
requests/models.py,sha256=-DlKi0or8gFAM6VzutobXvvBW_2wrJuOF5NfndTIddA,35223
|
||||||
|
requests/packages.py,sha256=DXgv-FJIczZITmv0vEBAhWj4W-5CGCIN_ksvgR17Dvs,957
|
||||||
|
requests/sessions.py,sha256=-LvTzrPtetSTrR3buxu4XhdgMrJFLB1q5D7P--L2Xhw,30373
|
||||||
|
requests/status_codes.py,sha256=FvHmT5uH-_uimtRz5hH9VCbt7VV-Nei2J9upbej6j8g,4235
|
||||||
|
requests/structures.py,sha256=-IbmhVz06S-5aPSZuUthZ6-6D9XOjRuTXHOabY041XM,2912
|
||||||
|
requests/utils.py,sha256=6sx2X3cIVA8BgWOg8odxFy-_lbWDFETU8HI4fU4Rmqw,33448
|
||||||
|
|
@ -0,0 +1,5 @@
|
||||||
|
Wheel-Version: 1.0
|
||||||
|
Generator: bdist_wheel (0.40.0)
|
||||||
|
Root-Is-Purelib: true
|
||||||
|
Tag: py3-none-any
|
||||||
|
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
requests
|
||||||
|
|
@ -0,0 +1,180 @@
|
||||||
|
# __
|
||||||
|
# /__) _ _ _ _ _/ _
|
||||||
|
# / ( (- (/ (/ (- _) / _)
|
||||||
|
# /
|
||||||
|
|
||||||
|
"""
|
||||||
|
Requests HTTP Library
|
||||||
|
~~~~~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
Requests is an HTTP library, written in Python, for human beings.
|
||||||
|
Basic GET usage:
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> r = requests.get('https://www.python.org')
|
||||||
|
>>> r.status_code
|
||||||
|
200
|
||||||
|
>>> b'Python is a programming language' in r.content
|
||||||
|
True
|
||||||
|
|
||||||
|
... or POST:
|
||||||
|
|
||||||
|
>>> payload = dict(key1='value1', key2='value2')
|
||||||
|
>>> r = requests.post('https://httpbin.org/post', data=payload)
|
||||||
|
>>> print(r.text)
|
||||||
|
{
|
||||||
|
...
|
||||||
|
"form": {
|
||||||
|
"key1": "value1",
|
||||||
|
"key2": "value2"
|
||||||
|
},
|
||||||
|
...
|
||||||
|
}
|
||||||
|
|
||||||
|
The other HTTP methods are supported - see `requests.api`. Full documentation
|
||||||
|
is at <https://requests.readthedocs.io>.
|
||||||
|
|
||||||
|
:copyright: (c) 2017 by Kenneth Reitz.
|
||||||
|
:license: Apache 2.0, see LICENSE for more details.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
from .exceptions import RequestsDependencyWarning
|
||||||
|
|
||||||
|
try:
|
||||||
|
from charset_normalizer import __version__ as charset_normalizer_version
|
||||||
|
except ImportError:
|
||||||
|
charset_normalizer_version = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
from chardet import __version__ as chardet_version
|
||||||
|
except ImportError:
|
||||||
|
chardet_version = None
|
||||||
|
|
||||||
|
|
||||||
|
def check_compatibility(urllib3_version, chardet_version, charset_normalizer_version):
|
||||||
|
urllib3_version = urllib3_version.split(".")
|
||||||
|
assert urllib3_version != ["dev"] # Verify urllib3 isn't installed from git.
|
||||||
|
|
||||||
|
# Sometimes, urllib3 only reports its version as 16.1.
|
||||||
|
if len(urllib3_version) == 2:
|
||||||
|
urllib3_version.append("0")
|
||||||
|
|
||||||
|
# Check urllib3 for compatibility.
|
||||||
|
major, minor, patch = urllib3_version # noqa: F811
|
||||||
|
major, minor, patch = int(major), int(minor), int(patch)
|
||||||
|
# urllib3 >= 1.21.1
|
||||||
|
assert major >= 1
|
||||||
|
if major == 1:
|
||||||
|
assert minor >= 21
|
||||||
|
|
||||||
|
# Check charset_normalizer for compatibility.
|
||||||
|
if chardet_version:
|
||||||
|
major, minor, patch = chardet_version.split(".")[:3]
|
||||||
|
major, minor, patch = int(major), int(minor), int(patch)
|
||||||
|
# chardet_version >= 3.0.2, < 6.0.0
|
||||||
|
assert (3, 0, 2) <= (major, minor, patch) < (6, 0, 0)
|
||||||
|
elif charset_normalizer_version:
|
||||||
|
major, minor, patch = charset_normalizer_version.split(".")[:3]
|
||||||
|
major, minor, patch = int(major), int(minor), int(patch)
|
||||||
|
# charset_normalizer >= 2.0.0 < 4.0.0
|
||||||
|
assert (2, 0, 0) <= (major, minor, patch) < (4, 0, 0)
|
||||||
|
else:
|
||||||
|
raise Exception("You need either charset_normalizer or chardet installed")
|
||||||
|
|
||||||
|
|
||||||
|
def _check_cryptography(cryptography_version):
|
||||||
|
# cryptography < 1.3.4
|
||||||
|
try:
|
||||||
|
cryptography_version = list(map(int, cryptography_version.split(".")))
|
||||||
|
except ValueError:
|
||||||
|
return
|
||||||
|
|
||||||
|
if cryptography_version < [1, 3, 4]:
|
||||||
|
warning = "Old version of cryptography ({}) may cause slowdown.".format(
|
||||||
|
cryptography_version
|
||||||
|
)
|
||||||
|
warnings.warn(warning, RequestsDependencyWarning)
|
||||||
|
|
||||||
|
|
||||||
|
# Check imported dependencies for compatibility.
|
||||||
|
try:
|
||||||
|
check_compatibility(
|
||||||
|
urllib3.__version__, chardet_version, charset_normalizer_version
|
||||||
|
)
|
||||||
|
except (AssertionError, ValueError):
|
||||||
|
warnings.warn(
|
||||||
|
"urllib3 ({}) or chardet ({})/charset_normalizer ({}) doesn't match a supported "
|
||||||
|
"version!".format(
|
||||||
|
urllib3.__version__, chardet_version, charset_normalizer_version
|
||||||
|
),
|
||||||
|
RequestsDependencyWarning,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Attempt to enable urllib3's fallback for SNI support
|
||||||
|
# if the standard library doesn't support SNI or the
|
||||||
|
# 'ssl' library isn't available.
|
||||||
|
try:
|
||||||
|
try:
|
||||||
|
import ssl
|
||||||
|
except ImportError:
|
||||||
|
ssl = None
|
||||||
|
|
||||||
|
if not getattr(ssl, "HAS_SNI", False):
|
||||||
|
from urllib3.contrib import pyopenssl
|
||||||
|
|
||||||
|
pyopenssl.inject_into_urllib3()
|
||||||
|
|
||||||
|
# Check cryptography version
|
||||||
|
from cryptography import __version__ as cryptography_version
|
||||||
|
|
||||||
|
_check_cryptography(cryptography_version)
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# urllib3's DependencyWarnings should be silenced.
|
||||||
|
from urllib3.exceptions import DependencyWarning
|
||||||
|
|
||||||
|
warnings.simplefilter("ignore", DependencyWarning)
|
||||||
|
|
||||||
|
# Set default logging handler to avoid "No handler found" warnings.
|
||||||
|
import logging
|
||||||
|
from logging import NullHandler
|
||||||
|
|
||||||
|
from . import packages, utils
|
||||||
|
from .__version__ import (
|
||||||
|
__author__,
|
||||||
|
__author_email__,
|
||||||
|
__build__,
|
||||||
|
__cake__,
|
||||||
|
__copyright__,
|
||||||
|
__description__,
|
||||||
|
__license__,
|
||||||
|
__title__,
|
||||||
|
__url__,
|
||||||
|
__version__,
|
||||||
|
)
|
||||||
|
from .api import delete, get, head, options, patch, post, put, request
|
||||||
|
from .exceptions import (
|
||||||
|
ConnectionError,
|
||||||
|
ConnectTimeout,
|
||||||
|
FileModeWarning,
|
||||||
|
HTTPError,
|
||||||
|
JSONDecodeError,
|
||||||
|
ReadTimeout,
|
||||||
|
RequestException,
|
||||||
|
Timeout,
|
||||||
|
TooManyRedirects,
|
||||||
|
URLRequired,
|
||||||
|
)
|
||||||
|
from .models import PreparedRequest, Request, Response
|
||||||
|
from .sessions import Session, session
|
||||||
|
from .status_codes import codes
|
||||||
|
|
||||||
|
logging.getLogger(__name__).addHandler(NullHandler())
|
||||||
|
|
||||||
|
# FileModeWarnings go off per the default.
|
||||||
|
warnings.simplefilter("default", FileModeWarning, append=True)
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
# .-. .-. .-. . . .-. .-. .-. .-.
|
||||||
|
# |( |- |.| | | |- `-. | `-.
|
||||||
|
# ' ' `-' `-`.`-' `-' `-' ' `-'
|
||||||
|
|
||||||
|
__title__ = "requests"
|
||||||
|
__description__ = "Python HTTP for Humans."
|
||||||
|
__url__ = "https://requests.readthedocs.io"
|
||||||
|
__version__ = "2.31.0"
|
||||||
|
__build__ = 0x023100
|
||||||
|
__author__ = "Kenneth Reitz"
|
||||||
|
__author_email__ = "me@kennethreitz.org"
|
||||||
|
__license__ = "Apache 2.0"
|
||||||
|
__copyright__ = "Copyright Kenneth Reitz"
|
||||||
|
__cake__ = "\u2728 \U0001f370 \u2728"
|
||||||
|
|
@ -0,0 +1,50 @@
|
||||||
|
"""
|
||||||
|
requests._internal_utils
|
||||||
|
~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
Provides utility functions that are consumed internally by Requests
|
||||||
|
which depend on extremely few external helpers (such as compat)
|
||||||
|
"""
|
||||||
|
import re
|
||||||
|
|
||||||
|
from .compat import builtin_str
|
||||||
|
|
||||||
|
_VALID_HEADER_NAME_RE_BYTE = re.compile(rb"^[^:\s][^:\r\n]*$")
|
||||||
|
_VALID_HEADER_NAME_RE_STR = re.compile(r"^[^:\s][^:\r\n]*$")
|
||||||
|
_VALID_HEADER_VALUE_RE_BYTE = re.compile(rb"^\S[^\r\n]*$|^$")
|
||||||
|
_VALID_HEADER_VALUE_RE_STR = re.compile(r"^\S[^\r\n]*$|^$")
|
||||||
|
|
||||||
|
_HEADER_VALIDATORS_STR = (_VALID_HEADER_NAME_RE_STR, _VALID_HEADER_VALUE_RE_STR)
|
||||||
|
_HEADER_VALIDATORS_BYTE = (_VALID_HEADER_NAME_RE_BYTE, _VALID_HEADER_VALUE_RE_BYTE)
|
||||||
|
HEADER_VALIDATORS = {
|
||||||
|
bytes: _HEADER_VALIDATORS_BYTE,
|
||||||
|
str: _HEADER_VALIDATORS_STR,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def to_native_string(string, encoding="ascii"):
|
||||||
|
"""Given a string object, regardless of type, returns a representation of
|
||||||
|
that string in the native string type, encoding and decoding where
|
||||||
|
necessary. This assumes ASCII unless told otherwise.
|
||||||
|
"""
|
||||||
|
if isinstance(string, builtin_str):
|
||||||
|
out = string
|
||||||
|
else:
|
||||||
|
out = string.decode(encoding)
|
||||||
|
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
def unicode_is_ascii(u_string):
|
||||||
|
"""Determine if unicode string only contains ASCII characters.
|
||||||
|
|
||||||
|
:param str u_string: unicode string to check. Must be unicode
|
||||||
|
and not Python 2 `str`.
|
||||||
|
:rtype: bool
|
||||||
|
"""
|
||||||
|
assert isinstance(u_string, str)
|
||||||
|
try:
|
||||||
|
u_string.encode("ascii")
|
||||||
|
return True
|
||||||
|
except UnicodeEncodeError:
|
||||||
|
return False
|
||||||
|
|
@ -0,0 +1,538 @@
|
||||||
|
"""
|
||||||
|
requests.adapters
|
||||||
|
~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module contains the transport adapters that Requests uses to define
|
||||||
|
and maintain connections.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import os.path
|
||||||
|
import socket # noqa: F401
|
||||||
|
|
||||||
|
from urllib3.exceptions import ClosedPoolError, ConnectTimeoutError
|
||||||
|
from urllib3.exceptions import HTTPError as _HTTPError
|
||||||
|
from urllib3.exceptions import InvalidHeader as _InvalidHeader
|
||||||
|
from urllib3.exceptions import (
|
||||||
|
LocationValueError,
|
||||||
|
MaxRetryError,
|
||||||
|
NewConnectionError,
|
||||||
|
ProtocolError,
|
||||||
|
)
|
||||||
|
from urllib3.exceptions import ProxyError as _ProxyError
|
||||||
|
from urllib3.exceptions import ReadTimeoutError, ResponseError
|
||||||
|
from urllib3.exceptions import SSLError as _SSLError
|
||||||
|
from urllib3.poolmanager import PoolManager, proxy_from_url
|
||||||
|
from urllib3.util import Timeout as TimeoutSauce
|
||||||
|
from urllib3.util import parse_url
|
||||||
|
from urllib3.util.retry import Retry
|
||||||
|
|
||||||
|
from .auth import _basic_auth_str
|
||||||
|
from .compat import basestring, urlparse
|
||||||
|
from .cookies import extract_cookies_to_jar
|
||||||
|
from .exceptions import (
|
||||||
|
ConnectionError,
|
||||||
|
ConnectTimeout,
|
||||||
|
InvalidHeader,
|
||||||
|
InvalidProxyURL,
|
||||||
|
InvalidSchema,
|
||||||
|
InvalidURL,
|
||||||
|
ProxyError,
|
||||||
|
ReadTimeout,
|
||||||
|
RetryError,
|
||||||
|
SSLError,
|
||||||
|
)
|
||||||
|
from .models import Response
|
||||||
|
from .structures import CaseInsensitiveDict
|
||||||
|
from .utils import (
|
||||||
|
DEFAULT_CA_BUNDLE_PATH,
|
||||||
|
extract_zipped_paths,
|
||||||
|
get_auth_from_url,
|
||||||
|
get_encoding_from_headers,
|
||||||
|
prepend_scheme_if_needed,
|
||||||
|
select_proxy,
|
||||||
|
urldefragauth,
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
from urllib3.contrib.socks import SOCKSProxyManager
|
||||||
|
except ImportError:
|
||||||
|
|
||||||
|
def SOCKSProxyManager(*args, **kwargs):
|
||||||
|
raise InvalidSchema("Missing dependencies for SOCKS support.")
|
||||||
|
|
||||||
|
|
||||||
|
DEFAULT_POOLBLOCK = False
|
||||||
|
DEFAULT_POOLSIZE = 10
|
||||||
|
DEFAULT_RETRIES = 0
|
||||||
|
DEFAULT_POOL_TIMEOUT = None
|
||||||
|
|
||||||
|
|
||||||
|
class BaseAdapter:
|
||||||
|
"""The Base Transport Adapter"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
def send(
|
||||||
|
self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None
|
||||||
|
):
|
||||||
|
"""Sends PreparedRequest object. Returns Response object.
|
||||||
|
|
||||||
|
:param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
|
||||||
|
:param stream: (optional) Whether to stream the request content.
|
||||||
|
:param timeout: (optional) How long to wait for the server to send
|
||||||
|
data before giving up, as a float, or a :ref:`(connect timeout,
|
||||||
|
read timeout) <timeouts>` tuple.
|
||||||
|
:type timeout: float or tuple
|
||||||
|
:param verify: (optional) Either a boolean, in which case it controls whether we verify
|
||||||
|
the server's TLS certificate, or a string, in which case it must be a path
|
||||||
|
to a CA bundle to use
|
||||||
|
:param cert: (optional) Any user-provided SSL certificate to be trusted.
|
||||||
|
:param proxies: (optional) The proxies dictionary to apply to the request.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
"""Cleans up adapter specific items."""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPAdapter(BaseAdapter):
|
||||||
|
"""The built-in HTTP Adapter for urllib3.
|
||||||
|
|
||||||
|
Provides a general-case interface for Requests sessions to contact HTTP and
|
||||||
|
HTTPS urls by implementing the Transport Adapter interface. This class will
|
||||||
|
usually be created by the :class:`Session <Session>` class under the
|
||||||
|
covers.
|
||||||
|
|
||||||
|
:param pool_connections: The number of urllib3 connection pools to cache.
|
||||||
|
:param pool_maxsize: The maximum number of connections to save in the pool.
|
||||||
|
:param max_retries: The maximum number of retries each connection
|
||||||
|
should attempt. Note, this applies only to failed DNS lookups, socket
|
||||||
|
connections and connection timeouts, never to requests where data has
|
||||||
|
made it to the server. By default, Requests does not retry failed
|
||||||
|
connections. If you need granular control over the conditions under
|
||||||
|
which we retry a request, import urllib3's ``Retry`` class and pass
|
||||||
|
that instead.
|
||||||
|
:param pool_block: Whether the connection pool should block for connections.
|
||||||
|
|
||||||
|
Usage::
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> s = requests.Session()
|
||||||
|
>>> a = requests.adapters.HTTPAdapter(max_retries=3)
|
||||||
|
>>> s.mount('http://', a)
|
||||||
|
"""
|
||||||
|
|
||||||
|
__attrs__ = [
|
||||||
|
"max_retries",
|
||||||
|
"config",
|
||||||
|
"_pool_connections",
|
||||||
|
"_pool_maxsize",
|
||||||
|
"_pool_block",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
pool_connections=DEFAULT_POOLSIZE,
|
||||||
|
pool_maxsize=DEFAULT_POOLSIZE,
|
||||||
|
max_retries=DEFAULT_RETRIES,
|
||||||
|
pool_block=DEFAULT_POOLBLOCK,
|
||||||
|
):
|
||||||
|
if max_retries == DEFAULT_RETRIES:
|
||||||
|
self.max_retries = Retry(0, read=False)
|
||||||
|
else:
|
||||||
|
self.max_retries = Retry.from_int(max_retries)
|
||||||
|
self.config = {}
|
||||||
|
self.proxy_manager = {}
|
||||||
|
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
self._pool_connections = pool_connections
|
||||||
|
self._pool_maxsize = pool_maxsize
|
||||||
|
self._pool_block = pool_block
|
||||||
|
|
||||||
|
self.init_poolmanager(pool_connections, pool_maxsize, block=pool_block)
|
||||||
|
|
||||||
|
def __getstate__(self):
|
||||||
|
return {attr: getattr(self, attr, None) for attr in self.__attrs__}
|
||||||
|
|
||||||
|
def __setstate__(self, state):
|
||||||
|
# Can't handle by adding 'proxy_manager' to self.__attrs__ because
|
||||||
|
# self.poolmanager uses a lambda function, which isn't pickleable.
|
||||||
|
self.proxy_manager = {}
|
||||||
|
self.config = {}
|
||||||
|
|
||||||
|
for attr, value in state.items():
|
||||||
|
setattr(self, attr, value)
|
||||||
|
|
||||||
|
self.init_poolmanager(
|
||||||
|
self._pool_connections, self._pool_maxsize, block=self._pool_block
|
||||||
|
)
|
||||||
|
|
||||||
|
def init_poolmanager(
|
||||||
|
self, connections, maxsize, block=DEFAULT_POOLBLOCK, **pool_kwargs
|
||||||
|
):
|
||||||
|
"""Initializes a urllib3 PoolManager.
|
||||||
|
|
||||||
|
This method should not be called from user code, and is only
|
||||||
|
exposed for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param connections: The number of urllib3 connection pools to cache.
|
||||||
|
:param maxsize: The maximum number of connections to save in the pool.
|
||||||
|
:param block: Block when no free connections are available.
|
||||||
|
:param pool_kwargs: Extra keyword arguments used to initialize the Pool Manager.
|
||||||
|
"""
|
||||||
|
# save these values for pickling
|
||||||
|
self._pool_connections = connections
|
||||||
|
self._pool_maxsize = maxsize
|
||||||
|
self._pool_block = block
|
||||||
|
|
||||||
|
self.poolmanager = PoolManager(
|
||||||
|
num_pools=connections,
|
||||||
|
maxsize=maxsize,
|
||||||
|
block=block,
|
||||||
|
**pool_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
def proxy_manager_for(self, proxy, **proxy_kwargs):
|
||||||
|
"""Return urllib3 ProxyManager for the given proxy.
|
||||||
|
|
||||||
|
This method should not be called from user code, and is only
|
||||||
|
exposed for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param proxy: The proxy to return a urllib3 ProxyManager for.
|
||||||
|
:param proxy_kwargs: Extra keyword arguments used to configure the Proxy Manager.
|
||||||
|
:returns: ProxyManager
|
||||||
|
:rtype: urllib3.ProxyManager
|
||||||
|
"""
|
||||||
|
if proxy in self.proxy_manager:
|
||||||
|
manager = self.proxy_manager[proxy]
|
||||||
|
elif proxy.lower().startswith("socks"):
|
||||||
|
username, password = get_auth_from_url(proxy)
|
||||||
|
manager = self.proxy_manager[proxy] = SOCKSProxyManager(
|
||||||
|
proxy,
|
||||||
|
username=username,
|
||||||
|
password=password,
|
||||||
|
num_pools=self._pool_connections,
|
||||||
|
maxsize=self._pool_maxsize,
|
||||||
|
block=self._pool_block,
|
||||||
|
**proxy_kwargs,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
proxy_headers = self.proxy_headers(proxy)
|
||||||
|
manager = self.proxy_manager[proxy] = proxy_from_url(
|
||||||
|
proxy,
|
||||||
|
proxy_headers=proxy_headers,
|
||||||
|
num_pools=self._pool_connections,
|
||||||
|
maxsize=self._pool_maxsize,
|
||||||
|
block=self._pool_block,
|
||||||
|
**proxy_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
return manager
|
||||||
|
|
||||||
|
def cert_verify(self, conn, url, verify, cert):
|
||||||
|
"""Verify a SSL certificate. This method should not be called from user
|
||||||
|
code, and is only exposed for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param conn: The urllib3 connection object associated with the cert.
|
||||||
|
:param url: The requested URL.
|
||||||
|
:param verify: Either a boolean, in which case it controls whether we verify
|
||||||
|
the server's TLS certificate, or a string, in which case it must be a path
|
||||||
|
to a CA bundle to use
|
||||||
|
:param cert: The SSL certificate to verify.
|
||||||
|
"""
|
||||||
|
if url.lower().startswith("https") and verify:
|
||||||
|
|
||||||
|
cert_loc = None
|
||||||
|
|
||||||
|
# Allow self-specified cert location.
|
||||||
|
if verify is not True:
|
||||||
|
cert_loc = verify
|
||||||
|
|
||||||
|
if not cert_loc:
|
||||||
|
cert_loc = extract_zipped_paths(DEFAULT_CA_BUNDLE_PATH)
|
||||||
|
|
||||||
|
if not cert_loc or not os.path.exists(cert_loc):
|
||||||
|
raise OSError(
|
||||||
|
f"Could not find a suitable TLS CA certificate bundle, "
|
||||||
|
f"invalid path: {cert_loc}"
|
||||||
|
)
|
||||||
|
|
||||||
|
conn.cert_reqs = "CERT_REQUIRED"
|
||||||
|
|
||||||
|
if not os.path.isdir(cert_loc):
|
||||||
|
conn.ca_certs = cert_loc
|
||||||
|
else:
|
||||||
|
conn.ca_cert_dir = cert_loc
|
||||||
|
else:
|
||||||
|
conn.cert_reqs = "CERT_NONE"
|
||||||
|
conn.ca_certs = None
|
||||||
|
conn.ca_cert_dir = None
|
||||||
|
|
||||||
|
if cert:
|
||||||
|
if not isinstance(cert, basestring):
|
||||||
|
conn.cert_file = cert[0]
|
||||||
|
conn.key_file = cert[1]
|
||||||
|
else:
|
||||||
|
conn.cert_file = cert
|
||||||
|
conn.key_file = None
|
||||||
|
if conn.cert_file and not os.path.exists(conn.cert_file):
|
||||||
|
raise OSError(
|
||||||
|
f"Could not find the TLS certificate file, "
|
||||||
|
f"invalid path: {conn.cert_file}"
|
||||||
|
)
|
||||||
|
if conn.key_file and not os.path.exists(conn.key_file):
|
||||||
|
raise OSError(
|
||||||
|
f"Could not find the TLS key file, invalid path: {conn.key_file}"
|
||||||
|
)
|
||||||
|
|
||||||
|
def build_response(self, req, resp):
|
||||||
|
"""Builds a :class:`Response <requests.Response>` object from a urllib3
|
||||||
|
response. This should not be called from user code, and is only exposed
|
||||||
|
for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`
|
||||||
|
|
||||||
|
:param req: The :class:`PreparedRequest <PreparedRequest>` used to generate the response.
|
||||||
|
:param resp: The urllib3 response object.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
response = Response()
|
||||||
|
|
||||||
|
# Fallback to None if there's no status_code, for whatever reason.
|
||||||
|
response.status_code = getattr(resp, "status", None)
|
||||||
|
|
||||||
|
# Make headers case-insensitive.
|
||||||
|
response.headers = CaseInsensitiveDict(getattr(resp, "headers", {}))
|
||||||
|
|
||||||
|
# Set encoding.
|
||||||
|
response.encoding = get_encoding_from_headers(response.headers)
|
||||||
|
response.raw = resp
|
||||||
|
response.reason = response.raw.reason
|
||||||
|
|
||||||
|
if isinstance(req.url, bytes):
|
||||||
|
response.url = req.url.decode("utf-8")
|
||||||
|
else:
|
||||||
|
response.url = req.url
|
||||||
|
|
||||||
|
# Add new cookies from the server.
|
||||||
|
extract_cookies_to_jar(response.cookies, req, resp)
|
||||||
|
|
||||||
|
# Give the Response some context.
|
||||||
|
response.request = req
|
||||||
|
response.connection = self
|
||||||
|
|
||||||
|
return response
|
||||||
|
|
||||||
|
def get_connection(self, url, proxies=None):
|
||||||
|
"""Returns a urllib3 connection for the given URL. This should not be
|
||||||
|
called from user code, and is only exposed for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param url: The URL to connect to.
|
||||||
|
:param proxies: (optional) A Requests-style dictionary of proxies used on this request.
|
||||||
|
:rtype: urllib3.ConnectionPool
|
||||||
|
"""
|
||||||
|
proxy = select_proxy(url, proxies)
|
||||||
|
|
||||||
|
if proxy:
|
||||||
|
proxy = prepend_scheme_if_needed(proxy, "http")
|
||||||
|
proxy_url = parse_url(proxy)
|
||||||
|
if not proxy_url.host:
|
||||||
|
raise InvalidProxyURL(
|
||||||
|
"Please check proxy URL. It is malformed "
|
||||||
|
"and could be missing the host."
|
||||||
|
)
|
||||||
|
proxy_manager = self.proxy_manager_for(proxy)
|
||||||
|
conn = proxy_manager.connection_from_url(url)
|
||||||
|
else:
|
||||||
|
# Only scheme should be lower case
|
||||||
|
parsed = urlparse(url)
|
||||||
|
url = parsed.geturl()
|
||||||
|
conn = self.poolmanager.connection_from_url(url)
|
||||||
|
|
||||||
|
return conn
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
"""Disposes of any internal state.
|
||||||
|
|
||||||
|
Currently, this closes the PoolManager and any active ProxyManager,
|
||||||
|
which closes any pooled connections.
|
||||||
|
"""
|
||||||
|
self.poolmanager.clear()
|
||||||
|
for proxy in self.proxy_manager.values():
|
||||||
|
proxy.clear()
|
||||||
|
|
||||||
|
def request_url(self, request, proxies):
|
||||||
|
"""Obtain the url to use when making the final request.
|
||||||
|
|
||||||
|
If the message is being sent through a HTTP proxy, the full URL has to
|
||||||
|
be used. Otherwise, we should only use the path portion of the URL.
|
||||||
|
|
||||||
|
This should not be called from user code, and is only exposed for use
|
||||||
|
when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
|
||||||
|
:param proxies: A dictionary of schemes or schemes and hosts to proxy URLs.
|
||||||
|
:rtype: str
|
||||||
|
"""
|
||||||
|
proxy = select_proxy(request.url, proxies)
|
||||||
|
scheme = urlparse(request.url).scheme
|
||||||
|
|
||||||
|
is_proxied_http_request = proxy and scheme != "https"
|
||||||
|
using_socks_proxy = False
|
||||||
|
if proxy:
|
||||||
|
proxy_scheme = urlparse(proxy).scheme.lower()
|
||||||
|
using_socks_proxy = proxy_scheme.startswith("socks")
|
||||||
|
|
||||||
|
url = request.path_url
|
||||||
|
if is_proxied_http_request and not using_socks_proxy:
|
||||||
|
url = urldefragauth(request.url)
|
||||||
|
|
||||||
|
return url
|
||||||
|
|
||||||
|
def add_headers(self, request, **kwargs):
|
||||||
|
"""Add any headers needed by the connection. As of v2.0 this does
|
||||||
|
nothing by default, but is left for overriding by users that subclass
|
||||||
|
the :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
This should not be called from user code, and is only exposed for use
|
||||||
|
when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param request: The :class:`PreparedRequest <PreparedRequest>` to add headers to.
|
||||||
|
:param kwargs: The keyword arguments from the call to send().
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def proxy_headers(self, proxy):
|
||||||
|
"""Returns a dictionary of the headers to add to any request sent
|
||||||
|
through a proxy. This works with urllib3 magic to ensure that they are
|
||||||
|
correctly sent to the proxy, rather than in a tunnelled request if
|
||||||
|
CONNECT is being used.
|
||||||
|
|
||||||
|
This should not be called from user code, and is only exposed for use
|
||||||
|
when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param proxy: The url of the proxy being used for this request.
|
||||||
|
:rtype: dict
|
||||||
|
"""
|
||||||
|
headers = {}
|
||||||
|
username, password = get_auth_from_url(proxy)
|
||||||
|
|
||||||
|
if username:
|
||||||
|
headers["Proxy-Authorization"] = _basic_auth_str(username, password)
|
||||||
|
|
||||||
|
return headers
|
||||||
|
|
||||||
|
def send(
|
||||||
|
self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None
|
||||||
|
):
|
||||||
|
"""Sends PreparedRequest object. Returns Response object.
|
||||||
|
|
||||||
|
:param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
|
||||||
|
:param stream: (optional) Whether to stream the request content.
|
||||||
|
:param timeout: (optional) How long to wait for the server to send
|
||||||
|
data before giving up, as a float, or a :ref:`(connect timeout,
|
||||||
|
read timeout) <timeouts>` tuple.
|
||||||
|
:type timeout: float or tuple or urllib3 Timeout object
|
||||||
|
:param verify: (optional) Either a boolean, in which case it controls whether
|
||||||
|
we verify the server's TLS certificate, or a string, in which case it
|
||||||
|
must be a path to a CA bundle to use
|
||||||
|
:param cert: (optional) Any user-provided SSL certificate to be trusted.
|
||||||
|
:param proxies: (optional) The proxies dictionary to apply to the request.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
try:
|
||||||
|
conn = self.get_connection(request.url, proxies)
|
||||||
|
except LocationValueError as e:
|
||||||
|
raise InvalidURL(e, request=request)
|
||||||
|
|
||||||
|
self.cert_verify(conn, request.url, verify, cert)
|
||||||
|
url = self.request_url(request, proxies)
|
||||||
|
self.add_headers(
|
||||||
|
request,
|
||||||
|
stream=stream,
|
||||||
|
timeout=timeout,
|
||||||
|
verify=verify,
|
||||||
|
cert=cert,
|
||||||
|
proxies=proxies,
|
||||||
|
)
|
||||||
|
|
||||||
|
chunked = not (request.body is None or "Content-Length" in request.headers)
|
||||||
|
|
||||||
|
if isinstance(timeout, tuple):
|
||||||
|
try:
|
||||||
|
connect, read = timeout
|
||||||
|
timeout = TimeoutSauce(connect=connect, read=read)
|
||||||
|
except ValueError:
|
||||||
|
raise ValueError(
|
||||||
|
f"Invalid timeout {timeout}. Pass a (connect, read) timeout tuple, "
|
||||||
|
f"or a single float to set both timeouts to the same value."
|
||||||
|
)
|
||||||
|
elif isinstance(timeout, TimeoutSauce):
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
timeout = TimeoutSauce(connect=timeout, read=timeout)
|
||||||
|
|
||||||
|
try:
|
||||||
|
resp = conn.urlopen(
|
||||||
|
method=request.method,
|
||||||
|
url=url,
|
||||||
|
body=request.body,
|
||||||
|
headers=request.headers,
|
||||||
|
redirect=False,
|
||||||
|
assert_same_host=False,
|
||||||
|
preload_content=False,
|
||||||
|
decode_content=False,
|
||||||
|
retries=self.max_retries,
|
||||||
|
timeout=timeout,
|
||||||
|
chunked=chunked,
|
||||||
|
)
|
||||||
|
|
||||||
|
except (ProtocolError, OSError) as err:
|
||||||
|
raise ConnectionError(err, request=request)
|
||||||
|
|
||||||
|
except MaxRetryError as e:
|
||||||
|
if isinstance(e.reason, ConnectTimeoutError):
|
||||||
|
# TODO: Remove this in 3.0.0: see #2811
|
||||||
|
if not isinstance(e.reason, NewConnectionError):
|
||||||
|
raise ConnectTimeout(e, request=request)
|
||||||
|
|
||||||
|
if isinstance(e.reason, ResponseError):
|
||||||
|
raise RetryError(e, request=request)
|
||||||
|
|
||||||
|
if isinstance(e.reason, _ProxyError):
|
||||||
|
raise ProxyError(e, request=request)
|
||||||
|
|
||||||
|
if isinstance(e.reason, _SSLError):
|
||||||
|
# This branch is for urllib3 v1.22 and later.
|
||||||
|
raise SSLError(e, request=request)
|
||||||
|
|
||||||
|
raise ConnectionError(e, request=request)
|
||||||
|
|
||||||
|
except ClosedPoolError as e:
|
||||||
|
raise ConnectionError(e, request=request)
|
||||||
|
|
||||||
|
except _ProxyError as e:
|
||||||
|
raise ProxyError(e)
|
||||||
|
|
||||||
|
except (_SSLError, _HTTPError) as e:
|
||||||
|
if isinstance(e, _SSLError):
|
||||||
|
# This branch is for urllib3 versions earlier than v1.22
|
||||||
|
raise SSLError(e, request=request)
|
||||||
|
elif isinstance(e, ReadTimeoutError):
|
||||||
|
raise ReadTimeout(e, request=request)
|
||||||
|
elif isinstance(e, _InvalidHeader):
|
||||||
|
raise InvalidHeader(e, request=request)
|
||||||
|
else:
|
||||||
|
raise
|
||||||
|
|
||||||
|
return self.build_response(request, resp)
|
||||||
|
|
@ -0,0 +1,157 @@
|
||||||
|
"""
|
||||||
|
requests.api
|
||||||
|
~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module implements the Requests API.
|
||||||
|
|
||||||
|
:copyright: (c) 2012 by Kenneth Reitz.
|
||||||
|
:license: Apache2, see LICENSE for more details.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from . import sessions
|
||||||
|
|
||||||
|
|
||||||
|
def request(method, url, **kwargs):
|
||||||
|
"""Constructs and sends a :class:`Request <Request>`.
|
||||||
|
|
||||||
|
:param method: method for the new :class:`Request` object: ``GET``, ``OPTIONS``, ``HEAD``, ``POST``, ``PUT``, ``PATCH``, or ``DELETE``.
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param params: (optional) Dictionary, list of tuples or bytes to send
|
||||||
|
in the query string for the :class:`Request`.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
|
||||||
|
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
|
||||||
|
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
|
||||||
|
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
|
||||||
|
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
|
||||||
|
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
|
||||||
|
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
|
||||||
|
to add for the file.
|
||||||
|
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
|
||||||
|
:param timeout: (optional) How many seconds to wait for the server to send data
|
||||||
|
before giving up, as a float, or a :ref:`(connect timeout, read
|
||||||
|
timeout) <timeouts>` tuple.
|
||||||
|
:type timeout: float or tuple
|
||||||
|
:param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
|
||||||
|
:type allow_redirects: bool
|
||||||
|
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
|
||||||
|
:param verify: (optional) Either a boolean, in which case it controls whether we verify
|
||||||
|
the server's TLS certificate, or a string, in which case it must be a path
|
||||||
|
to a CA bundle to use. Defaults to ``True``.
|
||||||
|
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
|
||||||
|
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
|
||||||
|
Usage::
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> req = requests.request('GET', 'https://httpbin.org/get')
|
||||||
|
>>> req
|
||||||
|
<Response [200]>
|
||||||
|
"""
|
||||||
|
|
||||||
|
# By using the 'with' statement we are sure the session is closed, thus we
|
||||||
|
# avoid leaving sockets open which can trigger a ResourceWarning in some
|
||||||
|
# cases, and look like a memory leak in others.
|
||||||
|
with sessions.Session() as session:
|
||||||
|
return session.request(method=method, url=url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def get(url, params=None, **kwargs):
|
||||||
|
r"""Sends a GET request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param params: (optional) Dictionary, list of tuples or bytes to send
|
||||||
|
in the query string for the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("get", url, params=params, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def options(url, **kwargs):
|
||||||
|
r"""Sends an OPTIONS request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("options", url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def head(url, **kwargs):
|
||||||
|
r"""Sends a HEAD request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes. If
|
||||||
|
`allow_redirects` is not provided, it will be set to `False` (as
|
||||||
|
opposed to the default :meth:`request` behavior).
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
kwargs.setdefault("allow_redirects", False)
|
||||||
|
return request("head", url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def post(url, data=None, json=None, **kwargs):
|
||||||
|
r"""Sends a POST request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("post", url, data=data, json=json, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def put(url, data=None, **kwargs):
|
||||||
|
r"""Sends a PUT request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("put", url, data=data, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def patch(url, data=None, **kwargs):
|
||||||
|
r"""Sends a PATCH request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("patch", url, data=data, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def delete(url, **kwargs):
|
||||||
|
r"""Sends a DELETE request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("delete", url, **kwargs)
|
||||||
|
|
@ -0,0 +1,315 @@
|
||||||
|
"""
|
||||||
|
requests.auth
|
||||||
|
~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module contains the authentication handlers for Requests.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import hashlib
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
import threading
|
||||||
|
import time
|
||||||
|
import warnings
|
||||||
|
from base64 import b64encode
|
||||||
|
|
||||||
|
from ._internal_utils import to_native_string
|
||||||
|
from .compat import basestring, str, urlparse
|
||||||
|
from .cookies import extract_cookies_to_jar
|
||||||
|
from .utils import parse_dict_header
|
||||||
|
|
||||||
|
CONTENT_TYPE_FORM_URLENCODED = "application/x-www-form-urlencoded"
|
||||||
|
CONTENT_TYPE_MULTI_PART = "multipart/form-data"
|
||||||
|
|
||||||
|
|
||||||
|
def _basic_auth_str(username, password):
|
||||||
|
"""Returns a Basic Auth string."""
|
||||||
|
|
||||||
|
# "I want us to put a big-ol' comment on top of it that
|
||||||
|
# says that this behaviour is dumb but we need to preserve
|
||||||
|
# it because people are relying on it."
|
||||||
|
# - Lukasa
|
||||||
|
#
|
||||||
|
# These are here solely to maintain backwards compatibility
|
||||||
|
# for things like ints. This will be removed in 3.0.0.
|
||||||
|
if not isinstance(username, basestring):
|
||||||
|
warnings.warn(
|
||||||
|
"Non-string usernames will no longer be supported in Requests "
|
||||||
|
"3.0.0. Please convert the object you've passed in ({!r}) to "
|
||||||
|
"a string or bytes object in the near future to avoid "
|
||||||
|
"problems.".format(username),
|
||||||
|
category=DeprecationWarning,
|
||||||
|
)
|
||||||
|
username = str(username)
|
||||||
|
|
||||||
|
if not isinstance(password, basestring):
|
||||||
|
warnings.warn(
|
||||||
|
"Non-string passwords will no longer be supported in Requests "
|
||||||
|
"3.0.0. Please convert the object you've passed in ({!r}) to "
|
||||||
|
"a string or bytes object in the near future to avoid "
|
||||||
|
"problems.".format(type(password)),
|
||||||
|
category=DeprecationWarning,
|
||||||
|
)
|
||||||
|
password = str(password)
|
||||||
|
# -- End Removal --
|
||||||
|
|
||||||
|
if isinstance(username, str):
|
||||||
|
username = username.encode("latin1")
|
||||||
|
|
||||||
|
if isinstance(password, str):
|
||||||
|
password = password.encode("latin1")
|
||||||
|
|
||||||
|
authstr = "Basic " + to_native_string(
|
||||||
|
b64encode(b":".join((username, password))).strip()
|
||||||
|
)
|
||||||
|
|
||||||
|
return authstr
|
||||||
|
|
||||||
|
|
||||||
|
class AuthBase:
|
||||||
|
"""Base class that all auth implementations derive from"""
|
||||||
|
|
||||||
|
def __call__(self, r):
|
||||||
|
raise NotImplementedError("Auth hooks must be callable.")
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPBasicAuth(AuthBase):
|
||||||
|
"""Attaches HTTP Basic Authentication to the given Request object."""
|
||||||
|
|
||||||
|
def __init__(self, username, password):
|
||||||
|
self.username = username
|
||||||
|
self.password = password
|
||||||
|
|
||||||
|
def __eq__(self, other):
|
||||||
|
return all(
|
||||||
|
[
|
||||||
|
self.username == getattr(other, "username", None),
|
||||||
|
self.password == getattr(other, "password", None),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
def __ne__(self, other):
|
||||||
|
return not self == other
|
||||||
|
|
||||||
|
def __call__(self, r):
|
||||||
|
r.headers["Authorization"] = _basic_auth_str(self.username, self.password)
|
||||||
|
return r
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPProxyAuth(HTTPBasicAuth):
|
||||||
|
"""Attaches HTTP Proxy Authentication to a given Request object."""
|
||||||
|
|
||||||
|
def __call__(self, r):
|
||||||
|
r.headers["Proxy-Authorization"] = _basic_auth_str(self.username, self.password)
|
||||||
|
return r
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPDigestAuth(AuthBase):
|
||||||
|
"""Attaches HTTP Digest Authentication to the given Request object."""
|
||||||
|
|
||||||
|
def __init__(self, username, password):
|
||||||
|
self.username = username
|
||||||
|
self.password = password
|
||||||
|
# Keep state in per-thread local storage
|
||||||
|
self._thread_local = threading.local()
|
||||||
|
|
||||||
|
def init_per_thread_state(self):
|
||||||
|
# Ensure state is initialized just once per-thread
|
||||||
|
if not hasattr(self._thread_local, "init"):
|
||||||
|
self._thread_local.init = True
|
||||||
|
self._thread_local.last_nonce = ""
|
||||||
|
self._thread_local.nonce_count = 0
|
||||||
|
self._thread_local.chal = {}
|
||||||
|
self._thread_local.pos = None
|
||||||
|
self._thread_local.num_401_calls = None
|
||||||
|
|
||||||
|
def build_digest_header(self, method, url):
|
||||||
|
"""
|
||||||
|
:rtype: str
|
||||||
|
"""
|
||||||
|
|
||||||
|
realm = self._thread_local.chal["realm"]
|
||||||
|
nonce = self._thread_local.chal["nonce"]
|
||||||
|
qop = self._thread_local.chal.get("qop")
|
||||||
|
algorithm = self._thread_local.chal.get("algorithm")
|
||||||
|
opaque = self._thread_local.chal.get("opaque")
|
||||||
|
hash_utf8 = None
|
||||||
|
|
||||||
|
if algorithm is None:
|
||||||
|
_algorithm = "MD5"
|
||||||
|
else:
|
||||||
|
_algorithm = algorithm.upper()
|
||||||
|
# lambdas assume digest modules are imported at the top level
|
||||||
|
if _algorithm == "MD5" or _algorithm == "MD5-SESS":
|
||||||
|
|
||||||
|
def md5_utf8(x):
|
||||||
|
if isinstance(x, str):
|
||||||
|
x = x.encode("utf-8")
|
||||||
|
return hashlib.md5(x).hexdigest()
|
||||||
|
|
||||||
|
hash_utf8 = md5_utf8
|
||||||
|
elif _algorithm == "SHA":
|
||||||
|
|
||||||
|
def sha_utf8(x):
|
||||||
|
if isinstance(x, str):
|
||||||
|
x = x.encode("utf-8")
|
||||||
|
return hashlib.sha1(x).hexdigest()
|
||||||
|
|
||||||
|
hash_utf8 = sha_utf8
|
||||||
|
elif _algorithm == "SHA-256":
|
||||||
|
|
||||||
|
def sha256_utf8(x):
|
||||||
|
if isinstance(x, str):
|
||||||
|
x = x.encode("utf-8")
|
||||||
|
return hashlib.sha256(x).hexdigest()
|
||||||
|
|
||||||
|
hash_utf8 = sha256_utf8
|
||||||
|
elif _algorithm == "SHA-512":
|
||||||
|
|
||||||
|
def sha512_utf8(x):
|
||||||
|
if isinstance(x, str):
|
||||||
|
x = x.encode("utf-8")
|
||||||
|
return hashlib.sha512(x).hexdigest()
|
||||||
|
|
||||||
|
hash_utf8 = sha512_utf8
|
||||||
|
|
||||||
|
KD = lambda s, d: hash_utf8(f"{s}:{d}") # noqa:E731
|
||||||
|
|
||||||
|
if hash_utf8 is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
# XXX not implemented yet
|
||||||
|
entdig = None
|
||||||
|
p_parsed = urlparse(url)
|
||||||
|
#: path is request-uri defined in RFC 2616 which should not be empty
|
||||||
|
path = p_parsed.path or "/"
|
||||||
|
if p_parsed.query:
|
||||||
|
path += f"?{p_parsed.query}"
|
||||||
|
|
||||||
|
A1 = f"{self.username}:{realm}:{self.password}"
|
||||||
|
A2 = f"{method}:{path}"
|
||||||
|
|
||||||
|
HA1 = hash_utf8(A1)
|
||||||
|
HA2 = hash_utf8(A2)
|
||||||
|
|
||||||
|
if nonce == self._thread_local.last_nonce:
|
||||||
|
self._thread_local.nonce_count += 1
|
||||||
|
else:
|
||||||
|
self._thread_local.nonce_count = 1
|
||||||
|
ncvalue = f"{self._thread_local.nonce_count:08x}"
|
||||||
|
s = str(self._thread_local.nonce_count).encode("utf-8")
|
||||||
|
s += nonce.encode("utf-8")
|
||||||
|
s += time.ctime().encode("utf-8")
|
||||||
|
s += os.urandom(8)
|
||||||
|
|
||||||
|
cnonce = hashlib.sha1(s).hexdigest()[:16]
|
||||||
|
if _algorithm == "MD5-SESS":
|
||||||
|
HA1 = hash_utf8(f"{HA1}:{nonce}:{cnonce}")
|
||||||
|
|
||||||
|
if not qop:
|
||||||
|
respdig = KD(HA1, f"{nonce}:{HA2}")
|
||||||
|
elif qop == "auth" or "auth" in qop.split(","):
|
||||||
|
noncebit = f"{nonce}:{ncvalue}:{cnonce}:auth:{HA2}"
|
||||||
|
respdig = KD(HA1, noncebit)
|
||||||
|
else:
|
||||||
|
# XXX handle auth-int.
|
||||||
|
return None
|
||||||
|
|
||||||
|
self._thread_local.last_nonce = nonce
|
||||||
|
|
||||||
|
# XXX should the partial digests be encoded too?
|
||||||
|
base = (
|
||||||
|
f'username="{self.username}", realm="{realm}", nonce="{nonce}", '
|
||||||
|
f'uri="{path}", response="{respdig}"'
|
||||||
|
)
|
||||||
|
if opaque:
|
||||||
|
base += f', opaque="{opaque}"'
|
||||||
|
if algorithm:
|
||||||
|
base += f', algorithm="{algorithm}"'
|
||||||
|
if entdig:
|
||||||
|
base += f', digest="{entdig}"'
|
||||||
|
if qop:
|
||||||
|
base += f', qop="auth", nc={ncvalue}, cnonce="{cnonce}"'
|
||||||
|
|
||||||
|
return f"Digest {base}"
|
||||||
|
|
||||||
|
def handle_redirect(self, r, **kwargs):
|
||||||
|
"""Reset num_401_calls counter on redirects."""
|
||||||
|
if r.is_redirect:
|
||||||
|
self._thread_local.num_401_calls = 1
|
||||||
|
|
||||||
|
def handle_401(self, r, **kwargs):
|
||||||
|
"""
|
||||||
|
Takes the given response and tries digest-auth, if needed.
|
||||||
|
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
# If response is not 4xx, do not auth
|
||||||
|
# See https://github.com/psf/requests/issues/3772
|
||||||
|
if not 400 <= r.status_code < 500:
|
||||||
|
self._thread_local.num_401_calls = 1
|
||||||
|
return r
|
||||||
|
|
||||||
|
if self._thread_local.pos is not None:
|
||||||
|
# Rewind the file position indicator of the body to where
|
||||||
|
# it was to resend the request.
|
||||||
|
r.request.body.seek(self._thread_local.pos)
|
||||||
|
s_auth = r.headers.get("www-authenticate", "")
|
||||||
|
|
||||||
|
if "digest" in s_auth.lower() and self._thread_local.num_401_calls < 2:
|
||||||
|
|
||||||
|
self._thread_local.num_401_calls += 1
|
||||||
|
pat = re.compile(r"digest ", flags=re.IGNORECASE)
|
||||||
|
self._thread_local.chal = parse_dict_header(pat.sub("", s_auth, count=1))
|
||||||
|
|
||||||
|
# Consume content and release the original connection
|
||||||
|
# to allow our new request to reuse the same one.
|
||||||
|
r.content
|
||||||
|
r.close()
|
||||||
|
prep = r.request.copy()
|
||||||
|
extract_cookies_to_jar(prep._cookies, r.request, r.raw)
|
||||||
|
prep.prepare_cookies(prep._cookies)
|
||||||
|
|
||||||
|
prep.headers["Authorization"] = self.build_digest_header(
|
||||||
|
prep.method, prep.url
|
||||||
|
)
|
||||||
|
_r = r.connection.send(prep, **kwargs)
|
||||||
|
_r.history.append(r)
|
||||||
|
_r.request = prep
|
||||||
|
|
||||||
|
return _r
|
||||||
|
|
||||||
|
self._thread_local.num_401_calls = 1
|
||||||
|
return r
|
||||||
|
|
||||||
|
def __call__(self, r):
|
||||||
|
# Initialize per-thread state, if needed
|
||||||
|
self.init_per_thread_state()
|
||||||
|
# If we have a saved nonce, skip the 401
|
||||||
|
if self._thread_local.last_nonce:
|
||||||
|
r.headers["Authorization"] = self.build_digest_header(r.method, r.url)
|
||||||
|
try:
|
||||||
|
self._thread_local.pos = r.body.tell()
|
||||||
|
except AttributeError:
|
||||||
|
# In the case of HTTPDigestAuth being reused and the body of
|
||||||
|
# the previous request was a file-like object, pos has the
|
||||||
|
# file position of the previous body. Ensure it's set to
|
||||||
|
# None.
|
||||||
|
self._thread_local.pos = None
|
||||||
|
r.register_hook("response", self.handle_401)
|
||||||
|
r.register_hook("response", self.handle_redirect)
|
||||||
|
self._thread_local.num_401_calls = 1
|
||||||
|
|
||||||
|
return r
|
||||||
|
|
||||||
|
def __eq__(self, other):
|
||||||
|
return all(
|
||||||
|
[
|
||||||
|
self.username == getattr(other, "username", None),
|
||||||
|
self.password == getattr(other, "password", None),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
def __ne__(self, other):
|
||||||
|
return not self == other
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
#!/usr/bin/env python
|
||||||
|
|
||||||
|
"""
|
||||||
|
requests.certs
|
||||||
|
~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module returns the preferred default CA certificate bundle. There is
|
||||||
|
only one — the one from the certifi package.
|
||||||
|
|
||||||
|
If you are packaging Requests, e.g., for a Linux distribution or a managed
|
||||||
|
environment, you can change the definition of where() to return a separately
|
||||||
|
packaged CA bundle.
|
||||||
|
"""
|
||||||
|
from certifi import where
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
print(where())
|
||||||
|
|
@ -0,0 +1,79 @@
|
||||||
|
"""
|
||||||
|
requests.compat
|
||||||
|
~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module previously handled import compatibility issues
|
||||||
|
between Python 2 and Python 3. It remains for backwards
|
||||||
|
compatibility until the next major version.
|
||||||
|
"""
|
||||||
|
|
||||||
|
try:
|
||||||
|
import chardet
|
||||||
|
except ImportError:
|
||||||
|
import charset_normalizer as chardet
|
||||||
|
|
||||||
|
import sys
|
||||||
|
|
||||||
|
# -------
|
||||||
|
# Pythons
|
||||||
|
# -------
|
||||||
|
|
||||||
|
# Syntax sugar.
|
||||||
|
_ver = sys.version_info
|
||||||
|
|
||||||
|
#: Python 2.x?
|
||||||
|
is_py2 = _ver[0] == 2
|
||||||
|
|
||||||
|
#: Python 3.x?
|
||||||
|
is_py3 = _ver[0] == 3
|
||||||
|
|
||||||
|
# json/simplejson module import resolution
|
||||||
|
has_simplejson = False
|
||||||
|
try:
|
||||||
|
import simplejson as json
|
||||||
|
|
||||||
|
has_simplejson = True
|
||||||
|
except ImportError:
|
||||||
|
import json
|
||||||
|
|
||||||
|
if has_simplejson:
|
||||||
|
from simplejson import JSONDecodeError
|
||||||
|
else:
|
||||||
|
from json import JSONDecodeError
|
||||||
|
|
||||||
|
# Keep OrderedDict for backwards compatibility.
|
||||||
|
from collections import OrderedDict
|
||||||
|
from collections.abc import Callable, Mapping, MutableMapping
|
||||||
|
from http import cookiejar as cookielib
|
||||||
|
from http.cookies import Morsel
|
||||||
|
from io import StringIO
|
||||||
|
|
||||||
|
# --------------
|
||||||
|
# Legacy Imports
|
||||||
|
# --------------
|
||||||
|
from urllib.parse import (
|
||||||
|
quote,
|
||||||
|
quote_plus,
|
||||||
|
unquote,
|
||||||
|
unquote_plus,
|
||||||
|
urldefrag,
|
||||||
|
urlencode,
|
||||||
|
urljoin,
|
||||||
|
urlparse,
|
||||||
|
urlsplit,
|
||||||
|
urlunparse,
|
||||||
|
)
|
||||||
|
from urllib.request import (
|
||||||
|
getproxies,
|
||||||
|
getproxies_environment,
|
||||||
|
parse_http_list,
|
||||||
|
proxy_bypass,
|
||||||
|
proxy_bypass_environment,
|
||||||
|
)
|
||||||
|
|
||||||
|
builtin_str = str
|
||||||
|
str = str
|
||||||
|
bytes = bytes
|
||||||
|
basestring = (str, bytes)
|
||||||
|
numeric_types = (int, float)
|
||||||
|
integer_types = (int,)
|
||||||
|
|
@ -0,0 +1,561 @@
|
||||||
|
"""
|
||||||
|
requests.cookies
|
||||||
|
~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
Compatibility code to be able to use `cookielib.CookieJar` with requests.
|
||||||
|
|
||||||
|
requests.utils imports from here, so be careful with imports.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import calendar
|
||||||
|
import copy
|
||||||
|
import time
|
||||||
|
|
||||||
|
from ._internal_utils import to_native_string
|
||||||
|
from .compat import Morsel, MutableMapping, cookielib, urlparse, urlunparse
|
||||||
|
|
||||||
|
try:
|
||||||
|
import threading
|
||||||
|
except ImportError:
|
||||||
|
import dummy_threading as threading
|
||||||
|
|
||||||
|
|
||||||
|
class MockRequest:
|
||||||
|
"""Wraps a `requests.Request` to mimic a `urllib2.Request`.
|
||||||
|
|
||||||
|
The code in `cookielib.CookieJar` expects this interface in order to correctly
|
||||||
|
manage cookie policies, i.e., determine whether a cookie can be set, given the
|
||||||
|
domains of the request and the cookie.
|
||||||
|
|
||||||
|
The original request object is read-only. The client is responsible for collecting
|
||||||
|
the new headers via `get_new_headers()` and interpreting them appropriately. You
|
||||||
|
probably want `get_cookie_header`, defined below.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, request):
|
||||||
|
self._r = request
|
||||||
|
self._new_headers = {}
|
||||||
|
self.type = urlparse(self._r.url).scheme
|
||||||
|
|
||||||
|
def get_type(self):
|
||||||
|
return self.type
|
||||||
|
|
||||||
|
def get_host(self):
|
||||||
|
return urlparse(self._r.url).netloc
|
||||||
|
|
||||||
|
def get_origin_req_host(self):
|
||||||
|
return self.get_host()
|
||||||
|
|
||||||
|
def get_full_url(self):
|
||||||
|
# Only return the response's URL if the user hadn't set the Host
|
||||||
|
# header
|
||||||
|
if not self._r.headers.get("Host"):
|
||||||
|
return self._r.url
|
||||||
|
# If they did set it, retrieve it and reconstruct the expected domain
|
||||||
|
host = to_native_string(self._r.headers["Host"], encoding="utf-8")
|
||||||
|
parsed = urlparse(self._r.url)
|
||||||
|
# Reconstruct the URL as we expect it
|
||||||
|
return urlunparse(
|
||||||
|
[
|
||||||
|
parsed.scheme,
|
||||||
|
host,
|
||||||
|
parsed.path,
|
||||||
|
parsed.params,
|
||||||
|
parsed.query,
|
||||||
|
parsed.fragment,
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
def is_unverifiable(self):
|
||||||
|
return True
|
||||||
|
|
||||||
|
def has_header(self, name):
|
||||||
|
return name in self._r.headers or name in self._new_headers
|
||||||
|
|
||||||
|
def get_header(self, name, default=None):
|
||||||
|
return self._r.headers.get(name, self._new_headers.get(name, default))
|
||||||
|
|
||||||
|
def add_header(self, key, val):
|
||||||
|
"""cookielib has no legitimate use for this method; add it back if you find one."""
|
||||||
|
raise NotImplementedError(
|
||||||
|
"Cookie headers should be added with add_unredirected_header()"
|
||||||
|
)
|
||||||
|
|
||||||
|
def add_unredirected_header(self, name, value):
|
||||||
|
self._new_headers[name] = value
|
||||||
|
|
||||||
|
def get_new_headers(self):
|
||||||
|
return self._new_headers
|
||||||
|
|
||||||
|
@property
|
||||||
|
def unverifiable(self):
|
||||||
|
return self.is_unverifiable()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def origin_req_host(self):
|
||||||
|
return self.get_origin_req_host()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def host(self):
|
||||||
|
return self.get_host()
|
||||||
|
|
||||||
|
|
||||||
|
class MockResponse:
|
||||||
|
"""Wraps a `httplib.HTTPMessage` to mimic a `urllib.addinfourl`.
|
||||||
|
|
||||||
|
...what? Basically, expose the parsed HTTP headers from the server response
|
||||||
|
the way `cookielib` expects to see them.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, headers):
|
||||||
|
"""Make a MockResponse for `cookielib` to read.
|
||||||
|
|
||||||
|
:param headers: a httplib.HTTPMessage or analogous carrying the headers
|
||||||
|
"""
|
||||||
|
self._headers = headers
|
||||||
|
|
||||||
|
def info(self):
|
||||||
|
return self._headers
|
||||||
|
|
||||||
|
def getheaders(self, name):
|
||||||
|
self._headers.getheaders(name)
|
||||||
|
|
||||||
|
|
||||||
|
def extract_cookies_to_jar(jar, request, response):
|
||||||
|
"""Extract the cookies from the response into a CookieJar.
|
||||||
|
|
||||||
|
:param jar: cookielib.CookieJar (not necessarily a RequestsCookieJar)
|
||||||
|
:param request: our own requests.Request object
|
||||||
|
:param response: urllib3.HTTPResponse object
|
||||||
|
"""
|
||||||
|
if not (hasattr(response, "_original_response") and response._original_response):
|
||||||
|
return
|
||||||
|
# the _original_response field is the wrapped httplib.HTTPResponse object,
|
||||||
|
req = MockRequest(request)
|
||||||
|
# pull out the HTTPMessage with the headers and put it in the mock:
|
||||||
|
res = MockResponse(response._original_response.msg)
|
||||||
|
jar.extract_cookies(res, req)
|
||||||
|
|
||||||
|
|
||||||
|
def get_cookie_header(jar, request):
|
||||||
|
"""
|
||||||
|
Produce an appropriate Cookie header string to be sent with `request`, or None.
|
||||||
|
|
||||||
|
:rtype: str
|
||||||
|
"""
|
||||||
|
r = MockRequest(request)
|
||||||
|
jar.add_cookie_header(r)
|
||||||
|
return r.get_new_headers().get("Cookie")
|
||||||
|
|
||||||
|
|
||||||
|
def remove_cookie_by_name(cookiejar, name, domain=None, path=None):
|
||||||
|
"""Unsets a cookie by name, by default over all domains and paths.
|
||||||
|
|
||||||
|
Wraps CookieJar.clear(), is O(n).
|
||||||
|
"""
|
||||||
|
clearables = []
|
||||||
|
for cookie in cookiejar:
|
||||||
|
if cookie.name != name:
|
||||||
|
continue
|
||||||
|
if domain is not None and domain != cookie.domain:
|
||||||
|
continue
|
||||||
|
if path is not None and path != cookie.path:
|
||||||
|
continue
|
||||||
|
clearables.append((cookie.domain, cookie.path, cookie.name))
|
||||||
|
|
||||||
|
for domain, path, name in clearables:
|
||||||
|
cookiejar.clear(domain, path, name)
|
||||||
|
|
||||||
|
|
||||||
|
class CookieConflictError(RuntimeError):
|
||||||
|
"""There are two cookies that meet the criteria specified in the cookie jar.
|
||||||
|
Use .get and .set and include domain and path args in order to be more specific.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class RequestsCookieJar(cookielib.CookieJar, MutableMapping):
|
||||||
|
"""Compatibility class; is a cookielib.CookieJar, but exposes a dict
|
||||||
|
interface.
|
||||||
|
|
||||||
|
This is the CookieJar we create by default for requests and sessions that
|
||||||
|
don't specify one, since some clients may expect response.cookies and
|
||||||
|
session.cookies to support dict operations.
|
||||||
|
|
||||||
|
Requests does not use the dict interface internally; it's just for
|
||||||
|
compatibility with external client code. All requests code should work
|
||||||
|
out of the box with externally provided instances of ``CookieJar``, e.g.
|
||||||
|
``LWPCookieJar`` and ``FileCookieJar``.
|
||||||
|
|
||||||
|
Unlike a regular CookieJar, this class is pickleable.
|
||||||
|
|
||||||
|
.. warning:: dictionary operations that are normally O(1) may be O(n).
|
||||||
|
"""
|
||||||
|
|
||||||
|
def get(self, name, default=None, domain=None, path=None):
|
||||||
|
"""Dict-like get() that also supports optional domain and path args in
|
||||||
|
order to resolve naming collisions from using one cookie jar over
|
||||||
|
multiple domains.
|
||||||
|
|
||||||
|
.. warning:: operation is O(n), not O(1).
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
return self._find_no_duplicates(name, domain, path)
|
||||||
|
except KeyError:
|
||||||
|
return default
|
||||||
|
|
||||||
|
def set(self, name, value, **kwargs):
|
||||||
|
"""Dict-like set() that also supports optional domain and path args in
|
||||||
|
order to resolve naming collisions from using one cookie jar over
|
||||||
|
multiple domains.
|
||||||
|
"""
|
||||||
|
# support client code that unsets cookies by assignment of a None value:
|
||||||
|
if value is None:
|
||||||
|
remove_cookie_by_name(
|
||||||
|
self, name, domain=kwargs.get("domain"), path=kwargs.get("path")
|
||||||
|
)
|
||||||
|
return
|
||||||
|
|
||||||
|
if isinstance(value, Morsel):
|
||||||
|
c = morsel_to_cookie(value)
|
||||||
|
else:
|
||||||
|
c = create_cookie(name, value, **kwargs)
|
||||||
|
self.set_cookie(c)
|
||||||
|
return c
|
||||||
|
|
||||||
|
def iterkeys(self):
|
||||||
|
"""Dict-like iterkeys() that returns an iterator of names of cookies
|
||||||
|
from the jar.
|
||||||
|
|
||||||
|
.. seealso:: itervalues() and iteritems().
|
||||||
|
"""
|
||||||
|
for cookie in iter(self):
|
||||||
|
yield cookie.name
|
||||||
|
|
||||||
|
def keys(self):
|
||||||
|
"""Dict-like keys() that returns a list of names of cookies from the
|
||||||
|
jar.
|
||||||
|
|
||||||
|
.. seealso:: values() and items().
|
||||||
|
"""
|
||||||
|
return list(self.iterkeys())
|
||||||
|
|
||||||
|
def itervalues(self):
|
||||||
|
"""Dict-like itervalues() that returns an iterator of values of cookies
|
||||||
|
from the jar.
|
||||||
|
|
||||||
|
.. seealso:: iterkeys() and iteritems().
|
||||||
|
"""
|
||||||
|
for cookie in iter(self):
|
||||||
|
yield cookie.value
|
||||||
|
|
||||||
|
def values(self):
|
||||||
|
"""Dict-like values() that returns a list of values of cookies from the
|
||||||
|
jar.
|
||||||
|
|
||||||
|
.. seealso:: keys() and items().
|
||||||
|
"""
|
||||||
|
return list(self.itervalues())
|
||||||
|
|
||||||
|
def iteritems(self):
|
||||||
|
"""Dict-like iteritems() that returns an iterator of name-value tuples
|
||||||
|
from the jar.
|
||||||
|
|
||||||
|
.. seealso:: iterkeys() and itervalues().
|
||||||
|
"""
|
||||||
|
for cookie in iter(self):
|
||||||
|
yield cookie.name, cookie.value
|
||||||
|
|
||||||
|
def items(self):
|
||||||
|
"""Dict-like items() that returns a list of name-value tuples from the
|
||||||
|
jar. Allows client-code to call ``dict(RequestsCookieJar)`` and get a
|
||||||
|
vanilla python dict of key value pairs.
|
||||||
|
|
||||||
|
.. seealso:: keys() and values().
|
||||||
|
"""
|
||||||
|
return list(self.iteritems())
|
||||||
|
|
||||||
|
def list_domains(self):
|
||||||
|
"""Utility method to list all the domains in the jar."""
|
||||||
|
domains = []
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.domain not in domains:
|
||||||
|
domains.append(cookie.domain)
|
||||||
|
return domains
|
||||||
|
|
||||||
|
def list_paths(self):
|
||||||
|
"""Utility method to list all the paths in the jar."""
|
||||||
|
paths = []
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.path not in paths:
|
||||||
|
paths.append(cookie.path)
|
||||||
|
return paths
|
||||||
|
|
||||||
|
def multiple_domains(self):
|
||||||
|
"""Returns True if there are multiple domains in the jar.
|
||||||
|
Returns False otherwise.
|
||||||
|
|
||||||
|
:rtype: bool
|
||||||
|
"""
|
||||||
|
domains = []
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.domain is not None and cookie.domain in domains:
|
||||||
|
return True
|
||||||
|
domains.append(cookie.domain)
|
||||||
|
return False # there is only one domain in jar
|
||||||
|
|
||||||
|
def get_dict(self, domain=None, path=None):
|
||||||
|
"""Takes as an argument an optional domain and path and returns a plain
|
||||||
|
old Python dict of name-value pairs of cookies that meet the
|
||||||
|
requirements.
|
||||||
|
|
||||||
|
:rtype: dict
|
||||||
|
"""
|
||||||
|
dictionary = {}
|
||||||
|
for cookie in iter(self):
|
||||||
|
if (domain is None or cookie.domain == domain) and (
|
||||||
|
path is None or cookie.path == path
|
||||||
|
):
|
||||||
|
dictionary[cookie.name] = cookie.value
|
||||||
|
return dictionary
|
||||||
|
|
||||||
|
def __contains__(self, name):
|
||||||
|
try:
|
||||||
|
return super().__contains__(name)
|
||||||
|
except CookieConflictError:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def __getitem__(self, name):
|
||||||
|
"""Dict-like __getitem__() for compatibility with client code. Throws
|
||||||
|
exception if there are more than one cookie with name. In that case,
|
||||||
|
use the more explicit get() method instead.
|
||||||
|
|
||||||
|
.. warning:: operation is O(n), not O(1).
|
||||||
|
"""
|
||||||
|
return self._find_no_duplicates(name)
|
||||||
|
|
||||||
|
def __setitem__(self, name, value):
|
||||||
|
"""Dict-like __setitem__ for compatibility with client code. Throws
|
||||||
|
exception if there is already a cookie of that name in the jar. In that
|
||||||
|
case, use the more explicit set() method instead.
|
||||||
|
"""
|
||||||
|
self.set(name, value)
|
||||||
|
|
||||||
|
def __delitem__(self, name):
|
||||||
|
"""Deletes a cookie given a name. Wraps ``cookielib.CookieJar``'s
|
||||||
|
``remove_cookie_by_name()``.
|
||||||
|
"""
|
||||||
|
remove_cookie_by_name(self, name)
|
||||||
|
|
||||||
|
def set_cookie(self, cookie, *args, **kwargs):
|
||||||
|
if (
|
||||||
|
hasattr(cookie.value, "startswith")
|
||||||
|
and cookie.value.startswith('"')
|
||||||
|
and cookie.value.endswith('"')
|
||||||
|
):
|
||||||
|
cookie.value = cookie.value.replace('\\"', "")
|
||||||
|
return super().set_cookie(cookie, *args, **kwargs)
|
||||||
|
|
||||||
|
def update(self, other):
|
||||||
|
"""Updates this jar with cookies from another CookieJar or dict-like"""
|
||||||
|
if isinstance(other, cookielib.CookieJar):
|
||||||
|
for cookie in other:
|
||||||
|
self.set_cookie(copy.copy(cookie))
|
||||||
|
else:
|
||||||
|
super().update(other)
|
||||||
|
|
||||||
|
def _find(self, name, domain=None, path=None):
|
||||||
|
"""Requests uses this method internally to get cookie values.
|
||||||
|
|
||||||
|
If there are conflicting cookies, _find arbitrarily chooses one.
|
||||||
|
See _find_no_duplicates if you want an exception thrown if there are
|
||||||
|
conflicting cookies.
|
||||||
|
|
||||||
|
:param name: a string containing name of cookie
|
||||||
|
:param domain: (optional) string containing domain of cookie
|
||||||
|
:param path: (optional) string containing path of cookie
|
||||||
|
:return: cookie.value
|
||||||
|
"""
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.name == name:
|
||||||
|
if domain is None or cookie.domain == domain:
|
||||||
|
if path is None or cookie.path == path:
|
||||||
|
return cookie.value
|
||||||
|
|
||||||
|
raise KeyError(f"name={name!r}, domain={domain!r}, path={path!r}")
|
||||||
|
|
||||||
|
def _find_no_duplicates(self, name, domain=None, path=None):
|
||||||
|
"""Both ``__get_item__`` and ``get`` call this function: it's never
|
||||||
|
used elsewhere in Requests.
|
||||||
|
|
||||||
|
:param name: a string containing name of cookie
|
||||||
|
:param domain: (optional) string containing domain of cookie
|
||||||
|
:param path: (optional) string containing path of cookie
|
||||||
|
:raises KeyError: if cookie is not found
|
||||||
|
:raises CookieConflictError: if there are multiple cookies
|
||||||
|
that match name and optionally domain and path
|
||||||
|
:return: cookie.value
|
||||||
|
"""
|
||||||
|
toReturn = None
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.name == name:
|
||||||
|
if domain is None or cookie.domain == domain:
|
||||||
|
if path is None or cookie.path == path:
|
||||||
|
if toReturn is not None:
|
||||||
|
# if there are multiple cookies that meet passed in criteria
|
||||||
|
raise CookieConflictError(
|
||||||
|
f"There are multiple cookies with name, {name!r}"
|
||||||
|
)
|
||||||
|
# we will eventually return this as long as no cookie conflict
|
||||||
|
toReturn = cookie.value
|
||||||
|
|
||||||
|
if toReturn:
|
||||||
|
return toReturn
|
||||||
|
raise KeyError(f"name={name!r}, domain={domain!r}, path={path!r}")
|
||||||
|
|
||||||
|
def __getstate__(self):
|
||||||
|
"""Unlike a normal CookieJar, this class is pickleable."""
|
||||||
|
state = self.__dict__.copy()
|
||||||
|
# remove the unpickleable RLock object
|
||||||
|
state.pop("_cookies_lock")
|
||||||
|
return state
|
||||||
|
|
||||||
|
def __setstate__(self, state):
|
||||||
|
"""Unlike a normal CookieJar, this class is pickleable."""
|
||||||
|
self.__dict__.update(state)
|
||||||
|
if "_cookies_lock" not in self.__dict__:
|
||||||
|
self._cookies_lock = threading.RLock()
|
||||||
|
|
||||||
|
def copy(self):
|
||||||
|
"""Return a copy of this RequestsCookieJar."""
|
||||||
|
new_cj = RequestsCookieJar()
|
||||||
|
new_cj.set_policy(self.get_policy())
|
||||||
|
new_cj.update(self)
|
||||||
|
return new_cj
|
||||||
|
|
||||||
|
def get_policy(self):
|
||||||
|
"""Return the CookiePolicy instance used."""
|
||||||
|
return self._policy
|
||||||
|
|
||||||
|
|
||||||
|
def _copy_cookie_jar(jar):
|
||||||
|
if jar is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
if hasattr(jar, "copy"):
|
||||||
|
# We're dealing with an instance of RequestsCookieJar
|
||||||
|
return jar.copy()
|
||||||
|
# We're dealing with a generic CookieJar instance
|
||||||
|
new_jar = copy.copy(jar)
|
||||||
|
new_jar.clear()
|
||||||
|
for cookie in jar:
|
||||||
|
new_jar.set_cookie(copy.copy(cookie))
|
||||||
|
return new_jar
|
||||||
|
|
||||||
|
|
||||||
|
def create_cookie(name, value, **kwargs):
|
||||||
|
"""Make a cookie from underspecified parameters.
|
||||||
|
|
||||||
|
By default, the pair of `name` and `value` will be set for the domain ''
|
||||||
|
and sent on every request (this is sometimes called a "supercookie").
|
||||||
|
"""
|
||||||
|
result = {
|
||||||
|
"version": 0,
|
||||||
|
"name": name,
|
||||||
|
"value": value,
|
||||||
|
"port": None,
|
||||||
|
"domain": "",
|
||||||
|
"path": "/",
|
||||||
|
"secure": False,
|
||||||
|
"expires": None,
|
||||||
|
"discard": True,
|
||||||
|
"comment": None,
|
||||||
|
"comment_url": None,
|
||||||
|
"rest": {"HttpOnly": None},
|
||||||
|
"rfc2109": False,
|
||||||
|
}
|
||||||
|
|
||||||
|
badargs = set(kwargs) - set(result)
|
||||||
|
if badargs:
|
||||||
|
raise TypeError(
|
||||||
|
f"create_cookie() got unexpected keyword arguments: {list(badargs)}"
|
||||||
|
)
|
||||||
|
|
||||||
|
result.update(kwargs)
|
||||||
|
result["port_specified"] = bool(result["port"])
|
||||||
|
result["domain_specified"] = bool(result["domain"])
|
||||||
|
result["domain_initial_dot"] = result["domain"].startswith(".")
|
||||||
|
result["path_specified"] = bool(result["path"])
|
||||||
|
|
||||||
|
return cookielib.Cookie(**result)
|
||||||
|
|
||||||
|
|
||||||
|
def morsel_to_cookie(morsel):
|
||||||
|
"""Convert a Morsel object into a Cookie containing the one k/v pair."""
|
||||||
|
|
||||||
|
expires = None
|
||||||
|
if morsel["max-age"]:
|
||||||
|
try:
|
||||||
|
expires = int(time.time() + int(morsel["max-age"]))
|
||||||
|
except ValueError:
|
||||||
|
raise TypeError(f"max-age: {morsel['max-age']} must be integer")
|
||||||
|
elif morsel["expires"]:
|
||||||
|
time_template = "%a, %d-%b-%Y %H:%M:%S GMT"
|
||||||
|
expires = calendar.timegm(time.strptime(morsel["expires"], time_template))
|
||||||
|
return create_cookie(
|
||||||
|
comment=morsel["comment"],
|
||||||
|
comment_url=bool(morsel["comment"]),
|
||||||
|
discard=False,
|
||||||
|
domain=morsel["domain"],
|
||||||
|
expires=expires,
|
||||||
|
name=morsel.key,
|
||||||
|
path=morsel["path"],
|
||||||
|
port=None,
|
||||||
|
rest={"HttpOnly": morsel["httponly"]},
|
||||||
|
rfc2109=False,
|
||||||
|
secure=bool(morsel["secure"]),
|
||||||
|
value=morsel.value,
|
||||||
|
version=morsel["version"] or 0,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def cookiejar_from_dict(cookie_dict, cookiejar=None, overwrite=True):
|
||||||
|
"""Returns a CookieJar from a key/value dictionary.
|
||||||
|
|
||||||
|
:param cookie_dict: Dict of key/values to insert into CookieJar.
|
||||||
|
:param cookiejar: (optional) A cookiejar to add the cookies to.
|
||||||
|
:param overwrite: (optional) If False, will not replace cookies
|
||||||
|
already in the jar with new ones.
|
||||||
|
:rtype: CookieJar
|
||||||
|
"""
|
||||||
|
if cookiejar is None:
|
||||||
|
cookiejar = RequestsCookieJar()
|
||||||
|
|
||||||
|
if cookie_dict is not None:
|
||||||
|
names_from_jar = [cookie.name for cookie in cookiejar]
|
||||||
|
for name in cookie_dict:
|
||||||
|
if overwrite or (name not in names_from_jar):
|
||||||
|
cookiejar.set_cookie(create_cookie(name, cookie_dict[name]))
|
||||||
|
|
||||||
|
return cookiejar
|
||||||
|
|
||||||
|
|
||||||
|
def merge_cookies(cookiejar, cookies):
|
||||||
|
"""Add cookies to cookiejar and returns a merged CookieJar.
|
||||||
|
|
||||||
|
:param cookiejar: CookieJar object to add the cookies to.
|
||||||
|
:param cookies: Dictionary or CookieJar object to be added.
|
||||||
|
:rtype: CookieJar
|
||||||
|
"""
|
||||||
|
if not isinstance(cookiejar, cookielib.CookieJar):
|
||||||
|
raise ValueError("You can only merge into CookieJar")
|
||||||
|
|
||||||
|
if isinstance(cookies, dict):
|
||||||
|
cookiejar = cookiejar_from_dict(cookies, cookiejar=cookiejar, overwrite=False)
|
||||||
|
elif isinstance(cookies, cookielib.CookieJar):
|
||||||
|
try:
|
||||||
|
cookiejar.update(cookies)
|
||||||
|
except AttributeError:
|
||||||
|
for cookie_in_jar in cookies:
|
||||||
|
cookiejar.set_cookie(cookie_in_jar)
|
||||||
|
|
||||||
|
return cookiejar
|
||||||
|
|
@ -0,0 +1,141 @@
|
||||||
|
"""
|
||||||
|
requests.exceptions
|
||||||
|
~~~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module contains the set of Requests' exceptions.
|
||||||
|
"""
|
||||||
|
from urllib3.exceptions import HTTPError as BaseHTTPError
|
||||||
|
|
||||||
|
from .compat import JSONDecodeError as CompatJSONDecodeError
|
||||||
|
|
||||||
|
|
||||||
|
class RequestException(IOError):
|
||||||
|
"""There was an ambiguous exception that occurred while handling your
|
||||||
|
request.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, *args, **kwargs):
|
||||||
|
"""Initialize RequestException with `request` and `response` objects."""
|
||||||
|
response = kwargs.pop("response", None)
|
||||||
|
self.response = response
|
||||||
|
self.request = kwargs.pop("request", None)
|
||||||
|
if response is not None and not self.request and hasattr(response, "request"):
|
||||||
|
self.request = self.response.request
|
||||||
|
super().__init__(*args, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidJSONError(RequestException):
|
||||||
|
"""A JSON error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class JSONDecodeError(InvalidJSONError, CompatJSONDecodeError):
|
||||||
|
"""Couldn't decode the text into json"""
|
||||||
|
|
||||||
|
def __init__(self, *args, **kwargs):
|
||||||
|
"""
|
||||||
|
Construct the JSONDecodeError instance first with all
|
||||||
|
args. Then use it's args to construct the IOError so that
|
||||||
|
the json specific args aren't used as IOError specific args
|
||||||
|
and the error message from JSONDecodeError is preserved.
|
||||||
|
"""
|
||||||
|
CompatJSONDecodeError.__init__(self, *args)
|
||||||
|
InvalidJSONError.__init__(self, *self.args, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPError(RequestException):
|
||||||
|
"""An HTTP error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class ConnectionError(RequestException):
|
||||||
|
"""A Connection error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class ProxyError(ConnectionError):
|
||||||
|
"""A proxy error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class SSLError(ConnectionError):
|
||||||
|
"""An SSL error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class Timeout(RequestException):
|
||||||
|
"""The request timed out.
|
||||||
|
|
||||||
|
Catching this error will catch both
|
||||||
|
:exc:`~requests.exceptions.ConnectTimeout` and
|
||||||
|
:exc:`~requests.exceptions.ReadTimeout` errors.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class ConnectTimeout(ConnectionError, Timeout):
|
||||||
|
"""The request timed out while trying to connect to the remote server.
|
||||||
|
|
||||||
|
Requests that produced this error are safe to retry.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class ReadTimeout(Timeout):
|
||||||
|
"""The server did not send any data in the allotted amount of time."""
|
||||||
|
|
||||||
|
|
||||||
|
class URLRequired(RequestException):
|
||||||
|
"""A valid URL is required to make a request."""
|
||||||
|
|
||||||
|
|
||||||
|
class TooManyRedirects(RequestException):
|
||||||
|
"""Too many redirects."""
|
||||||
|
|
||||||
|
|
||||||
|
class MissingSchema(RequestException, ValueError):
|
||||||
|
"""The URL scheme (e.g. http or https) is missing."""
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidSchema(RequestException, ValueError):
|
||||||
|
"""The URL scheme provided is either invalid or unsupported."""
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidURL(RequestException, ValueError):
|
||||||
|
"""The URL provided was somehow invalid."""
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidHeader(RequestException, ValueError):
|
||||||
|
"""The header value provided was somehow invalid."""
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidProxyURL(InvalidURL):
|
||||||
|
"""The proxy URL provided is invalid."""
|
||||||
|
|
||||||
|
|
||||||
|
class ChunkedEncodingError(RequestException):
|
||||||
|
"""The server declared chunked encoding but sent an invalid chunk."""
|
||||||
|
|
||||||
|
|
||||||
|
class ContentDecodingError(RequestException, BaseHTTPError):
|
||||||
|
"""Failed to decode response content."""
|
||||||
|
|
||||||
|
|
||||||
|
class StreamConsumedError(RequestException, TypeError):
|
||||||
|
"""The content for this response was already consumed."""
|
||||||
|
|
||||||
|
|
||||||
|
class RetryError(RequestException):
|
||||||
|
"""Custom retries logic failed"""
|
||||||
|
|
||||||
|
|
||||||
|
class UnrewindableBodyError(RequestException):
|
||||||
|
"""Requests encountered an error when trying to rewind a body."""
|
||||||
|
|
||||||
|
|
||||||
|
# Warnings
|
||||||
|
|
||||||
|
|
||||||
|
class RequestsWarning(Warning):
|
||||||
|
"""Base warning for Requests."""
|
||||||
|
|
||||||
|
|
||||||
|
class FileModeWarning(RequestsWarning, DeprecationWarning):
|
||||||
|
"""A file was opened in text mode, but Requests determined its binary length."""
|
||||||
|
|
||||||
|
|
||||||
|
class RequestsDependencyWarning(RequestsWarning):
|
||||||
|
"""An imported dependency doesn't match the expected version range."""
|
||||||
|
|
@ -0,0 +1,134 @@
|
||||||
|
"""Module containing bug report helper(s)."""
|
||||||
|
|
||||||
|
import json
|
||||||
|
import platform
|
||||||
|
import ssl
|
||||||
|
import sys
|
||||||
|
|
||||||
|
import idna
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
from . import __version__ as requests_version
|
||||||
|
|
||||||
|
try:
|
||||||
|
import charset_normalizer
|
||||||
|
except ImportError:
|
||||||
|
charset_normalizer = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
import chardet
|
||||||
|
except ImportError:
|
||||||
|
chardet = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
from urllib3.contrib import pyopenssl
|
||||||
|
except ImportError:
|
||||||
|
pyopenssl = None
|
||||||
|
OpenSSL = None
|
||||||
|
cryptography = None
|
||||||
|
else:
|
||||||
|
import cryptography
|
||||||
|
import OpenSSL
|
||||||
|
|
||||||
|
|
||||||
|
def _implementation():
|
||||||
|
"""Return a dict with the Python implementation and version.
|
||||||
|
|
||||||
|
Provide both the name and the version of the Python implementation
|
||||||
|
currently running. For example, on CPython 3.10.3 it will return
|
||||||
|
{'name': 'CPython', 'version': '3.10.3'}.
|
||||||
|
|
||||||
|
This function works best on CPython and PyPy: in particular, it probably
|
||||||
|
doesn't work for Jython or IronPython. Future investigation should be done
|
||||||
|
to work out the correct shape of the code for those platforms.
|
||||||
|
"""
|
||||||
|
implementation = platform.python_implementation()
|
||||||
|
|
||||||
|
if implementation == "CPython":
|
||||||
|
implementation_version = platform.python_version()
|
||||||
|
elif implementation == "PyPy":
|
||||||
|
implementation_version = "{}.{}.{}".format(
|
||||||
|
sys.pypy_version_info.major,
|
||||||
|
sys.pypy_version_info.minor,
|
||||||
|
sys.pypy_version_info.micro,
|
||||||
|
)
|
||||||
|
if sys.pypy_version_info.releaselevel != "final":
|
||||||
|
implementation_version = "".join(
|
||||||
|
[implementation_version, sys.pypy_version_info.releaselevel]
|
||||||
|
)
|
||||||
|
elif implementation == "Jython":
|
||||||
|
implementation_version = platform.python_version() # Complete Guess
|
||||||
|
elif implementation == "IronPython":
|
||||||
|
implementation_version = platform.python_version() # Complete Guess
|
||||||
|
else:
|
||||||
|
implementation_version = "Unknown"
|
||||||
|
|
||||||
|
return {"name": implementation, "version": implementation_version}
|
||||||
|
|
||||||
|
|
||||||
|
def info():
|
||||||
|
"""Generate information for a bug report."""
|
||||||
|
try:
|
||||||
|
platform_info = {
|
||||||
|
"system": platform.system(),
|
||||||
|
"release": platform.release(),
|
||||||
|
}
|
||||||
|
except OSError:
|
||||||
|
platform_info = {
|
||||||
|
"system": "Unknown",
|
||||||
|
"release": "Unknown",
|
||||||
|
}
|
||||||
|
|
||||||
|
implementation_info = _implementation()
|
||||||
|
urllib3_info = {"version": urllib3.__version__}
|
||||||
|
charset_normalizer_info = {"version": None}
|
||||||
|
chardet_info = {"version": None}
|
||||||
|
if charset_normalizer:
|
||||||
|
charset_normalizer_info = {"version": charset_normalizer.__version__}
|
||||||
|
if chardet:
|
||||||
|
chardet_info = {"version": chardet.__version__}
|
||||||
|
|
||||||
|
pyopenssl_info = {
|
||||||
|
"version": None,
|
||||||
|
"openssl_version": "",
|
||||||
|
}
|
||||||
|
if OpenSSL:
|
||||||
|
pyopenssl_info = {
|
||||||
|
"version": OpenSSL.__version__,
|
||||||
|
"openssl_version": f"{OpenSSL.SSL.OPENSSL_VERSION_NUMBER:x}",
|
||||||
|
}
|
||||||
|
cryptography_info = {
|
||||||
|
"version": getattr(cryptography, "__version__", ""),
|
||||||
|
}
|
||||||
|
idna_info = {
|
||||||
|
"version": getattr(idna, "__version__", ""),
|
||||||
|
}
|
||||||
|
|
||||||
|
system_ssl = ssl.OPENSSL_VERSION_NUMBER
|
||||||
|
system_ssl_info = {"version": f"{system_ssl:x}" if system_ssl is not None else ""}
|
||||||
|
|
||||||
|
return {
|
||||||
|
"platform": platform_info,
|
||||||
|
"implementation": implementation_info,
|
||||||
|
"system_ssl": system_ssl_info,
|
||||||
|
"using_pyopenssl": pyopenssl is not None,
|
||||||
|
"using_charset_normalizer": chardet is None,
|
||||||
|
"pyOpenSSL": pyopenssl_info,
|
||||||
|
"urllib3": urllib3_info,
|
||||||
|
"chardet": chardet_info,
|
||||||
|
"charset_normalizer": charset_normalizer_info,
|
||||||
|
"cryptography": cryptography_info,
|
||||||
|
"idna": idna_info,
|
||||||
|
"requests": {
|
||||||
|
"version": requests_version,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
"""Pretty-print the bug information as JSON."""
|
||||||
|
print(json.dumps(info(), sort_keys=True, indent=2))
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,33 @@
|
||||||
|
"""
|
||||||
|
requests.hooks
|
||||||
|
~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module provides the capabilities for the Requests hooks system.
|
||||||
|
|
||||||
|
Available hooks:
|
||||||
|
|
||||||
|
``response``:
|
||||||
|
The response generated from a Request.
|
||||||
|
"""
|
||||||
|
HOOKS = ["response"]
|
||||||
|
|
||||||
|
|
||||||
|
def default_hooks():
|
||||||
|
return {event: [] for event in HOOKS}
|
||||||
|
|
||||||
|
|
||||||
|
# TODO: response is the only one
|
||||||
|
|
||||||
|
|
||||||
|
def dispatch_hook(key, hooks, hook_data, **kwargs):
|
||||||
|
"""Dispatches a hook dictionary on a given piece of data."""
|
||||||
|
hooks = hooks or {}
|
||||||
|
hooks = hooks.get(key)
|
||||||
|
if hooks:
|
||||||
|
if hasattr(hooks, "__call__"):
|
||||||
|
hooks = [hooks]
|
||||||
|
for hook in hooks:
|
||||||
|
_hook_data = hook(hook_data, **kwargs)
|
||||||
|
if _hook_data is not None:
|
||||||
|
hook_data = _hook_data
|
||||||
|
return hook_data
|
||||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,28 @@
|
||||||
|
import sys
|
||||||
|
|
||||||
|
try:
|
||||||
|
import chardet
|
||||||
|
except ImportError:
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import charset_normalizer as chardet
|
||||||
|
|
||||||
|
warnings.filterwarnings("ignore", "Trying to detect", module="charset_normalizer")
|
||||||
|
|
||||||
|
# This code exists for backwards compatibility reasons.
|
||||||
|
# I don't like it either. Just look the other way. :)
|
||||||
|
|
||||||
|
for package in ("urllib3", "idna"):
|
||||||
|
locals()[package] = __import__(package)
|
||||||
|
# This traversal is apparently necessary such that the identities are
|
||||||
|
# preserved (requests.packages.urllib3.* is urllib3.*)
|
||||||
|
for mod in list(sys.modules):
|
||||||
|
if mod == package or mod.startswith(f"{package}."):
|
||||||
|
sys.modules[f"requests.packages.{mod}"] = sys.modules[mod]
|
||||||
|
|
||||||
|
target = chardet.__name__
|
||||||
|
for mod in list(sys.modules):
|
||||||
|
if mod == target or mod.startswith(f"{target}."):
|
||||||
|
target = target.replace(target, "chardet")
|
||||||
|
sys.modules[f"requests.packages.{target}"] = sys.modules[mod]
|
||||||
|
# Kinda cool, though, right?
|
||||||
|
|
@ -0,0 +1,833 @@
|
||||||
|
"""
|
||||||
|
requests.sessions
|
||||||
|
~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module provides a Session object to manage and persist settings across
|
||||||
|
requests (cookies, auth, proxies).
|
||||||
|
"""
|
||||||
|
import os
|
||||||
|
import sys
|
||||||
|
import time
|
||||||
|
from collections import OrderedDict
|
||||||
|
from datetime import timedelta
|
||||||
|
|
||||||
|
from ._internal_utils import to_native_string
|
||||||
|
from .adapters import HTTPAdapter
|
||||||
|
from .auth import _basic_auth_str
|
||||||
|
from .compat import Mapping, cookielib, urljoin, urlparse
|
||||||
|
from .cookies import (
|
||||||
|
RequestsCookieJar,
|
||||||
|
cookiejar_from_dict,
|
||||||
|
extract_cookies_to_jar,
|
||||||
|
merge_cookies,
|
||||||
|
)
|
||||||
|
from .exceptions import (
|
||||||
|
ChunkedEncodingError,
|
||||||
|
ContentDecodingError,
|
||||||
|
InvalidSchema,
|
||||||
|
TooManyRedirects,
|
||||||
|
)
|
||||||
|
from .hooks import default_hooks, dispatch_hook
|
||||||
|
|
||||||
|
# formerly defined here, reexposed here for backward compatibility
|
||||||
|
from .models import ( # noqa: F401
|
||||||
|
DEFAULT_REDIRECT_LIMIT,
|
||||||
|
REDIRECT_STATI,
|
||||||
|
PreparedRequest,
|
||||||
|
Request,
|
||||||
|
)
|
||||||
|
from .status_codes import codes
|
||||||
|
from .structures import CaseInsensitiveDict
|
||||||
|
from .utils import ( # noqa: F401
|
||||||
|
DEFAULT_PORTS,
|
||||||
|
default_headers,
|
||||||
|
get_auth_from_url,
|
||||||
|
get_environ_proxies,
|
||||||
|
get_netrc_auth,
|
||||||
|
requote_uri,
|
||||||
|
resolve_proxies,
|
||||||
|
rewind_body,
|
||||||
|
should_bypass_proxies,
|
||||||
|
to_key_val_list,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Preferred clock, based on which one is more accurate on a given system.
|
||||||
|
if sys.platform == "win32":
|
||||||
|
preferred_clock = time.perf_counter
|
||||||
|
else:
|
||||||
|
preferred_clock = time.time
|
||||||
|
|
||||||
|
|
||||||
|
def merge_setting(request_setting, session_setting, dict_class=OrderedDict):
|
||||||
|
"""Determines appropriate setting for a given request, taking into account
|
||||||
|
the explicit setting on that request, and the setting in the session. If a
|
||||||
|
setting is a dictionary, they will be merged together using `dict_class`
|
||||||
|
"""
|
||||||
|
|
||||||
|
if session_setting is None:
|
||||||
|
return request_setting
|
||||||
|
|
||||||
|
if request_setting is None:
|
||||||
|
return session_setting
|
||||||
|
|
||||||
|
# Bypass if not a dictionary (e.g. verify)
|
||||||
|
if not (
|
||||||
|
isinstance(session_setting, Mapping) and isinstance(request_setting, Mapping)
|
||||||
|
):
|
||||||
|
return request_setting
|
||||||
|
|
||||||
|
merged_setting = dict_class(to_key_val_list(session_setting))
|
||||||
|
merged_setting.update(to_key_val_list(request_setting))
|
||||||
|
|
||||||
|
# Remove keys that are set to None. Extract keys first to avoid altering
|
||||||
|
# the dictionary during iteration.
|
||||||
|
none_keys = [k for (k, v) in merged_setting.items() if v is None]
|
||||||
|
for key in none_keys:
|
||||||
|
del merged_setting[key]
|
||||||
|
|
||||||
|
return merged_setting
|
||||||
|
|
||||||
|
|
||||||
|
def merge_hooks(request_hooks, session_hooks, dict_class=OrderedDict):
|
||||||
|
"""Properly merges both requests and session hooks.
|
||||||
|
|
||||||
|
This is necessary because when request_hooks == {'response': []}, the
|
||||||
|
merge breaks Session hooks entirely.
|
||||||
|
"""
|
||||||
|
if session_hooks is None or session_hooks.get("response") == []:
|
||||||
|
return request_hooks
|
||||||
|
|
||||||
|
if request_hooks is None or request_hooks.get("response") == []:
|
||||||
|
return session_hooks
|
||||||
|
|
||||||
|
return merge_setting(request_hooks, session_hooks, dict_class)
|
||||||
|
|
||||||
|
|
||||||
|
class SessionRedirectMixin:
|
||||||
|
def get_redirect_target(self, resp):
|
||||||
|
"""Receives a Response. Returns a redirect URI or ``None``"""
|
||||||
|
# Due to the nature of how requests processes redirects this method will
|
||||||
|
# be called at least once upon the original response and at least twice
|
||||||
|
# on each subsequent redirect response (if any).
|
||||||
|
# If a custom mixin is used to handle this logic, it may be advantageous
|
||||||
|
# to cache the redirect location onto the response object as a private
|
||||||
|
# attribute.
|
||||||
|
if resp.is_redirect:
|
||||||
|
location = resp.headers["location"]
|
||||||
|
# Currently the underlying http module on py3 decode headers
|
||||||
|
# in latin1, but empirical evidence suggests that latin1 is very
|
||||||
|
# rarely used with non-ASCII characters in HTTP headers.
|
||||||
|
# It is more likely to get UTF8 header rather than latin1.
|
||||||
|
# This causes incorrect handling of UTF8 encoded location headers.
|
||||||
|
# To solve this, we re-encode the location in latin1.
|
||||||
|
location = location.encode("latin1")
|
||||||
|
return to_native_string(location, "utf8")
|
||||||
|
return None
|
||||||
|
|
||||||
|
def should_strip_auth(self, old_url, new_url):
|
||||||
|
"""Decide whether Authorization header should be removed when redirecting"""
|
||||||
|
old_parsed = urlparse(old_url)
|
||||||
|
new_parsed = urlparse(new_url)
|
||||||
|
if old_parsed.hostname != new_parsed.hostname:
|
||||||
|
return True
|
||||||
|
# Special case: allow http -> https redirect when using the standard
|
||||||
|
# ports. This isn't specified by RFC 7235, but is kept to avoid
|
||||||
|
# breaking backwards compatibility with older versions of requests
|
||||||
|
# that allowed any redirects on the same host.
|
||||||
|
if (
|
||||||
|
old_parsed.scheme == "http"
|
||||||
|
and old_parsed.port in (80, None)
|
||||||
|
and new_parsed.scheme == "https"
|
||||||
|
and new_parsed.port in (443, None)
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Handle default port usage corresponding to scheme.
|
||||||
|
changed_port = old_parsed.port != new_parsed.port
|
||||||
|
changed_scheme = old_parsed.scheme != new_parsed.scheme
|
||||||
|
default_port = (DEFAULT_PORTS.get(old_parsed.scheme, None), None)
|
||||||
|
if (
|
||||||
|
not changed_scheme
|
||||||
|
and old_parsed.port in default_port
|
||||||
|
and new_parsed.port in default_port
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Standard case: root URI must match
|
||||||
|
return changed_port or changed_scheme
|
||||||
|
|
||||||
|
def resolve_redirects(
|
||||||
|
self,
|
||||||
|
resp,
|
||||||
|
req,
|
||||||
|
stream=False,
|
||||||
|
timeout=None,
|
||||||
|
verify=True,
|
||||||
|
cert=None,
|
||||||
|
proxies=None,
|
||||||
|
yield_requests=False,
|
||||||
|
**adapter_kwargs,
|
||||||
|
):
|
||||||
|
"""Receives a Response. Returns a generator of Responses or Requests."""
|
||||||
|
|
||||||
|
hist = [] # keep track of history
|
||||||
|
|
||||||
|
url = self.get_redirect_target(resp)
|
||||||
|
previous_fragment = urlparse(req.url).fragment
|
||||||
|
while url:
|
||||||
|
prepared_request = req.copy()
|
||||||
|
|
||||||
|
# Update history and keep track of redirects.
|
||||||
|
# resp.history must ignore the original request in this loop
|
||||||
|
hist.append(resp)
|
||||||
|
resp.history = hist[1:]
|
||||||
|
|
||||||
|
try:
|
||||||
|
resp.content # Consume socket so it can be released
|
||||||
|
except (ChunkedEncodingError, ContentDecodingError, RuntimeError):
|
||||||
|
resp.raw.read(decode_content=False)
|
||||||
|
|
||||||
|
if len(resp.history) >= self.max_redirects:
|
||||||
|
raise TooManyRedirects(
|
||||||
|
f"Exceeded {self.max_redirects} redirects.", response=resp
|
||||||
|
)
|
||||||
|
|
||||||
|
# Release the connection back into the pool.
|
||||||
|
resp.close()
|
||||||
|
|
||||||
|
# Handle redirection without scheme (see: RFC 1808 Section 4)
|
||||||
|
if url.startswith("//"):
|
||||||
|
parsed_rurl = urlparse(resp.url)
|
||||||
|
url = ":".join([to_native_string(parsed_rurl.scheme), url])
|
||||||
|
|
||||||
|
# Normalize url case and attach previous fragment if needed (RFC 7231 7.1.2)
|
||||||
|
parsed = urlparse(url)
|
||||||
|
if parsed.fragment == "" and previous_fragment:
|
||||||
|
parsed = parsed._replace(fragment=previous_fragment)
|
||||||
|
elif parsed.fragment:
|
||||||
|
previous_fragment = parsed.fragment
|
||||||
|
url = parsed.geturl()
|
||||||
|
|
||||||
|
# Facilitate relative 'location' headers, as allowed by RFC 7231.
|
||||||
|
# (e.g. '/path/to/resource' instead of 'http://domain.tld/path/to/resource')
|
||||||
|
# Compliant with RFC3986, we percent encode the url.
|
||||||
|
if not parsed.netloc:
|
||||||
|
url = urljoin(resp.url, requote_uri(url))
|
||||||
|
else:
|
||||||
|
url = requote_uri(url)
|
||||||
|
|
||||||
|
prepared_request.url = to_native_string(url)
|
||||||
|
|
||||||
|
self.rebuild_method(prepared_request, resp)
|
||||||
|
|
||||||
|
# https://github.com/psf/requests/issues/1084
|
||||||
|
if resp.status_code not in (
|
||||||
|
codes.temporary_redirect,
|
||||||
|
codes.permanent_redirect,
|
||||||
|
):
|
||||||
|
# https://github.com/psf/requests/issues/3490
|
||||||
|
purged_headers = ("Content-Length", "Content-Type", "Transfer-Encoding")
|
||||||
|
for header in purged_headers:
|
||||||
|
prepared_request.headers.pop(header, None)
|
||||||
|
prepared_request.body = None
|
||||||
|
|
||||||
|
headers = prepared_request.headers
|
||||||
|
headers.pop("Cookie", None)
|
||||||
|
|
||||||
|
# Extract any cookies sent on the response to the cookiejar
|
||||||
|
# in the new request. Because we've mutated our copied prepared
|
||||||
|
# request, use the old one that we haven't yet touched.
|
||||||
|
extract_cookies_to_jar(prepared_request._cookies, req, resp.raw)
|
||||||
|
merge_cookies(prepared_request._cookies, self.cookies)
|
||||||
|
prepared_request.prepare_cookies(prepared_request._cookies)
|
||||||
|
|
||||||
|
# Rebuild auth and proxy information.
|
||||||
|
proxies = self.rebuild_proxies(prepared_request, proxies)
|
||||||
|
self.rebuild_auth(prepared_request, resp)
|
||||||
|
|
||||||
|
# A failed tell() sets `_body_position` to `object()`. This non-None
|
||||||
|
# value ensures `rewindable` will be True, allowing us to raise an
|
||||||
|
# UnrewindableBodyError, instead of hanging the connection.
|
||||||
|
rewindable = prepared_request._body_position is not None and (
|
||||||
|
"Content-Length" in headers or "Transfer-Encoding" in headers
|
||||||
|
)
|
||||||
|
|
||||||
|
# Attempt to rewind consumed file-like object.
|
||||||
|
if rewindable:
|
||||||
|
rewind_body(prepared_request)
|
||||||
|
|
||||||
|
# Override the original request.
|
||||||
|
req = prepared_request
|
||||||
|
|
||||||
|
if yield_requests:
|
||||||
|
yield req
|
||||||
|
else:
|
||||||
|
|
||||||
|
resp = self.send(
|
||||||
|
req,
|
||||||
|
stream=stream,
|
||||||
|
timeout=timeout,
|
||||||
|
verify=verify,
|
||||||
|
cert=cert,
|
||||||
|
proxies=proxies,
|
||||||
|
allow_redirects=False,
|
||||||
|
**adapter_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
extract_cookies_to_jar(self.cookies, prepared_request, resp.raw)
|
||||||
|
|
||||||
|
# extract redirect url, if any, for the next loop
|
||||||
|
url = self.get_redirect_target(resp)
|
||||||
|
yield resp
|
||||||
|
|
||||||
|
def rebuild_auth(self, prepared_request, response):
|
||||||
|
"""When being redirected we may want to strip authentication from the
|
||||||
|
request to avoid leaking credentials. This method intelligently removes
|
||||||
|
and reapplies authentication where possible to avoid credential loss.
|
||||||
|
"""
|
||||||
|
headers = prepared_request.headers
|
||||||
|
url = prepared_request.url
|
||||||
|
|
||||||
|
if "Authorization" in headers and self.should_strip_auth(
|
||||||
|
response.request.url, url
|
||||||
|
):
|
||||||
|
# If we get redirected to a new host, we should strip out any
|
||||||
|
# authentication headers.
|
||||||
|
del headers["Authorization"]
|
||||||
|
|
||||||
|
# .netrc might have more auth for us on our new host.
|
||||||
|
new_auth = get_netrc_auth(url) if self.trust_env else None
|
||||||
|
if new_auth is not None:
|
||||||
|
prepared_request.prepare_auth(new_auth)
|
||||||
|
|
||||||
|
def rebuild_proxies(self, prepared_request, proxies):
|
||||||
|
"""This method re-evaluates the proxy configuration by considering the
|
||||||
|
environment variables. If we are redirected to a URL covered by
|
||||||
|
NO_PROXY, we strip the proxy configuration. Otherwise, we set missing
|
||||||
|
proxy keys for this URL (in case they were stripped by a previous
|
||||||
|
redirect).
|
||||||
|
|
||||||
|
This method also replaces the Proxy-Authorization header where
|
||||||
|
necessary.
|
||||||
|
|
||||||
|
:rtype: dict
|
||||||
|
"""
|
||||||
|
headers = prepared_request.headers
|
||||||
|
scheme = urlparse(prepared_request.url).scheme
|
||||||
|
new_proxies = resolve_proxies(prepared_request, proxies, self.trust_env)
|
||||||
|
|
||||||
|
if "Proxy-Authorization" in headers:
|
||||||
|
del headers["Proxy-Authorization"]
|
||||||
|
|
||||||
|
try:
|
||||||
|
username, password = get_auth_from_url(new_proxies[scheme])
|
||||||
|
except KeyError:
|
||||||
|
username, password = None, None
|
||||||
|
|
||||||
|
# urllib3 handles proxy authorization for us in the standard adapter.
|
||||||
|
# Avoid appending this to TLS tunneled requests where it may be leaked.
|
||||||
|
if not scheme.startswith('https') and username and password:
|
||||||
|
headers["Proxy-Authorization"] = _basic_auth_str(username, password)
|
||||||
|
|
||||||
|
return new_proxies
|
||||||
|
|
||||||
|
def rebuild_method(self, prepared_request, response):
|
||||||
|
"""When being redirected we may want to change the method of the request
|
||||||
|
based on certain specs or browser behavior.
|
||||||
|
"""
|
||||||
|
method = prepared_request.method
|
||||||
|
|
||||||
|
# https://tools.ietf.org/html/rfc7231#section-6.4.4
|
||||||
|
if response.status_code == codes.see_other and method != "HEAD":
|
||||||
|
method = "GET"
|
||||||
|
|
||||||
|
# Do what the browsers do, despite standards...
|
||||||
|
# First, turn 302s into GETs.
|
||||||
|
if response.status_code == codes.found and method != "HEAD":
|
||||||
|
method = "GET"
|
||||||
|
|
||||||
|
# Second, if a POST is responded to with a 301, turn it into a GET.
|
||||||
|
# This bizarre behaviour is explained in Issue 1704.
|
||||||
|
if response.status_code == codes.moved and method == "POST":
|
||||||
|
method = "GET"
|
||||||
|
|
||||||
|
prepared_request.method = method
|
||||||
|
|
||||||
|
|
||||||
|
class Session(SessionRedirectMixin):
|
||||||
|
"""A Requests session.
|
||||||
|
|
||||||
|
Provides cookie persistence, connection-pooling, and configuration.
|
||||||
|
|
||||||
|
Basic Usage::
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> s = requests.Session()
|
||||||
|
>>> s.get('https://httpbin.org/get')
|
||||||
|
<Response [200]>
|
||||||
|
|
||||||
|
Or as a context manager::
|
||||||
|
|
||||||
|
>>> with requests.Session() as s:
|
||||||
|
... s.get('https://httpbin.org/get')
|
||||||
|
<Response [200]>
|
||||||
|
"""
|
||||||
|
|
||||||
|
__attrs__ = [
|
||||||
|
"headers",
|
||||||
|
"cookies",
|
||||||
|
"auth",
|
||||||
|
"proxies",
|
||||||
|
"hooks",
|
||||||
|
"params",
|
||||||
|
"verify",
|
||||||
|
"cert",
|
||||||
|
"adapters",
|
||||||
|
"stream",
|
||||||
|
"trust_env",
|
||||||
|
"max_redirects",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
|
||||||
|
#: A case-insensitive dictionary of headers to be sent on each
|
||||||
|
#: :class:`Request <Request>` sent from this
|
||||||
|
#: :class:`Session <Session>`.
|
||||||
|
self.headers = default_headers()
|
||||||
|
|
||||||
|
#: Default Authentication tuple or object to attach to
|
||||||
|
#: :class:`Request <Request>`.
|
||||||
|
self.auth = None
|
||||||
|
|
||||||
|
#: Dictionary mapping protocol or protocol and host to the URL of the proxy
|
||||||
|
#: (e.g. {'http': 'foo.bar:3128', 'http://host.name': 'foo.bar:4012'}) to
|
||||||
|
#: be used on each :class:`Request <Request>`.
|
||||||
|
self.proxies = {}
|
||||||
|
|
||||||
|
#: Event-handling hooks.
|
||||||
|
self.hooks = default_hooks()
|
||||||
|
|
||||||
|
#: Dictionary of querystring data to attach to each
|
||||||
|
#: :class:`Request <Request>`. The dictionary values may be lists for
|
||||||
|
#: representing multivalued query parameters.
|
||||||
|
self.params = {}
|
||||||
|
|
||||||
|
#: Stream response content default.
|
||||||
|
self.stream = False
|
||||||
|
|
||||||
|
#: SSL Verification default.
|
||||||
|
#: Defaults to `True`, requiring requests to verify the TLS certificate at the
|
||||||
|
#: remote end.
|
||||||
|
#: If verify is set to `False`, requests will accept any TLS certificate
|
||||||
|
#: presented by the server, and will ignore hostname mismatches and/or
|
||||||
|
#: expired certificates, which will make your application vulnerable to
|
||||||
|
#: man-in-the-middle (MitM) attacks.
|
||||||
|
#: Only set this to `False` for testing.
|
||||||
|
self.verify = True
|
||||||
|
|
||||||
|
#: SSL client certificate default, if String, path to ssl client
|
||||||
|
#: cert file (.pem). If Tuple, ('cert', 'key') pair.
|
||||||
|
self.cert = None
|
||||||
|
|
||||||
|
#: Maximum number of redirects allowed. If the request exceeds this
|
||||||
|
#: limit, a :class:`TooManyRedirects` exception is raised.
|
||||||
|
#: This defaults to requests.models.DEFAULT_REDIRECT_LIMIT, which is
|
||||||
|
#: 30.
|
||||||
|
self.max_redirects = DEFAULT_REDIRECT_LIMIT
|
||||||
|
|
||||||
|
#: Trust environment settings for proxy configuration, default
|
||||||
|
#: authentication and similar.
|
||||||
|
self.trust_env = True
|
||||||
|
|
||||||
|
#: A CookieJar containing all currently outstanding cookies set on this
|
||||||
|
#: session. By default it is a
|
||||||
|
#: :class:`RequestsCookieJar <requests.cookies.RequestsCookieJar>`, but
|
||||||
|
#: may be any other ``cookielib.CookieJar`` compatible object.
|
||||||
|
self.cookies = cookiejar_from_dict({})
|
||||||
|
|
||||||
|
# Default connection adapters.
|
||||||
|
self.adapters = OrderedDict()
|
||||||
|
self.mount("https://", HTTPAdapter())
|
||||||
|
self.mount("http://", HTTPAdapter())
|
||||||
|
|
||||||
|
def __enter__(self):
|
||||||
|
return self
|
||||||
|
|
||||||
|
def __exit__(self, *args):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
def prepare_request(self, request):
|
||||||
|
"""Constructs a :class:`PreparedRequest <PreparedRequest>` for
|
||||||
|
transmission and returns it. The :class:`PreparedRequest` has settings
|
||||||
|
merged from the :class:`Request <Request>` instance and those of the
|
||||||
|
:class:`Session`.
|
||||||
|
|
||||||
|
:param request: :class:`Request` instance to prepare with this
|
||||||
|
session's settings.
|
||||||
|
:rtype: requests.PreparedRequest
|
||||||
|
"""
|
||||||
|
cookies = request.cookies or {}
|
||||||
|
|
||||||
|
# Bootstrap CookieJar.
|
||||||
|
if not isinstance(cookies, cookielib.CookieJar):
|
||||||
|
cookies = cookiejar_from_dict(cookies)
|
||||||
|
|
||||||
|
# Merge with session cookies
|
||||||
|
merged_cookies = merge_cookies(
|
||||||
|
merge_cookies(RequestsCookieJar(), self.cookies), cookies
|
||||||
|
)
|
||||||
|
|
||||||
|
# Set environment's basic authentication if not explicitly set.
|
||||||
|
auth = request.auth
|
||||||
|
if self.trust_env and not auth and not self.auth:
|
||||||
|
auth = get_netrc_auth(request.url)
|
||||||
|
|
||||||
|
p = PreparedRequest()
|
||||||
|
p.prepare(
|
||||||
|
method=request.method.upper(),
|
||||||
|
url=request.url,
|
||||||
|
files=request.files,
|
||||||
|
data=request.data,
|
||||||
|
json=request.json,
|
||||||
|
headers=merge_setting(
|
||||||
|
request.headers, self.headers, dict_class=CaseInsensitiveDict
|
||||||
|
),
|
||||||
|
params=merge_setting(request.params, self.params),
|
||||||
|
auth=merge_setting(auth, self.auth),
|
||||||
|
cookies=merged_cookies,
|
||||||
|
hooks=merge_hooks(request.hooks, self.hooks),
|
||||||
|
)
|
||||||
|
return p
|
||||||
|
|
||||||
|
def request(
|
||||||
|
self,
|
||||||
|
method,
|
||||||
|
url,
|
||||||
|
params=None,
|
||||||
|
data=None,
|
||||||
|
headers=None,
|
||||||
|
cookies=None,
|
||||||
|
files=None,
|
||||||
|
auth=None,
|
||||||
|
timeout=None,
|
||||||
|
allow_redirects=True,
|
||||||
|
proxies=None,
|
||||||
|
hooks=None,
|
||||||
|
stream=None,
|
||||||
|
verify=None,
|
||||||
|
cert=None,
|
||||||
|
json=None,
|
||||||
|
):
|
||||||
|
"""Constructs a :class:`Request <Request>`, prepares it and sends it.
|
||||||
|
Returns :class:`Response <Response>` object.
|
||||||
|
|
||||||
|
:param method: method for the new :class:`Request` object.
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param params: (optional) Dictionary or bytes to be sent in the query
|
||||||
|
string for the :class:`Request`.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) json to send in the body of the
|
||||||
|
:class:`Request`.
|
||||||
|
:param headers: (optional) Dictionary of HTTP Headers to send with the
|
||||||
|
:class:`Request`.
|
||||||
|
:param cookies: (optional) Dict or CookieJar object to send with the
|
||||||
|
:class:`Request`.
|
||||||
|
:param files: (optional) Dictionary of ``'filename': file-like-objects``
|
||||||
|
for multipart encoding upload.
|
||||||
|
:param auth: (optional) Auth tuple or callable to enable
|
||||||
|
Basic/Digest/Custom HTTP Auth.
|
||||||
|
:param timeout: (optional) How long to wait for the server to send
|
||||||
|
data before giving up, as a float, or a :ref:`(connect timeout,
|
||||||
|
read timeout) <timeouts>` tuple.
|
||||||
|
:type timeout: float or tuple
|
||||||
|
:param allow_redirects: (optional) Set to True by default.
|
||||||
|
:type allow_redirects: bool
|
||||||
|
:param proxies: (optional) Dictionary mapping protocol or protocol and
|
||||||
|
hostname to the URL of the proxy.
|
||||||
|
:param stream: (optional) whether to immediately download the response
|
||||||
|
content. Defaults to ``False``.
|
||||||
|
:param verify: (optional) Either a boolean, in which case it controls whether we verify
|
||||||
|
the server's TLS certificate, or a string, in which case it must be a path
|
||||||
|
to a CA bundle to use. Defaults to ``True``. When set to
|
||||||
|
``False``, requests will accept any TLS certificate presented by
|
||||||
|
the server, and will ignore hostname mismatches and/or expired
|
||||||
|
certificates, which will make your application vulnerable to
|
||||||
|
man-in-the-middle (MitM) attacks. Setting verify to ``False``
|
||||||
|
may be useful during local development or testing.
|
||||||
|
:param cert: (optional) if String, path to ssl client cert file (.pem).
|
||||||
|
If Tuple, ('cert', 'key') pair.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
# Create the Request.
|
||||||
|
req = Request(
|
||||||
|
method=method.upper(),
|
||||||
|
url=url,
|
||||||
|
headers=headers,
|
||||||
|
files=files,
|
||||||
|
data=data or {},
|
||||||
|
json=json,
|
||||||
|
params=params or {},
|
||||||
|
auth=auth,
|
||||||
|
cookies=cookies,
|
||||||
|
hooks=hooks,
|
||||||
|
)
|
||||||
|
prep = self.prepare_request(req)
|
||||||
|
|
||||||
|
proxies = proxies or {}
|
||||||
|
|
||||||
|
settings = self.merge_environment_settings(
|
||||||
|
prep.url, proxies, stream, verify, cert
|
||||||
|
)
|
||||||
|
|
||||||
|
# Send the request.
|
||||||
|
send_kwargs = {
|
||||||
|
"timeout": timeout,
|
||||||
|
"allow_redirects": allow_redirects,
|
||||||
|
}
|
||||||
|
send_kwargs.update(settings)
|
||||||
|
resp = self.send(prep, **send_kwargs)
|
||||||
|
|
||||||
|
return resp
|
||||||
|
|
||||||
|
def get(self, url, **kwargs):
|
||||||
|
r"""Sends a GET request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
kwargs.setdefault("allow_redirects", True)
|
||||||
|
return self.request("GET", url, **kwargs)
|
||||||
|
|
||||||
|
def options(self, url, **kwargs):
|
||||||
|
r"""Sends a OPTIONS request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
kwargs.setdefault("allow_redirects", True)
|
||||||
|
return self.request("OPTIONS", url, **kwargs)
|
||||||
|
|
||||||
|
def head(self, url, **kwargs):
|
||||||
|
r"""Sends a HEAD request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
kwargs.setdefault("allow_redirects", False)
|
||||||
|
return self.request("HEAD", url, **kwargs)
|
||||||
|
|
||||||
|
def post(self, url, data=None, json=None, **kwargs):
|
||||||
|
r"""Sends a POST request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) json to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.request("POST", url, data=data, json=json, **kwargs)
|
||||||
|
|
||||||
|
def put(self, url, data=None, **kwargs):
|
||||||
|
r"""Sends a PUT request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.request("PUT", url, data=data, **kwargs)
|
||||||
|
|
||||||
|
def patch(self, url, data=None, **kwargs):
|
||||||
|
r"""Sends a PATCH request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.request("PATCH", url, data=data, **kwargs)
|
||||||
|
|
||||||
|
def delete(self, url, **kwargs):
|
||||||
|
r"""Sends a DELETE request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.request("DELETE", url, **kwargs)
|
||||||
|
|
||||||
|
def send(self, request, **kwargs):
|
||||||
|
"""Send a given PreparedRequest.
|
||||||
|
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
# Set defaults that the hooks can utilize to ensure they always have
|
||||||
|
# the correct parameters to reproduce the previous request.
|
||||||
|
kwargs.setdefault("stream", self.stream)
|
||||||
|
kwargs.setdefault("verify", self.verify)
|
||||||
|
kwargs.setdefault("cert", self.cert)
|
||||||
|
if "proxies" not in kwargs:
|
||||||
|
kwargs["proxies"] = resolve_proxies(request, self.proxies, self.trust_env)
|
||||||
|
|
||||||
|
# It's possible that users might accidentally send a Request object.
|
||||||
|
# Guard against that specific failure case.
|
||||||
|
if isinstance(request, Request):
|
||||||
|
raise ValueError("You can only send PreparedRequests.")
|
||||||
|
|
||||||
|
# Set up variables needed for resolve_redirects and dispatching of hooks
|
||||||
|
allow_redirects = kwargs.pop("allow_redirects", True)
|
||||||
|
stream = kwargs.get("stream")
|
||||||
|
hooks = request.hooks
|
||||||
|
|
||||||
|
# Get the appropriate adapter to use
|
||||||
|
adapter = self.get_adapter(url=request.url)
|
||||||
|
|
||||||
|
# Start time (approximately) of the request
|
||||||
|
start = preferred_clock()
|
||||||
|
|
||||||
|
# Send the request
|
||||||
|
r = adapter.send(request, **kwargs)
|
||||||
|
|
||||||
|
# Total elapsed time of the request (approximately)
|
||||||
|
elapsed = preferred_clock() - start
|
||||||
|
r.elapsed = timedelta(seconds=elapsed)
|
||||||
|
|
||||||
|
# Response manipulation hooks
|
||||||
|
r = dispatch_hook("response", hooks, r, **kwargs)
|
||||||
|
|
||||||
|
# Persist cookies
|
||||||
|
if r.history:
|
||||||
|
|
||||||
|
# If the hooks create history then we want those cookies too
|
||||||
|
for resp in r.history:
|
||||||
|
extract_cookies_to_jar(self.cookies, resp.request, resp.raw)
|
||||||
|
|
||||||
|
extract_cookies_to_jar(self.cookies, request, r.raw)
|
||||||
|
|
||||||
|
# Resolve redirects if allowed.
|
||||||
|
if allow_redirects:
|
||||||
|
# Redirect resolving generator.
|
||||||
|
gen = self.resolve_redirects(r, request, **kwargs)
|
||||||
|
history = [resp for resp in gen]
|
||||||
|
else:
|
||||||
|
history = []
|
||||||
|
|
||||||
|
# Shuffle things around if there's history.
|
||||||
|
if history:
|
||||||
|
# Insert the first (original) request at the start
|
||||||
|
history.insert(0, r)
|
||||||
|
# Get the last request made
|
||||||
|
r = history.pop()
|
||||||
|
r.history = history
|
||||||
|
|
||||||
|
# If redirects aren't being followed, store the response on the Request for Response.next().
|
||||||
|
if not allow_redirects:
|
||||||
|
try:
|
||||||
|
r._next = next(
|
||||||
|
self.resolve_redirects(r, request, yield_requests=True, **kwargs)
|
||||||
|
)
|
||||||
|
except StopIteration:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if not stream:
|
||||||
|
r.content
|
||||||
|
|
||||||
|
return r
|
||||||
|
|
||||||
|
def merge_environment_settings(self, url, proxies, stream, verify, cert):
|
||||||
|
"""
|
||||||
|
Check the environment and merge it with some settings.
|
||||||
|
|
||||||
|
:rtype: dict
|
||||||
|
"""
|
||||||
|
# Gather clues from the surrounding environment.
|
||||||
|
if self.trust_env:
|
||||||
|
# Set environment's proxies.
|
||||||
|
no_proxy = proxies.get("no_proxy") if proxies is not None else None
|
||||||
|
env_proxies = get_environ_proxies(url, no_proxy=no_proxy)
|
||||||
|
for (k, v) in env_proxies.items():
|
||||||
|
proxies.setdefault(k, v)
|
||||||
|
|
||||||
|
# Look for requests environment configuration
|
||||||
|
# and be compatible with cURL.
|
||||||
|
if verify is True or verify is None:
|
||||||
|
verify = (
|
||||||
|
os.environ.get("REQUESTS_CA_BUNDLE")
|
||||||
|
or os.environ.get("CURL_CA_BUNDLE")
|
||||||
|
or verify
|
||||||
|
)
|
||||||
|
|
||||||
|
# Merge all the kwargs.
|
||||||
|
proxies = merge_setting(proxies, self.proxies)
|
||||||
|
stream = merge_setting(stream, self.stream)
|
||||||
|
verify = merge_setting(verify, self.verify)
|
||||||
|
cert = merge_setting(cert, self.cert)
|
||||||
|
|
||||||
|
return {"proxies": proxies, "stream": stream, "verify": verify, "cert": cert}
|
||||||
|
|
||||||
|
def get_adapter(self, url):
|
||||||
|
"""
|
||||||
|
Returns the appropriate connection adapter for the given URL.
|
||||||
|
|
||||||
|
:rtype: requests.adapters.BaseAdapter
|
||||||
|
"""
|
||||||
|
for (prefix, adapter) in self.adapters.items():
|
||||||
|
|
||||||
|
if url.lower().startswith(prefix.lower()):
|
||||||
|
return adapter
|
||||||
|
|
||||||
|
# Nothing matches :-/
|
||||||
|
raise InvalidSchema(f"No connection adapters were found for {url!r}")
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
"""Closes all adapters and as such the session"""
|
||||||
|
for v in self.adapters.values():
|
||||||
|
v.close()
|
||||||
|
|
||||||
|
def mount(self, prefix, adapter):
|
||||||
|
"""Registers a connection adapter to a prefix.
|
||||||
|
|
||||||
|
Adapters are sorted in descending order by prefix length.
|
||||||
|
"""
|
||||||
|
self.adapters[prefix] = adapter
|
||||||
|
keys_to_move = [k for k in self.adapters if len(k) < len(prefix)]
|
||||||
|
|
||||||
|
for key in keys_to_move:
|
||||||
|
self.adapters[key] = self.adapters.pop(key)
|
||||||
|
|
||||||
|
def __getstate__(self):
|
||||||
|
state = {attr: getattr(self, attr, None) for attr in self.__attrs__}
|
||||||
|
return state
|
||||||
|
|
||||||
|
def __setstate__(self, state):
|
||||||
|
for attr, value in state.items():
|
||||||
|
setattr(self, attr, value)
|
||||||
|
|
||||||
|
|
||||||
|
def session():
|
||||||
|
"""
|
||||||
|
Returns a :class:`Session` for context-management.
|
||||||
|
|
||||||
|
.. deprecated:: 1.0.0
|
||||||
|
|
||||||
|
This method has been deprecated since version 1.0.0 and is only kept for
|
||||||
|
backwards compatibility. New code should use :class:`~requests.sessions.Session`
|
||||||
|
to create a session. This may be removed at a future date.
|
||||||
|
|
||||||
|
:rtype: Session
|
||||||
|
"""
|
||||||
|
return Session()
|
||||||
|
|
@ -0,0 +1,128 @@
|
||||||
|
r"""
|
||||||
|
The ``codes`` object defines a mapping from common names for HTTP statuses
|
||||||
|
to their numerical codes, accessible either as attributes or as dictionary
|
||||||
|
items.
|
||||||
|
|
||||||
|
Example::
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> requests.codes['temporary_redirect']
|
||||||
|
307
|
||||||
|
>>> requests.codes.teapot
|
||||||
|
418
|
||||||
|
>>> requests.codes['\o/']
|
||||||
|
200
|
||||||
|
|
||||||
|
Some codes have multiple names, and both upper- and lower-case versions of
|
||||||
|
the names are allowed. For example, ``codes.ok``, ``codes.OK``, and
|
||||||
|
``codes.okay`` all correspond to the HTTP status code 200.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from .structures import LookupDict
|
||||||
|
|
||||||
|
_codes = {
|
||||||
|
# Informational.
|
||||||
|
100: ("continue",),
|
||||||
|
101: ("switching_protocols",),
|
||||||
|
102: ("processing",),
|
||||||
|
103: ("checkpoint",),
|
||||||
|
122: ("uri_too_long", "request_uri_too_long"),
|
||||||
|
200: ("ok", "okay", "all_ok", "all_okay", "all_good", "\\o/", "✓"),
|
||||||
|
201: ("created",),
|
||||||
|
202: ("accepted",),
|
||||||
|
203: ("non_authoritative_info", "non_authoritative_information"),
|
||||||
|
204: ("no_content",),
|
||||||
|
205: ("reset_content", "reset"),
|
||||||
|
206: ("partial_content", "partial"),
|
||||||
|
207: ("multi_status", "multiple_status", "multi_stati", "multiple_stati"),
|
||||||
|
208: ("already_reported",),
|
||||||
|
226: ("im_used",),
|
||||||
|
# Redirection.
|
||||||
|
300: ("multiple_choices",),
|
||||||
|
301: ("moved_permanently", "moved", "\\o-"),
|
||||||
|
302: ("found",),
|
||||||
|
303: ("see_other", "other"),
|
||||||
|
304: ("not_modified",),
|
||||||
|
305: ("use_proxy",),
|
||||||
|
306: ("switch_proxy",),
|
||||||
|
307: ("temporary_redirect", "temporary_moved", "temporary"),
|
||||||
|
308: (
|
||||||
|
"permanent_redirect",
|
||||||
|
"resume_incomplete",
|
||||||
|
"resume",
|
||||||
|
), # "resume" and "resume_incomplete" to be removed in 3.0
|
||||||
|
# Client Error.
|
||||||
|
400: ("bad_request", "bad"),
|
||||||
|
401: ("unauthorized",),
|
||||||
|
402: ("payment_required", "payment"),
|
||||||
|
403: ("forbidden",),
|
||||||
|
404: ("not_found", "-o-"),
|
||||||
|
405: ("method_not_allowed", "not_allowed"),
|
||||||
|
406: ("not_acceptable",),
|
||||||
|
407: ("proxy_authentication_required", "proxy_auth", "proxy_authentication"),
|
||||||
|
408: ("request_timeout", "timeout"),
|
||||||
|
409: ("conflict",),
|
||||||
|
410: ("gone",),
|
||||||
|
411: ("length_required",),
|
||||||
|
412: ("precondition_failed", "precondition"),
|
||||||
|
413: ("request_entity_too_large",),
|
||||||
|
414: ("request_uri_too_large",),
|
||||||
|
415: ("unsupported_media_type", "unsupported_media", "media_type"),
|
||||||
|
416: (
|
||||||
|
"requested_range_not_satisfiable",
|
||||||
|
"requested_range",
|
||||||
|
"range_not_satisfiable",
|
||||||
|
),
|
||||||
|
417: ("expectation_failed",),
|
||||||
|
418: ("im_a_teapot", "teapot", "i_am_a_teapot"),
|
||||||
|
421: ("misdirected_request",),
|
||||||
|
422: ("unprocessable_entity", "unprocessable"),
|
||||||
|
423: ("locked",),
|
||||||
|
424: ("failed_dependency", "dependency"),
|
||||||
|
425: ("unordered_collection", "unordered"),
|
||||||
|
426: ("upgrade_required", "upgrade"),
|
||||||
|
428: ("precondition_required", "precondition"),
|
||||||
|
429: ("too_many_requests", "too_many"),
|
||||||
|
431: ("header_fields_too_large", "fields_too_large"),
|
||||||
|
444: ("no_response", "none"),
|
||||||
|
449: ("retry_with", "retry"),
|
||||||
|
450: ("blocked_by_windows_parental_controls", "parental_controls"),
|
||||||
|
451: ("unavailable_for_legal_reasons", "legal_reasons"),
|
||||||
|
499: ("client_closed_request",),
|
||||||
|
# Server Error.
|
||||||
|
500: ("internal_server_error", "server_error", "/o\\", "✗"),
|
||||||
|
501: ("not_implemented",),
|
||||||
|
502: ("bad_gateway",),
|
||||||
|
503: ("service_unavailable", "unavailable"),
|
||||||
|
504: ("gateway_timeout",),
|
||||||
|
505: ("http_version_not_supported", "http_version"),
|
||||||
|
506: ("variant_also_negotiates",),
|
||||||
|
507: ("insufficient_storage",),
|
||||||
|
509: ("bandwidth_limit_exceeded", "bandwidth"),
|
||||||
|
510: ("not_extended",),
|
||||||
|
511: ("network_authentication_required", "network_auth", "network_authentication"),
|
||||||
|
}
|
||||||
|
|
||||||
|
codes = LookupDict(name="status_codes")
|
||||||
|
|
||||||
|
|
||||||
|
def _init():
|
||||||
|
for code, titles in _codes.items():
|
||||||
|
for title in titles:
|
||||||
|
setattr(codes, title, code)
|
||||||
|
if not title.startswith(("\\", "/")):
|
||||||
|
setattr(codes, title.upper(), code)
|
||||||
|
|
||||||
|
def doc(code):
|
||||||
|
names = ", ".join(f"``{n}``" for n in _codes[code])
|
||||||
|
return "* %d: %s" % (code, names)
|
||||||
|
|
||||||
|
global __doc__
|
||||||
|
__doc__ = (
|
||||||
|
__doc__ + "\n" + "\n".join(doc(code) for code in sorted(_codes))
|
||||||
|
if __doc__ is not None
|
||||||
|
else None
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
_init()
|
||||||
|
|
@ -0,0 +1,99 @@
|
||||||
|
"""
|
||||||
|
requests.structures
|
||||||
|
~~~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
Data structures that power Requests.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from collections import OrderedDict
|
||||||
|
|
||||||
|
from .compat import Mapping, MutableMapping
|
||||||
|
|
||||||
|
|
||||||
|
class CaseInsensitiveDict(MutableMapping):
|
||||||
|
"""A case-insensitive ``dict``-like object.
|
||||||
|
|
||||||
|
Implements all methods and operations of
|
||||||
|
``MutableMapping`` as well as dict's ``copy``. Also
|
||||||
|
provides ``lower_items``.
|
||||||
|
|
||||||
|
All keys are expected to be strings. The structure remembers the
|
||||||
|
case of the last key to be set, and ``iter(instance)``,
|
||||||
|
``keys()``, ``items()``, ``iterkeys()``, and ``iteritems()``
|
||||||
|
will contain case-sensitive keys. However, querying and contains
|
||||||
|
testing is case insensitive::
|
||||||
|
|
||||||
|
cid = CaseInsensitiveDict()
|
||||||
|
cid['Accept'] = 'application/json'
|
||||||
|
cid['aCCEPT'] == 'application/json' # True
|
||||||
|
list(cid) == ['Accept'] # True
|
||||||
|
|
||||||
|
For example, ``headers['content-encoding']`` will return the
|
||||||
|
value of a ``'Content-Encoding'`` response header, regardless
|
||||||
|
of how the header name was originally stored.
|
||||||
|
|
||||||
|
If the constructor, ``.update``, or equality comparison
|
||||||
|
operations are given keys that have equal ``.lower()``s, the
|
||||||
|
behavior is undefined.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, data=None, **kwargs):
|
||||||
|
self._store = OrderedDict()
|
||||||
|
if data is None:
|
||||||
|
data = {}
|
||||||
|
self.update(data, **kwargs)
|
||||||
|
|
||||||
|
def __setitem__(self, key, value):
|
||||||
|
# Use the lowercased key for lookups, but store the actual
|
||||||
|
# key alongside the value.
|
||||||
|
self._store[key.lower()] = (key, value)
|
||||||
|
|
||||||
|
def __getitem__(self, key):
|
||||||
|
return self._store[key.lower()][1]
|
||||||
|
|
||||||
|
def __delitem__(self, key):
|
||||||
|
del self._store[key.lower()]
|
||||||
|
|
||||||
|
def __iter__(self):
|
||||||
|
return (casedkey for casedkey, mappedvalue in self._store.values())
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return len(self._store)
|
||||||
|
|
||||||
|
def lower_items(self):
|
||||||
|
"""Like iteritems(), but with all lowercase keys."""
|
||||||
|
return ((lowerkey, keyval[1]) for (lowerkey, keyval) in self._store.items())
|
||||||
|
|
||||||
|
def __eq__(self, other):
|
||||||
|
if isinstance(other, Mapping):
|
||||||
|
other = CaseInsensitiveDict(other)
|
||||||
|
else:
|
||||||
|
return NotImplemented
|
||||||
|
# Compare insensitively
|
||||||
|
return dict(self.lower_items()) == dict(other.lower_items())
|
||||||
|
|
||||||
|
# Copy is required
|
||||||
|
def copy(self):
|
||||||
|
return CaseInsensitiveDict(self._store.values())
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return str(dict(self.items()))
|
||||||
|
|
||||||
|
|
||||||
|
class LookupDict(dict):
|
||||||
|
"""Dictionary lookup object."""
|
||||||
|
|
||||||
|
def __init__(self, name=None):
|
||||||
|
self.name = name
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return f"<lookup '{self.name}'>"
|
||||||
|
|
||||||
|
def __getitem__(self, key):
|
||||||
|
# We allow fall-through here, so values default to None
|
||||||
|
|
||||||
|
return self.__dict__.get(key, None)
|
||||||
|
|
||||||
|
def get(self, key, default=None):
|
||||||
|
return self.__dict__.get(key, default)
|
||||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1 @@
|
||||||
|
pip
|
||||||
|
|
@ -0,0 +1,154 @@
|
||||||
|
Metadata-Version: 2.1
|
||||||
|
Name: urllib3
|
||||||
|
Version: 2.2.0
|
||||||
|
Summary: HTTP library with thread-safe connection pooling, file post, and more.
|
||||||
|
Project-URL: Changelog, https://github.com/urllib3/urllib3/blob/main/CHANGES.rst
|
||||||
|
Project-URL: Documentation, https://urllib3.readthedocs.io
|
||||||
|
Project-URL: Code, https://github.com/urllib3/urllib3
|
||||||
|
Project-URL: Issue tracker, https://github.com/urllib3/urllib3/issues
|
||||||
|
Author-email: Andrey Petrov <andrey.petrov@shazow.net>
|
||||||
|
Maintainer-email: Seth Michael Larson <sethmichaellarson@gmail.com>, Quentin Pradet <quentin@pradet.me>, Illia Volochii <illia.volochii@gmail.com>
|
||||||
|
License-File: LICENSE.txt
|
||||||
|
Keywords: filepost,http,httplib,https,pooling,ssl,threadsafe,urllib
|
||||||
|
Classifier: Environment :: Web Environment
|
||||||
|
Classifier: Intended Audience :: Developers
|
||||||
|
Classifier: License :: OSI Approved :: MIT License
|
||||||
|
Classifier: Operating System :: OS Independent
|
||||||
|
Classifier: Programming Language :: Python
|
||||||
|
Classifier: Programming Language :: Python :: 3
|
||||||
|
Classifier: Programming Language :: Python :: 3 :: Only
|
||||||
|
Classifier: Programming Language :: Python :: 3.8
|
||||||
|
Classifier: Programming Language :: Python :: 3.9
|
||||||
|
Classifier: Programming Language :: Python :: 3.10
|
||||||
|
Classifier: Programming Language :: Python :: 3.11
|
||||||
|
Classifier: Programming Language :: Python :: 3.12
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: CPython
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
||||||
|
Classifier: Topic :: Internet :: WWW/HTTP
|
||||||
|
Classifier: Topic :: Software Development :: Libraries
|
||||||
|
Requires-Python: >=3.8
|
||||||
|
Provides-Extra: brotli
|
||||||
|
Requires-Dist: brotli>=1.0.9; (platform_python_implementation == 'CPython') and extra == 'brotli'
|
||||||
|
Requires-Dist: brotlicffi>=0.8.0; (platform_python_implementation != 'CPython') and extra == 'brotli'
|
||||||
|
Provides-Extra: h2
|
||||||
|
Requires-Dist: h2<5,>=4; extra == 'h2'
|
||||||
|
Provides-Extra: socks
|
||||||
|
Requires-Dist: pysocks!=1.5.7,<2.0,>=1.5.6; extra == 'socks'
|
||||||
|
Provides-Extra: zstd
|
||||||
|
Requires-Dist: zstandard>=0.18.0; extra == 'zstd'
|
||||||
|
Description-Content-Type: text/markdown
|
||||||
|
|
||||||
|
<h1 align="center">
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
</h1>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://pypi.org/project/urllib3"><img alt="PyPI Version" src="https://img.shields.io/pypi/v/urllib3.svg?maxAge=86400" /></a>
|
||||||
|
<a href="https://pypi.org/project/urllib3"><img alt="Python Versions" src="https://img.shields.io/pypi/pyversions/urllib3.svg?maxAge=86400" /></a>
|
||||||
|
<a href="https://discord.gg/urllib3"><img alt="Join our Discord" src="https://img.shields.io/discord/756342717725933608?color=%237289da&label=discord" /></a>
|
||||||
|
<a href="https://github.com/urllib3/urllib3/actions?query=workflow%3ACI"><img alt="Coverage Status" src="https://img.shields.io/badge/coverage-100%25-success" /></a>
|
||||||
|
<a href="https://github.com/urllib3/urllib3/actions?query=workflow%3ACI"><img alt="Build Status on GitHub" src="https://github.com/urllib3/urllib3/workflows/CI/badge.svg" /></a>
|
||||||
|
<a href="https://urllib3.readthedocs.io"><img alt="Documentation Status" src="https://readthedocs.org/projects/urllib3/badge/?version=latest" /></a><br>
|
||||||
|
<a href="https://deps.dev/pypi/urllib3"><img alt="OpenSSF Scorecard" src="https://api.securityscorecards.dev/projects/github.com/urllib3/urllib3/badge" /></a>
|
||||||
|
<a href="https://slsa.dev"><img alt="SLSA 3" src="https://slsa.dev/images/gh-badge-level3.svg" /></a>
|
||||||
|
<a href="https://bestpractices.coreinfrastructure.org/projects/6227"><img alt="CII Best Practices" src="https://bestpractices.coreinfrastructure.org/projects/6227/badge" /></a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
urllib3 is a powerful, *user-friendly* HTTP client for Python. Much of the
|
||||||
|
Python ecosystem already uses urllib3 and you should too.
|
||||||
|
urllib3 brings many critical features that are missing from the Python
|
||||||
|
standard libraries:
|
||||||
|
|
||||||
|
- Thread safety.
|
||||||
|
- Connection pooling.
|
||||||
|
- Client-side SSL/TLS verification.
|
||||||
|
- File uploads with multipart encoding.
|
||||||
|
- Helpers for retrying requests and dealing with HTTP redirects.
|
||||||
|
- Support for gzip, deflate, brotli, and zstd encoding.
|
||||||
|
- Proxy support for HTTP and SOCKS.
|
||||||
|
- 100% test coverage.
|
||||||
|
|
||||||
|
urllib3 is powerful and easy to use:
|
||||||
|
|
||||||
|
```python3
|
||||||
|
>>> import urllib3
|
||||||
|
>>> resp = urllib3.request("GET", "http://httpbin.org/robots.txt")
|
||||||
|
>>> resp.status
|
||||||
|
200
|
||||||
|
>>> resp.data
|
||||||
|
b"User-agent: *\nDisallow: /deny\n"
|
||||||
|
```
|
||||||
|
|
||||||
|
## Installing
|
||||||
|
|
||||||
|
urllib3 can be installed with [pip](https://pip.pypa.io):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ python -m pip install urllib3
|
||||||
|
```
|
||||||
|
|
||||||
|
Alternatively, you can grab the latest source code from [GitHub](https://github.com/urllib3/urllib3):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ git clone https://github.com/urllib3/urllib3.git
|
||||||
|
$ cd urllib3
|
||||||
|
$ pip install .
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Documentation
|
||||||
|
|
||||||
|
urllib3 has usage and reference documentation at [urllib3.readthedocs.io](https://urllib3.readthedocs.io).
|
||||||
|
|
||||||
|
|
||||||
|
## Community
|
||||||
|
|
||||||
|
urllib3 has a [community Discord channel](https://discord.gg/urllib3) for asking questions and
|
||||||
|
collaborating with other contributors. Drop by and say hello 👋
|
||||||
|
|
||||||
|
|
||||||
|
## Contributing
|
||||||
|
|
||||||
|
urllib3 happily accepts contributions. Please see our
|
||||||
|
[contributing documentation](https://urllib3.readthedocs.io/en/latest/contributing.html)
|
||||||
|
for some tips on getting started.
|
||||||
|
|
||||||
|
|
||||||
|
## Security Disclosures
|
||||||
|
|
||||||
|
To report a security vulnerability, please use the
|
||||||
|
[Tidelift security contact](https://tidelift.com/security).
|
||||||
|
Tidelift will coordinate the fix and disclosure with maintainers.
|
||||||
|
|
||||||
|
|
||||||
|
## Maintainers
|
||||||
|
|
||||||
|
- [@sethmlarson](https://github.com/sethmlarson) (Seth M. Larson)
|
||||||
|
- [@pquentin](https://github.com/pquentin) (Quentin Pradet)
|
||||||
|
- [@illia-v](https://github.com/illia-v) (Illia Volochii)
|
||||||
|
- [@theacodes](https://github.com/theacodes) (Thea Flowers)
|
||||||
|
- [@haikuginger](https://github.com/haikuginger) (Jess Shapiro)
|
||||||
|
- [@lukasa](https://github.com/lukasa) (Cory Benfield)
|
||||||
|
- [@sigmavirus24](https://github.com/sigmavirus24) (Ian Stapleton Cordasco)
|
||||||
|
- [@shazow](https://github.com/shazow) (Andrey Petrov)
|
||||||
|
|
||||||
|
👋
|
||||||
|
|
||||||
|
|
||||||
|
## Sponsorship
|
||||||
|
|
||||||
|
If your company benefits from this library, please consider [sponsoring its
|
||||||
|
development](https://urllib3.readthedocs.io/en/latest/sponsors.html).
|
||||||
|
|
||||||
|
|
||||||
|
## For Enterprise
|
||||||
|
|
||||||
|
Professional support for urllib3 is available as part of the [Tidelift
|
||||||
|
Subscription][1]. Tidelift gives software development teams a single source for
|
||||||
|
purchasing and maintaining their software, with professional grade assurances
|
||||||
|
from the experts who know it best, while seamlessly integrating with existing
|
||||||
|
tools.
|
||||||
|
|
||||||
|
[1]: https://tidelift.com/subscription/pkg/pypi-urllib3?utm_source=pypi-urllib3&utm_medium=referral&utm_campaign=readme
|
||||||
|
|
@ -0,0 +1,75 @@
|
||||||
|
urllib3-2.2.0.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
||||||
|
urllib3-2.2.0.dist-info/METADATA,sha256=EckehT6EBglredzg6pVihGegkLhgQX0VDBQdC18n7Ms,6434
|
||||||
|
urllib3-2.2.0.dist-info/RECORD,,
|
||||||
|
urllib3-2.2.0.dist-info/WHEEL,sha256=TJPnKdtrSue7xZ_AVGkp9YXcvDrobsjBds1du3Nx6dc,87
|
||||||
|
urllib3-2.2.0.dist-info/licenses/LICENSE.txt,sha256=Ew46ZNX91dCWp1JpRjSn2d8oRGnehuVzIQAmgEHj1oY,1093
|
||||||
|
urllib3/__init__.py,sha256=-YL9TODqQli1N0-0TycGEBd-jN5OcSPpfcwoBpM5Rzo,6967
|
||||||
|
urllib3/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/_base_connection.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/_collections.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/_request_methods.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/_version.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/connection.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/connectionpool.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/exceptions.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/fields.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/filepost.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/http2.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/poolmanager.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/response.cpython-312.pyc,,
|
||||||
|
urllib3/_base_connection.py,sha256=p-DOG_Me7-sJXO1R9VgDpNmdVU_kIS8VtaC7ptEllA0,5640
|
||||||
|
urllib3/_collections.py,sha256=vzKA-7X-9resOamEWq52uV1nHshChjbYDvz47H0mMjw,17400
|
||||||
|
urllib3/_request_methods.py,sha256=ucEpHQyQf06b9o1RxKLkCpzGH0ct-v7X2xGpU6rmmlo,9984
|
||||||
|
urllib3/_version.py,sha256=lu3gLNu437ysCDrCscVx2x8Fw5IuHkn9CNKf45kCRJQ,98
|
||||||
|
urllib3/connection.py,sha256=8jYYvoqr4WQ54L6l91desZ5yNZp0HM4hbCgyrOhQeRQ,34678
|
||||||
|
urllib3/connectionpool.py,sha256=akTwtMPo3ZyoLgiMm9tyIe9RpTaw0r0sTz1vodHkHZg,43495
|
||||||
|
urllib3/contrib/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
||||||
|
urllib3/contrib/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/__pycache__/pyopenssl.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/__pycache__/socks.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__init__.py,sha256=u6KNgzjlFZbuAAXa_ybCR7gQ71VJESnF-IIdDA73brw,733
|
||||||
|
urllib3/contrib/emscripten/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__pycache__/connection.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__pycache__/fetch.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__pycache__/request.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__pycache__/response.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/connection.py,sha256=AyIJ9kVIyTGDfIeAGmVlv-fKCb3MRbOF_1wmhOCAHGI,8579
|
||||||
|
urllib3/contrib/emscripten/emscripten_fetch_worker.js,sha256=CDfYF_9CDobtx2lGidyJ1zjDEvwNT5F-dchmVWXDh0E,3655
|
||||||
|
urllib3/contrib/emscripten/fetch.py,sha256=V49l0aJYE8cTjgkhhCV3zNcO9kqBpN7A0mfux570uEY,14090
|
||||||
|
urllib3/contrib/emscripten/request.py,sha256=mL28szy1KvE3NJhWor5jNmarp8gwplDU-7gwGZY5g0Q,566
|
||||||
|
urllib3/contrib/emscripten/response.py,sha256=wIDmdJ4doFWqLl5s86l9n0V70gFjQ2HWaPgz69jM52E,9546
|
||||||
|
urllib3/contrib/pyopenssl.py,sha256=xNGNJFIF8kHpFYeL1N1SoD1hg6b8_UiwdmAChzPA8wA,19129
|
||||||
|
urllib3/contrib/socks.py,sha256=4mAkiLhQ7liuuTMAmAzUox5JkKzeuETG5i3an4A6vc8,7562
|
||||||
|
urllib3/exceptions.py,sha256=rOVHX1HOAb_TZwJZTqprLRTNAJQUWnrXDYaR8XBk1tY,9385
|
||||||
|
urllib3/fields.py,sha256=XvSMfnSMqeOn9o-6Eb3Fl9MN2MNjiHsmEff_HR5jhEI,11026
|
||||||
|
urllib3/filepost.py,sha256=-9qJT11cNGjO9dqnI20-oErZuTvNaM18xZZPCjZSbOE,2395
|
||||||
|
urllib3/http2.py,sha256=c_YALLgS8fYYYMaNB8FNCRIAomxW8LwVP9TfCXJXOzE,7641
|
||||||
|
urllib3/poolmanager.py,sha256=fcC3OwjFKxha06NsOORwbZOzrVt1pyY-bNCbKiqC0l8,22935
|
||||||
|
urllib3/py.typed,sha256=UaCuPFa3H8UAakbt-5G8SPacldTOGvJv18pPjUJ5gDY,93
|
||||||
|
urllib3/response.py,sha256=x5IJkjqBqKqByv58s129IDn9JDVTN7jOxBoBQYq4yqo,43310
|
||||||
|
urllib3/util/__init__.py,sha256=-qeS0QceivazvBEKDNFCAI-6ACcdDOE4TMvo7SLNlAQ,1001
|
||||||
|
urllib3/util/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/connection.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/proxy.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/request.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/response.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/retry.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/ssl_.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/ssl_match_hostname.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/ssltransport.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/timeout.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/url.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/util.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/wait.cpython-312.pyc,,
|
||||||
|
urllib3/util/connection.py,sha256=QeUUEuNmhznpuKNPL-B0IVOkMdMCu8oJX62OC0Vpzug,4462
|
||||||
|
urllib3/util/proxy.py,sha256=seP8-Q5B6bB0dMtwPj-YcZZQ30vHuLqRu-tI0JZ2fzs,1148
|
||||||
|
urllib3/util/request.py,sha256=1yOLebpPT8QKw1x3kQ7klLiesbGqpxV6iAk89kvR5FA,8072
|
||||||
|
urllib3/util/response.py,sha256=vQE639uoEhj1vpjEdxu5lNIhJCSUZkd7pqllUI0BZOA,3374
|
||||||
|
urllib3/util/retry.py,sha256=WB-7x1m7fQH_-Qqtrk2OGvz93GvBTxc-pRn8Vf3p4mg,18384
|
||||||
|
urllib3/util/ssl_.py,sha256=FeymdS68RggEROwMB9VLGSqLHq2hRUKnIbQC_bCpGJI,19109
|
||||||
|
urllib3/util/ssl_match_hostname.py,sha256=gaWqixoYtQ_GKO8fcRGFj3VXeMoqyxQQuUTPgWeiL_M,5812
|
||||||
|
urllib3/util/ssltransport.py,sha256=SF__JQXVcHBQniFJZp3P9q-UeHM310WVwcBwqT9dCLE,9034
|
||||||
|
urllib3/util/timeout.py,sha256=4eT1FVeZZU7h7mYD1Jq2OXNe4fxekdNvhoWUkZusRpA,10346
|
||||||
|
urllib3/util/url.py,sha256=wHORhp80RAXyTlAIkTqLFzSrkU7J34ZDxX-tN65MBZk,15213
|
||||||
|
urllib3/util/util.py,sha256=j3lbZK1jPyiwD34T8IgJzdWEZVT-4E-0vYIJi9UjeNA,1146
|
||||||
|
urllib3/util/wait.py,sha256=_ph8IrUR3sqPqi0OopQgJUlH4wzkGeM5CiyA7XGGtmI,4423
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
Wheel-Version: 1.0
|
||||||
|
Generator: hatchling 1.21.1
|
||||||
|
Root-Is-Purelib: true
|
||||||
|
Tag: py3-none-any
|
||||||
|
|
@ -0,0 +1,21 @@
|
||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2008-2020 Andrey Petrov and contributors.
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
|
|
@ -0,0 +1,211 @@
|
||||||
|
"""
|
||||||
|
Python HTTP library with thread-safe connection pooling, file post support, user friendly, and more
|
||||||
|
"""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
# Set default logging handler to avoid "No handler found" warnings.
|
||||||
|
import logging
|
||||||
|
import sys
|
||||||
|
import typing
|
||||||
|
import warnings
|
||||||
|
from logging import NullHandler
|
||||||
|
|
||||||
|
from . import exceptions
|
||||||
|
from ._base_connection import _TYPE_BODY
|
||||||
|
from ._collections import HTTPHeaderDict
|
||||||
|
from ._version import __version__
|
||||||
|
from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool, connection_from_url
|
||||||
|
from .filepost import _TYPE_FIELDS, encode_multipart_formdata
|
||||||
|
from .poolmanager import PoolManager, ProxyManager, proxy_from_url
|
||||||
|
from .response import BaseHTTPResponse, HTTPResponse
|
||||||
|
from .util.request import make_headers
|
||||||
|
from .util.retry import Retry
|
||||||
|
from .util.timeout import Timeout
|
||||||
|
|
||||||
|
# Ensure that Python is compiled with OpenSSL 1.1.1+
|
||||||
|
# If the 'ssl' module isn't available at all that's
|
||||||
|
# fine, we only care if the module is available.
|
||||||
|
try:
|
||||||
|
import ssl
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
if not ssl.OPENSSL_VERSION.startswith("OpenSSL "): # Defensive:
|
||||||
|
warnings.warn(
|
||||||
|
"urllib3 v2 only supports OpenSSL 1.1.1+, currently "
|
||||||
|
f"the 'ssl' module is compiled with {ssl.OPENSSL_VERSION!r}. "
|
||||||
|
"See: https://github.com/urllib3/urllib3/issues/3020",
|
||||||
|
exceptions.NotOpenSSLWarning,
|
||||||
|
)
|
||||||
|
elif ssl.OPENSSL_VERSION_INFO < (1, 1, 1): # Defensive:
|
||||||
|
raise ImportError(
|
||||||
|
"urllib3 v2 only supports OpenSSL 1.1.1+, currently "
|
||||||
|
f"the 'ssl' module is compiled with {ssl.OPENSSL_VERSION!r}. "
|
||||||
|
"See: https://github.com/urllib3/urllib3/issues/2168"
|
||||||
|
)
|
||||||
|
|
||||||
|
__author__ = "Andrey Petrov (andrey.petrov@shazow.net)"
|
||||||
|
__license__ = "MIT"
|
||||||
|
__version__ = __version__
|
||||||
|
|
||||||
|
__all__ = (
|
||||||
|
"HTTPConnectionPool",
|
||||||
|
"HTTPHeaderDict",
|
||||||
|
"HTTPSConnectionPool",
|
||||||
|
"PoolManager",
|
||||||
|
"ProxyManager",
|
||||||
|
"HTTPResponse",
|
||||||
|
"Retry",
|
||||||
|
"Timeout",
|
||||||
|
"add_stderr_logger",
|
||||||
|
"connection_from_url",
|
||||||
|
"disable_warnings",
|
||||||
|
"encode_multipart_formdata",
|
||||||
|
"make_headers",
|
||||||
|
"proxy_from_url",
|
||||||
|
"request",
|
||||||
|
"BaseHTTPResponse",
|
||||||
|
)
|
||||||
|
|
||||||
|
logging.getLogger(__name__).addHandler(NullHandler())
|
||||||
|
|
||||||
|
|
||||||
|
def add_stderr_logger(
|
||||||
|
level: int = logging.DEBUG,
|
||||||
|
) -> logging.StreamHandler[typing.TextIO]:
|
||||||
|
"""
|
||||||
|
Helper for quickly adding a StreamHandler to the logger. Useful for
|
||||||
|
debugging.
|
||||||
|
|
||||||
|
Returns the handler after adding it.
|
||||||
|
"""
|
||||||
|
# This method needs to be in this __init__.py to get the __name__ correct
|
||||||
|
# even if urllib3 is vendored within another package.
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
handler = logging.StreamHandler()
|
||||||
|
handler.setFormatter(logging.Formatter("%(asctime)s %(levelname)s %(message)s"))
|
||||||
|
logger.addHandler(handler)
|
||||||
|
logger.setLevel(level)
|
||||||
|
logger.debug("Added a stderr logging handler to logger: %s", __name__)
|
||||||
|
return handler
|
||||||
|
|
||||||
|
|
||||||
|
# ... Clean up.
|
||||||
|
del NullHandler
|
||||||
|
|
||||||
|
|
||||||
|
# All warning filters *must* be appended unless you're really certain that they
|
||||||
|
# shouldn't be: otherwise, it's very hard for users to use most Python
|
||||||
|
# mechanisms to silence them.
|
||||||
|
# SecurityWarning's always go off by default.
|
||||||
|
warnings.simplefilter("always", exceptions.SecurityWarning, append=True)
|
||||||
|
# InsecurePlatformWarning's don't vary between requests, so we keep it default.
|
||||||
|
warnings.simplefilter("default", exceptions.InsecurePlatformWarning, append=True)
|
||||||
|
|
||||||
|
|
||||||
|
def disable_warnings(category: type[Warning] = exceptions.HTTPWarning) -> None:
|
||||||
|
"""
|
||||||
|
Helper for quickly disabling all urllib3 warnings.
|
||||||
|
"""
|
||||||
|
warnings.simplefilter("ignore", category)
|
||||||
|
|
||||||
|
|
||||||
|
_DEFAULT_POOL = PoolManager()
|
||||||
|
|
||||||
|
|
||||||
|
def request(
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
*,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
fields: _TYPE_FIELDS | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
preload_content: bool | None = True,
|
||||||
|
decode_content: bool | None = True,
|
||||||
|
redirect: bool | None = True,
|
||||||
|
retries: Retry | bool | int | None = None,
|
||||||
|
timeout: Timeout | float | int | None = 3,
|
||||||
|
json: typing.Any | None = None,
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
A convenience, top-level request method. It uses a module-global ``PoolManager`` instance.
|
||||||
|
Therefore, its side effects could be shared across dependencies relying on it.
|
||||||
|
To avoid side effects create a new ``PoolManager`` instance and use it instead.
|
||||||
|
The method does not accept low-level ``**urlopen_kw`` keyword arguments.
|
||||||
|
|
||||||
|
:param method:
|
||||||
|
HTTP request method (such as GET, POST, PUT, etc.)
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
The URL to perform the request on.
|
||||||
|
|
||||||
|
:param body:
|
||||||
|
Data to send in the request body, either :class:`str`, :class:`bytes`,
|
||||||
|
an iterable of :class:`str`/:class:`bytes`, or a file-like object.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Data to encode and send in the request body.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Dictionary of custom headers to send, such as User-Agent,
|
||||||
|
If-None-Match, etc.
|
||||||
|
|
||||||
|
:param bool preload_content:
|
||||||
|
If True, the response's body will be preloaded into memory.
|
||||||
|
|
||||||
|
:param bool decode_content:
|
||||||
|
If True, will attempt to decode the body based on the
|
||||||
|
'content-encoding' header.
|
||||||
|
|
||||||
|
:param redirect:
|
||||||
|
If True, automatically handle redirects (status codes 301, 302,
|
||||||
|
303, 307, 308). Each redirect counts as a retry. Disabling retries
|
||||||
|
will disable redirect, too.
|
||||||
|
|
||||||
|
:param retries:
|
||||||
|
Configure the number of retries to allow before raising a
|
||||||
|
:class:`~urllib3.exceptions.MaxRetryError` exception.
|
||||||
|
|
||||||
|
Pass ``None`` to retry until you receive a response. Pass a
|
||||||
|
:class:`~urllib3.util.retry.Retry` object for fine-grained control
|
||||||
|
over different types of retries.
|
||||||
|
Pass an integer number to retry connection errors that many times,
|
||||||
|
but no other types of errors. Pass zero to never retry.
|
||||||
|
|
||||||
|
If ``False``, then retries are disabled and any exception is raised
|
||||||
|
immediately. Also, instead of raising a MaxRetryError on redirects,
|
||||||
|
the redirect response will be returned.
|
||||||
|
|
||||||
|
:type retries: :class:`~urllib3.util.retry.Retry`, False, or an int.
|
||||||
|
|
||||||
|
:param timeout:
|
||||||
|
If specified, overrides the default timeout for this one
|
||||||
|
request. It may be a float (in seconds) or an instance of
|
||||||
|
:class:`urllib3.util.Timeout`.
|
||||||
|
|
||||||
|
:param json:
|
||||||
|
Data to encode and send as JSON with UTF-encoded in the request body.
|
||||||
|
The ``"Content-Type"`` header will be set to ``"application/json"``
|
||||||
|
unless specified otherwise.
|
||||||
|
"""
|
||||||
|
|
||||||
|
return _DEFAULT_POOL.request(
|
||||||
|
method,
|
||||||
|
url,
|
||||||
|
body=body,
|
||||||
|
fields=fields,
|
||||||
|
headers=headers,
|
||||||
|
preload_content=preload_content,
|
||||||
|
decode_content=decode_content,
|
||||||
|
redirect=redirect,
|
||||||
|
retries=retries,
|
||||||
|
timeout=timeout,
|
||||||
|
json=json,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
if sys.platform == "emscripten":
|
||||||
|
from .contrib.emscripten import inject_into_urllib3 # noqa: 401
|
||||||
|
|
||||||
|
inject_into_urllib3()
|
||||||
|
|
@ -0,0 +1,172 @@
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import typing
|
||||||
|
|
||||||
|
from .util.connection import _TYPE_SOCKET_OPTIONS
|
||||||
|
from .util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT
|
||||||
|
from .util.url import Url
|
||||||
|
|
||||||
|
_TYPE_BODY = typing.Union[bytes, typing.IO[typing.Any], typing.Iterable[bytes], str]
|
||||||
|
|
||||||
|
|
||||||
|
class ProxyConfig(typing.NamedTuple):
|
||||||
|
ssl_context: ssl.SSLContext | None
|
||||||
|
use_forwarding_for_https: bool
|
||||||
|
assert_hostname: None | str | Literal[False]
|
||||||
|
assert_fingerprint: str | None
|
||||||
|
|
||||||
|
|
||||||
|
class _ResponseOptions(typing.NamedTuple):
|
||||||
|
# TODO: Remove this in favor of a better
|
||||||
|
# HTTP request/response lifecycle tracking.
|
||||||
|
request_method: str
|
||||||
|
request_url: str
|
||||||
|
preload_content: bool
|
||||||
|
decode_content: bool
|
||||||
|
enforce_content_length: bool
|
||||||
|
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
import ssl
|
||||||
|
from typing import Literal, Protocol
|
||||||
|
|
||||||
|
from .response import BaseHTTPResponse
|
||||||
|
|
||||||
|
class BaseHTTPConnection(Protocol):
|
||||||
|
default_port: typing.ClassVar[int]
|
||||||
|
default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]
|
||||||
|
|
||||||
|
host: str
|
||||||
|
port: int
|
||||||
|
timeout: None | (
|
||||||
|
float
|
||||||
|
) # Instance doesn't store _DEFAULT_TIMEOUT, must be resolved.
|
||||||
|
blocksize: int
|
||||||
|
source_address: tuple[str, int] | None
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None
|
||||||
|
|
||||||
|
proxy: Url | None
|
||||||
|
proxy_config: ProxyConfig | None
|
||||||
|
|
||||||
|
is_verified: bool
|
||||||
|
proxy_is_verified: bool | None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 8192,
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None = ...,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
) -> None:
|
||||||
|
...
|
||||||
|
|
||||||
|
def set_tunnel(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
scheme: str = "http",
|
||||||
|
) -> None:
|
||||||
|
...
|
||||||
|
|
||||||
|
def connect(self) -> None:
|
||||||
|
...
|
||||||
|
|
||||||
|
def request(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
# We know *at least* botocore is depending on the order of the
|
||||||
|
# first 3 parameters so to be safe we only mark the later ones
|
||||||
|
# as keyword-only to ensure we have space to extend.
|
||||||
|
*,
|
||||||
|
chunked: bool = False,
|
||||||
|
preload_content: bool = True,
|
||||||
|
decode_content: bool = True,
|
||||||
|
enforce_content_length: bool = True,
|
||||||
|
) -> None:
|
||||||
|
...
|
||||||
|
|
||||||
|
def getresponse(self) -> BaseHTTPResponse:
|
||||||
|
...
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
...
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_closed(self) -> bool:
|
||||||
|
"""Whether the connection either is brand new or has been previously closed.
|
||||||
|
If this property is True then both ``is_connected`` and ``has_connected_to_proxy``
|
||||||
|
properties must be False.
|
||||||
|
"""
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_connected(self) -> bool:
|
||||||
|
"""Whether the connection is actively connected to any origin (proxy or target)"""
|
||||||
|
|
||||||
|
@property
|
||||||
|
def has_connected_to_proxy(self) -> bool:
|
||||||
|
"""Whether the connection has successfully connected to its proxy.
|
||||||
|
This returns False if no proxy is in use. Used to determine whether
|
||||||
|
errors are coming from the proxy layer or from tunnelling to the target origin.
|
||||||
|
"""
|
||||||
|
|
||||||
|
class BaseHTTPSConnection(BaseHTTPConnection, Protocol):
|
||||||
|
default_port: typing.ClassVar[int]
|
||||||
|
default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]
|
||||||
|
|
||||||
|
# Certificate verification methods
|
||||||
|
cert_reqs: int | str | None
|
||||||
|
assert_hostname: None | str | Literal[False]
|
||||||
|
assert_fingerprint: str | None
|
||||||
|
ssl_context: ssl.SSLContext | None
|
||||||
|
|
||||||
|
# Trusted CAs
|
||||||
|
ca_certs: str | None
|
||||||
|
ca_cert_dir: str | None
|
||||||
|
ca_cert_data: None | str | bytes
|
||||||
|
|
||||||
|
# TLS version
|
||||||
|
ssl_minimum_version: int | None
|
||||||
|
ssl_maximum_version: int | None
|
||||||
|
ssl_version: int | str | None # Deprecated
|
||||||
|
|
||||||
|
# Client certificates
|
||||||
|
cert_file: str | None
|
||||||
|
key_file: str | None
|
||||||
|
key_password: str | None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 16384,
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None = ...,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
cert_reqs: int | str | None = None,
|
||||||
|
assert_hostname: None | str | Literal[False] = None,
|
||||||
|
assert_fingerprint: str | None = None,
|
||||||
|
server_hostname: str | None = None,
|
||||||
|
ssl_context: ssl.SSLContext | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
ssl_minimum_version: int | None = None,
|
||||||
|
ssl_maximum_version: int | None = None,
|
||||||
|
ssl_version: int | str | None = None, # Deprecated
|
||||||
|
cert_file: str | None = None,
|
||||||
|
key_file: str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
) -> None:
|
||||||
|
...
|
||||||
|
|
@ -0,0 +1,483 @@
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import typing
|
||||||
|
from collections import OrderedDict
|
||||||
|
from enum import Enum, auto
|
||||||
|
from threading import RLock
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
# We can only import Protocol if TYPE_CHECKING because it's a development
|
||||||
|
# dependency, and is not available at runtime.
|
||||||
|
from typing import Protocol
|
||||||
|
|
||||||
|
from typing_extensions import Self
|
||||||
|
|
||||||
|
class HasGettableStringKeys(Protocol):
|
||||||
|
def keys(self) -> typing.Iterator[str]:
|
||||||
|
...
|
||||||
|
|
||||||
|
def __getitem__(self, key: str) -> str:
|
||||||
|
...
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = ["RecentlyUsedContainer", "HTTPHeaderDict"]
|
||||||
|
|
||||||
|
|
||||||
|
# Key type
|
||||||
|
_KT = typing.TypeVar("_KT")
|
||||||
|
# Value type
|
||||||
|
_VT = typing.TypeVar("_VT")
|
||||||
|
# Default type
|
||||||
|
_DT = typing.TypeVar("_DT")
|
||||||
|
|
||||||
|
ValidHTTPHeaderSource = typing.Union[
|
||||||
|
"HTTPHeaderDict",
|
||||||
|
typing.Mapping[str, str],
|
||||||
|
typing.Iterable[typing.Tuple[str, str]],
|
||||||
|
"HasGettableStringKeys",
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
class _Sentinel(Enum):
|
||||||
|
not_passed = auto()
|
||||||
|
|
||||||
|
|
||||||
|
def ensure_can_construct_http_header_dict(
|
||||||
|
potential: object,
|
||||||
|
) -> ValidHTTPHeaderSource | None:
|
||||||
|
if isinstance(potential, HTTPHeaderDict):
|
||||||
|
return potential
|
||||||
|
elif isinstance(potential, typing.Mapping):
|
||||||
|
# Full runtime checking of the contents of a Mapping is expensive, so for the
|
||||||
|
# purposes of typechecking, we assume that any Mapping is the right shape.
|
||||||
|
return typing.cast(typing.Mapping[str, str], potential)
|
||||||
|
elif isinstance(potential, typing.Iterable):
|
||||||
|
# Similarly to Mapping, full runtime checking of the contents of an Iterable is
|
||||||
|
# expensive, so for the purposes of typechecking, we assume that any Iterable
|
||||||
|
# is the right shape.
|
||||||
|
return typing.cast(typing.Iterable[typing.Tuple[str, str]], potential)
|
||||||
|
elif hasattr(potential, "keys") and hasattr(potential, "__getitem__"):
|
||||||
|
return typing.cast("HasGettableStringKeys", potential)
|
||||||
|
else:
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
class RecentlyUsedContainer(typing.Generic[_KT, _VT], typing.MutableMapping[_KT, _VT]):
|
||||||
|
"""
|
||||||
|
Provides a thread-safe dict-like container which maintains up to
|
||||||
|
``maxsize`` keys while throwing away the least-recently-used keys beyond
|
||||||
|
``maxsize``.
|
||||||
|
|
||||||
|
:param maxsize:
|
||||||
|
Maximum number of recent elements to retain.
|
||||||
|
|
||||||
|
:param dispose_func:
|
||||||
|
Every time an item is evicted from the container,
|
||||||
|
``dispose_func(value)`` is called. Callback which will get called
|
||||||
|
"""
|
||||||
|
|
||||||
|
_container: typing.OrderedDict[_KT, _VT]
|
||||||
|
_maxsize: int
|
||||||
|
dispose_func: typing.Callable[[_VT], None] | None
|
||||||
|
lock: RLock
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
maxsize: int = 10,
|
||||||
|
dispose_func: typing.Callable[[_VT], None] | None = None,
|
||||||
|
) -> None:
|
||||||
|
super().__init__()
|
||||||
|
self._maxsize = maxsize
|
||||||
|
self.dispose_func = dispose_func
|
||||||
|
self._container = OrderedDict()
|
||||||
|
self.lock = RLock()
|
||||||
|
|
||||||
|
def __getitem__(self, key: _KT) -> _VT:
|
||||||
|
# Re-insert the item, moving it to the end of the eviction line.
|
||||||
|
with self.lock:
|
||||||
|
item = self._container.pop(key)
|
||||||
|
self._container[key] = item
|
||||||
|
return item
|
||||||
|
|
||||||
|
def __setitem__(self, key: _KT, value: _VT) -> None:
|
||||||
|
evicted_item = None
|
||||||
|
with self.lock:
|
||||||
|
# Possibly evict the existing value of 'key'
|
||||||
|
try:
|
||||||
|
# If the key exists, we'll overwrite it, which won't change the
|
||||||
|
# size of the pool. Because accessing a key should move it to
|
||||||
|
# the end of the eviction line, we pop it out first.
|
||||||
|
evicted_item = key, self._container.pop(key)
|
||||||
|
self._container[key] = value
|
||||||
|
except KeyError:
|
||||||
|
# When the key does not exist, we insert the value first so that
|
||||||
|
# evicting works in all cases, including when self._maxsize is 0
|
||||||
|
self._container[key] = value
|
||||||
|
if len(self._container) > self._maxsize:
|
||||||
|
# If we didn't evict an existing value, and we've hit our maximum
|
||||||
|
# size, then we have to evict the least recently used item from
|
||||||
|
# the beginning of the container.
|
||||||
|
evicted_item = self._container.popitem(last=False)
|
||||||
|
|
||||||
|
# After releasing the lock on the pool, dispose of any evicted value.
|
||||||
|
if evicted_item is not None and self.dispose_func:
|
||||||
|
_, evicted_value = evicted_item
|
||||||
|
self.dispose_func(evicted_value)
|
||||||
|
|
||||||
|
def __delitem__(self, key: _KT) -> None:
|
||||||
|
with self.lock:
|
||||||
|
value = self._container.pop(key)
|
||||||
|
|
||||||
|
if self.dispose_func:
|
||||||
|
self.dispose_func(value)
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
with self.lock:
|
||||||
|
return len(self._container)
|
||||||
|
|
||||||
|
def __iter__(self) -> typing.NoReturn:
|
||||||
|
raise NotImplementedError(
|
||||||
|
"Iteration over this class is unlikely to be threadsafe."
|
||||||
|
)
|
||||||
|
|
||||||
|
def clear(self) -> None:
|
||||||
|
with self.lock:
|
||||||
|
# Copy pointers to all values, then wipe the mapping
|
||||||
|
values = list(self._container.values())
|
||||||
|
self._container.clear()
|
||||||
|
|
||||||
|
if self.dispose_func:
|
||||||
|
for value in values:
|
||||||
|
self.dispose_func(value)
|
||||||
|
|
||||||
|
def keys(self) -> set[_KT]: # type: ignore[override]
|
||||||
|
with self.lock:
|
||||||
|
return set(self._container.keys())
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPHeaderDictItemView(typing.Set[typing.Tuple[str, str]]):
|
||||||
|
"""
|
||||||
|
HTTPHeaderDict is unusual for a Mapping[str, str] in that it has two modes of
|
||||||
|
address.
|
||||||
|
|
||||||
|
If we directly try to get an item with a particular name, we will get a string
|
||||||
|
back that is the concatenated version of all the values:
|
||||||
|
|
||||||
|
>>> d['X-Header-Name']
|
||||||
|
'Value1, Value2, Value3'
|
||||||
|
|
||||||
|
However, if we iterate over an HTTPHeaderDict's items, we will optionally combine
|
||||||
|
these values based on whether combine=True was called when building up the dictionary
|
||||||
|
|
||||||
|
>>> d = HTTPHeaderDict({"A": "1", "B": "foo"})
|
||||||
|
>>> d.add("A", "2", combine=True)
|
||||||
|
>>> d.add("B", "bar")
|
||||||
|
>>> list(d.items())
|
||||||
|
[
|
||||||
|
('A', '1, 2'),
|
||||||
|
('B', 'foo'),
|
||||||
|
('B', 'bar'),
|
||||||
|
]
|
||||||
|
|
||||||
|
This class conforms to the interface required by the MutableMapping ABC while
|
||||||
|
also giving us the nonstandard iteration behavior we want; items with duplicate
|
||||||
|
keys, ordered by time of first insertion.
|
||||||
|
"""
|
||||||
|
|
||||||
|
_headers: HTTPHeaderDict
|
||||||
|
|
||||||
|
def __init__(self, headers: HTTPHeaderDict) -> None:
|
||||||
|
self._headers = headers
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
return len(list(self._headers.iteritems()))
|
||||||
|
|
||||||
|
def __iter__(self) -> typing.Iterator[tuple[str, str]]:
|
||||||
|
return self._headers.iteritems()
|
||||||
|
|
||||||
|
def __contains__(self, item: object) -> bool:
|
||||||
|
if isinstance(item, tuple) and len(item) == 2:
|
||||||
|
passed_key, passed_val = item
|
||||||
|
if isinstance(passed_key, str) and isinstance(passed_val, str):
|
||||||
|
return self._headers._has_value_for_header(passed_key, passed_val)
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPHeaderDict(typing.MutableMapping[str, str]):
|
||||||
|
"""
|
||||||
|
:param headers:
|
||||||
|
An iterable of field-value pairs. Must not contain multiple field names
|
||||||
|
when compared case-insensitively.
|
||||||
|
|
||||||
|
:param kwargs:
|
||||||
|
Additional field-value pairs to pass in to ``dict.update``.
|
||||||
|
|
||||||
|
A ``dict`` like container for storing HTTP Headers.
|
||||||
|
|
||||||
|
Field names are stored and compared case-insensitively in compliance with
|
||||||
|
RFC 7230. Iteration provides the first case-sensitive key seen for each
|
||||||
|
case-insensitive pair.
|
||||||
|
|
||||||
|
Using ``__setitem__`` syntax overwrites fields that compare equal
|
||||||
|
case-insensitively in order to maintain ``dict``'s api. For fields that
|
||||||
|
compare equal, instead create a new ``HTTPHeaderDict`` and use ``.add``
|
||||||
|
in a loop.
|
||||||
|
|
||||||
|
If multiple fields that are equal case-insensitively are passed to the
|
||||||
|
constructor or ``.update``, the behavior is undefined and some will be
|
||||||
|
lost.
|
||||||
|
|
||||||
|
>>> headers = HTTPHeaderDict()
|
||||||
|
>>> headers.add('Set-Cookie', 'foo=bar')
|
||||||
|
>>> headers.add('set-cookie', 'baz=quxx')
|
||||||
|
>>> headers['content-length'] = '7'
|
||||||
|
>>> headers['SET-cookie']
|
||||||
|
'foo=bar, baz=quxx'
|
||||||
|
>>> headers['Content-Length']
|
||||||
|
'7'
|
||||||
|
"""
|
||||||
|
|
||||||
|
_container: typing.MutableMapping[str, list[str]]
|
||||||
|
|
||||||
|
def __init__(self, headers: ValidHTTPHeaderSource | None = None, **kwargs: str):
|
||||||
|
super().__init__()
|
||||||
|
self._container = {} # 'dict' is insert-ordered
|
||||||
|
if headers is not None:
|
||||||
|
if isinstance(headers, HTTPHeaderDict):
|
||||||
|
self._copy_from(headers)
|
||||||
|
else:
|
||||||
|
self.extend(headers)
|
||||||
|
if kwargs:
|
||||||
|
self.extend(kwargs)
|
||||||
|
|
||||||
|
def __setitem__(self, key: str, val: str) -> None:
|
||||||
|
# avoid a bytes/str comparison by decoding before httplib
|
||||||
|
if isinstance(key, bytes):
|
||||||
|
key = key.decode("latin-1")
|
||||||
|
self._container[key.lower()] = [key, val]
|
||||||
|
|
||||||
|
def __getitem__(self, key: str) -> str:
|
||||||
|
val = self._container[key.lower()]
|
||||||
|
return ", ".join(val[1:])
|
||||||
|
|
||||||
|
def __delitem__(self, key: str) -> None:
|
||||||
|
del self._container[key.lower()]
|
||||||
|
|
||||||
|
def __contains__(self, key: object) -> bool:
|
||||||
|
if isinstance(key, str):
|
||||||
|
return key.lower() in self._container
|
||||||
|
return False
|
||||||
|
|
||||||
|
def setdefault(self, key: str, default: str = "") -> str:
|
||||||
|
return super().setdefault(key, default)
|
||||||
|
|
||||||
|
def __eq__(self, other: object) -> bool:
|
||||||
|
maybe_constructable = ensure_can_construct_http_header_dict(other)
|
||||||
|
if maybe_constructable is None:
|
||||||
|
return False
|
||||||
|
else:
|
||||||
|
other_as_http_header_dict = type(self)(maybe_constructable)
|
||||||
|
|
||||||
|
return {k.lower(): v for k, v in self.itermerged()} == {
|
||||||
|
k.lower(): v for k, v in other_as_http_header_dict.itermerged()
|
||||||
|
}
|
||||||
|
|
||||||
|
def __ne__(self, other: object) -> bool:
|
||||||
|
return not self.__eq__(other)
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
return len(self._container)
|
||||||
|
|
||||||
|
def __iter__(self) -> typing.Iterator[str]:
|
||||||
|
# Only provide the originally cased names
|
||||||
|
for vals in self._container.values():
|
||||||
|
yield vals[0]
|
||||||
|
|
||||||
|
def discard(self, key: str) -> None:
|
||||||
|
try:
|
||||||
|
del self[key]
|
||||||
|
except KeyError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def add(self, key: str, val: str, *, combine: bool = False) -> None:
|
||||||
|
"""Adds a (name, value) pair, doesn't overwrite the value if it already
|
||||||
|
exists.
|
||||||
|
|
||||||
|
If this is called with combine=True, instead of adding a new header value
|
||||||
|
as a distinct item during iteration, this will instead append the value to
|
||||||
|
any existing header value with a comma. If no existing header value exists
|
||||||
|
for the key, then the value will simply be added, ignoring the combine parameter.
|
||||||
|
|
||||||
|
>>> headers = HTTPHeaderDict(foo='bar')
|
||||||
|
>>> headers.add('Foo', 'baz')
|
||||||
|
>>> headers['foo']
|
||||||
|
'bar, baz'
|
||||||
|
>>> list(headers.items())
|
||||||
|
[('foo', 'bar'), ('foo', 'baz')]
|
||||||
|
>>> headers.add('foo', 'quz', combine=True)
|
||||||
|
>>> list(headers.items())
|
||||||
|
[('foo', 'bar, baz, quz')]
|
||||||
|
"""
|
||||||
|
# avoid a bytes/str comparison by decoding before httplib
|
||||||
|
if isinstance(key, bytes):
|
||||||
|
key = key.decode("latin-1")
|
||||||
|
key_lower = key.lower()
|
||||||
|
new_vals = [key, val]
|
||||||
|
# Keep the common case aka no item present as fast as possible
|
||||||
|
vals = self._container.setdefault(key_lower, new_vals)
|
||||||
|
if new_vals is not vals:
|
||||||
|
# if there are values here, then there is at least the initial
|
||||||
|
# key/value pair
|
||||||
|
assert len(vals) >= 2
|
||||||
|
if combine:
|
||||||
|
vals[-1] = vals[-1] + ", " + val
|
||||||
|
else:
|
||||||
|
vals.append(val)
|
||||||
|
|
||||||
|
def extend(self, *args: ValidHTTPHeaderSource, **kwargs: str) -> None:
|
||||||
|
"""Generic import function for any type of header-like object.
|
||||||
|
Adapted version of MutableMapping.update in order to insert items
|
||||||
|
with self.add instead of self.__setitem__
|
||||||
|
"""
|
||||||
|
if len(args) > 1:
|
||||||
|
raise TypeError(
|
||||||
|
f"extend() takes at most 1 positional arguments ({len(args)} given)"
|
||||||
|
)
|
||||||
|
other = args[0] if len(args) >= 1 else ()
|
||||||
|
|
||||||
|
if isinstance(other, HTTPHeaderDict):
|
||||||
|
for key, val in other.iteritems():
|
||||||
|
self.add(key, val)
|
||||||
|
elif isinstance(other, typing.Mapping):
|
||||||
|
for key, val in other.items():
|
||||||
|
self.add(key, val)
|
||||||
|
elif isinstance(other, typing.Iterable):
|
||||||
|
other = typing.cast(typing.Iterable[typing.Tuple[str, str]], other)
|
||||||
|
for key, value in other:
|
||||||
|
self.add(key, value)
|
||||||
|
elif hasattr(other, "keys") and hasattr(other, "__getitem__"):
|
||||||
|
# THIS IS NOT A TYPESAFE BRANCH
|
||||||
|
# In this branch, the object has a `keys` attr but is not a Mapping or any of
|
||||||
|
# the other types indicated in the method signature. We do some stuff with
|
||||||
|
# it as though it partially implements the Mapping interface, but we're not
|
||||||
|
# doing that stuff safely AT ALL.
|
||||||
|
for key in other.keys():
|
||||||
|
self.add(key, other[key])
|
||||||
|
|
||||||
|
for key, value in kwargs.items():
|
||||||
|
self.add(key, value)
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def getlist(self, key: str) -> list[str]:
|
||||||
|
...
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def getlist(self, key: str, default: _DT) -> list[str] | _DT:
|
||||||
|
...
|
||||||
|
|
||||||
|
def getlist(
|
||||||
|
self, key: str, default: _Sentinel | _DT = _Sentinel.not_passed
|
||||||
|
) -> list[str] | _DT:
|
||||||
|
"""Returns a list of all the values for the named field. Returns an
|
||||||
|
empty list if the key doesn't exist."""
|
||||||
|
try:
|
||||||
|
vals = self._container[key.lower()]
|
||||||
|
except KeyError:
|
||||||
|
if default is _Sentinel.not_passed:
|
||||||
|
# _DT is unbound; empty list is instance of List[str]
|
||||||
|
return []
|
||||||
|
# _DT is bound; default is instance of _DT
|
||||||
|
return default
|
||||||
|
else:
|
||||||
|
# _DT may or may not be bound; vals[1:] is instance of List[str], which
|
||||||
|
# meets our external interface requirement of `Union[List[str], _DT]`.
|
||||||
|
return vals[1:]
|
||||||
|
|
||||||
|
def _prepare_for_method_change(self) -> Self:
|
||||||
|
"""
|
||||||
|
Remove content-specific header fields before changing the request
|
||||||
|
method to GET or HEAD according to RFC 9110, Section 15.4.
|
||||||
|
"""
|
||||||
|
content_specific_headers = [
|
||||||
|
"Content-Encoding",
|
||||||
|
"Content-Language",
|
||||||
|
"Content-Location",
|
||||||
|
"Content-Type",
|
||||||
|
"Content-Length",
|
||||||
|
"Digest",
|
||||||
|
"Last-Modified",
|
||||||
|
]
|
||||||
|
for header in content_specific_headers:
|
||||||
|
self.discard(header)
|
||||||
|
return self
|
||||||
|
|
||||||
|
# Backwards compatibility for httplib
|
||||||
|
getheaders = getlist
|
||||||
|
getallmatchingheaders = getlist
|
||||||
|
iget = getlist
|
||||||
|
|
||||||
|
# Backwards compatibility for http.cookiejar
|
||||||
|
get_all = getlist
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
return f"{type(self).__name__}({dict(self.itermerged())})"
|
||||||
|
|
||||||
|
def _copy_from(self, other: HTTPHeaderDict) -> None:
|
||||||
|
for key in other:
|
||||||
|
val = other.getlist(key)
|
||||||
|
self._container[key.lower()] = [key, *val]
|
||||||
|
|
||||||
|
def copy(self) -> HTTPHeaderDict:
|
||||||
|
clone = type(self)()
|
||||||
|
clone._copy_from(self)
|
||||||
|
return clone
|
||||||
|
|
||||||
|
def iteritems(self) -> typing.Iterator[tuple[str, str]]:
|
||||||
|
"""Iterate over all header lines, including duplicate ones."""
|
||||||
|
for key in self:
|
||||||
|
vals = self._container[key.lower()]
|
||||||
|
for val in vals[1:]:
|
||||||
|
yield vals[0], val
|
||||||
|
|
||||||
|
def itermerged(self) -> typing.Iterator[tuple[str, str]]:
|
||||||
|
"""Iterate over all headers, merging duplicate ones together."""
|
||||||
|
for key in self:
|
||||||
|
val = self._container[key.lower()]
|
||||||
|
yield val[0], ", ".join(val[1:])
|
||||||
|
|
||||||
|
def items(self) -> HTTPHeaderDictItemView: # type: ignore[override]
|
||||||
|
return HTTPHeaderDictItemView(self)
|
||||||
|
|
||||||
|
def _has_value_for_header(self, header_name: str, potential_value: str) -> bool:
|
||||||
|
if header_name in self:
|
||||||
|
return potential_value in self._container[header_name.lower()][1:]
|
||||||
|
return False
|
||||||
|
|
||||||
|
def __ior__(self, other: object) -> HTTPHeaderDict:
|
||||||
|
# Supports extending a header dict in-place using operator |=
|
||||||
|
# combining items with add instead of __setitem__
|
||||||
|
maybe_constructable = ensure_can_construct_http_header_dict(other)
|
||||||
|
if maybe_constructable is None:
|
||||||
|
return NotImplemented
|
||||||
|
self.extend(maybe_constructable)
|
||||||
|
return self
|
||||||
|
|
||||||
|
def __or__(self, other: object) -> HTTPHeaderDict:
|
||||||
|
# Supports merging header dicts using operator |
|
||||||
|
# combining items with add instead of __setitem__
|
||||||
|
maybe_constructable = ensure_can_construct_http_header_dict(other)
|
||||||
|
if maybe_constructable is None:
|
||||||
|
return NotImplemented
|
||||||
|
result = self.copy()
|
||||||
|
result.extend(maybe_constructable)
|
||||||
|
return result
|
||||||
|
|
||||||
|
def __ror__(self, other: object) -> HTTPHeaderDict:
|
||||||
|
# Supports merging header dicts using operator | when other is on left side
|
||||||
|
# combining items with add instead of __setitem__
|
||||||
|
maybe_constructable = ensure_can_construct_http_header_dict(other)
|
||||||
|
if maybe_constructable is None:
|
||||||
|
return NotImplemented
|
||||||
|
result = type(self)(maybe_constructable)
|
||||||
|
result.extend(self)
|
||||||
|
return result
|
||||||
|
|
@ -0,0 +1,279 @@
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import json as _json
|
||||||
|
import typing
|
||||||
|
from urllib.parse import urlencode
|
||||||
|
|
||||||
|
from ._base_connection import _TYPE_BODY
|
||||||
|
from ._collections import HTTPHeaderDict
|
||||||
|
from .filepost import _TYPE_FIELDS, encode_multipart_formdata
|
||||||
|
from .response import BaseHTTPResponse
|
||||||
|
|
||||||
|
__all__ = ["RequestMethods"]
|
||||||
|
|
||||||
|
_TYPE_ENCODE_URL_FIELDS = typing.Union[
|
||||||
|
typing.Sequence[typing.Tuple[str, typing.Union[str, bytes]]],
|
||||||
|
typing.Mapping[str, typing.Union[str, bytes]],
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
class RequestMethods:
|
||||||
|
"""
|
||||||
|
Convenience mixin for classes who implement a :meth:`urlopen` method, such
|
||||||
|
as :class:`urllib3.HTTPConnectionPool` and
|
||||||
|
:class:`urllib3.PoolManager`.
|
||||||
|
|
||||||
|
Provides behavior for making common types of HTTP request methods and
|
||||||
|
decides which type of request field encoding to use.
|
||||||
|
|
||||||
|
Specifically,
|
||||||
|
|
||||||
|
:meth:`.request_encode_url` is for sending requests whose fields are
|
||||||
|
encoded in the URL (such as GET, HEAD, DELETE).
|
||||||
|
|
||||||
|
:meth:`.request_encode_body` is for sending requests whose fields are
|
||||||
|
encoded in the *body* of the request using multipart or www-form-urlencoded
|
||||||
|
(such as for POST, PUT, PATCH).
|
||||||
|
|
||||||
|
:meth:`.request` is for making any kind of request, it will look up the
|
||||||
|
appropriate encoding format and use one of the above two methods to make
|
||||||
|
the request.
|
||||||
|
|
||||||
|
Initializer parameters:
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Headers to include with all requests, unless other headers are given
|
||||||
|
explicitly.
|
||||||
|
"""
|
||||||
|
|
||||||
|
_encode_url_methods = {"DELETE", "GET", "HEAD", "OPTIONS"}
|
||||||
|
|
||||||
|
def __init__(self, headers: typing.Mapping[str, str] | None = None) -> None:
|
||||||
|
self.headers = headers or {}
|
||||||
|
|
||||||
|
def urlopen(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
encode_multipart: bool = True,
|
||||||
|
multipart_boundary: str | None = None,
|
||||||
|
**kw: typing.Any,
|
||||||
|
) -> BaseHTTPResponse: # Abstract
|
||||||
|
raise NotImplementedError(
|
||||||
|
"Classes extending RequestMethods must implement "
|
||||||
|
"their own ``urlopen`` method."
|
||||||
|
)
|
||||||
|
|
||||||
|
def request(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
fields: _TYPE_FIELDS | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
json: typing.Any | None = None,
|
||||||
|
**urlopen_kw: typing.Any,
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
Make a request using :meth:`urlopen` with the appropriate encoding of
|
||||||
|
``fields`` based on the ``method`` used.
|
||||||
|
|
||||||
|
This is a convenience method that requires the least amount of manual
|
||||||
|
effort. It can be used in most situations, while still having the
|
||||||
|
option to drop down to more specific methods when necessary, such as
|
||||||
|
:meth:`request_encode_url`, :meth:`request_encode_body`,
|
||||||
|
or even the lowest level :meth:`urlopen`.
|
||||||
|
|
||||||
|
:param method:
|
||||||
|
HTTP request method (such as GET, POST, PUT, etc.)
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
The URL to perform the request on.
|
||||||
|
|
||||||
|
:param body:
|
||||||
|
Data to send in the request body, either :class:`str`, :class:`bytes`,
|
||||||
|
an iterable of :class:`str`/:class:`bytes`, or a file-like object.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Data to encode and send in the request body. Values are processed
|
||||||
|
by :func:`urllib.parse.urlencode`.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Dictionary of custom headers to send, such as User-Agent,
|
||||||
|
If-None-Match, etc. If None, pool headers are used. If provided,
|
||||||
|
these headers completely replace any pool-specific headers.
|
||||||
|
|
||||||
|
:param json:
|
||||||
|
Data to encode and send as JSON with UTF-encoded in the request body.
|
||||||
|
The ``"Content-Type"`` header will be set to ``"application/json"``
|
||||||
|
unless specified otherwise.
|
||||||
|
"""
|
||||||
|
method = method.upper()
|
||||||
|
|
||||||
|
if json is not None and body is not None:
|
||||||
|
raise TypeError(
|
||||||
|
"request got values for both 'body' and 'json' parameters which are mutually exclusive"
|
||||||
|
)
|
||||||
|
|
||||||
|
if json is not None:
|
||||||
|
if headers is None:
|
||||||
|
headers = self.headers
|
||||||
|
|
||||||
|
if not ("content-type" in map(str.lower, headers.keys())):
|
||||||
|
headers = HTTPHeaderDict(headers)
|
||||||
|
headers["Content-Type"] = "application/json"
|
||||||
|
|
||||||
|
body = _json.dumps(json, separators=(",", ":"), ensure_ascii=False).encode(
|
||||||
|
"utf-8"
|
||||||
|
)
|
||||||
|
|
||||||
|
if body is not None:
|
||||||
|
urlopen_kw["body"] = body
|
||||||
|
|
||||||
|
if method in self._encode_url_methods:
|
||||||
|
return self.request_encode_url(
|
||||||
|
method,
|
||||||
|
url,
|
||||||
|
fields=fields, # type: ignore[arg-type]
|
||||||
|
headers=headers,
|
||||||
|
**urlopen_kw,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
return self.request_encode_body(
|
||||||
|
method, url, fields=fields, headers=headers, **urlopen_kw
|
||||||
|
)
|
||||||
|
|
||||||
|
def request_encode_url(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
fields: _TYPE_ENCODE_URL_FIELDS | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
**urlopen_kw: str,
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
Make a request using :meth:`urlopen` with the ``fields`` encoded in
|
||||||
|
the url. This is useful for request methods like GET, HEAD, DELETE, etc.
|
||||||
|
|
||||||
|
:param method:
|
||||||
|
HTTP request method (such as GET, POST, PUT, etc.)
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
The URL to perform the request on.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Data to encode and send in the request body.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Dictionary of custom headers to send, such as User-Agent,
|
||||||
|
If-None-Match, etc. If None, pool headers are used. If provided,
|
||||||
|
these headers completely replace any pool-specific headers.
|
||||||
|
"""
|
||||||
|
if headers is None:
|
||||||
|
headers = self.headers
|
||||||
|
|
||||||
|
extra_kw: dict[str, typing.Any] = {"headers": headers}
|
||||||
|
extra_kw.update(urlopen_kw)
|
||||||
|
|
||||||
|
if fields:
|
||||||
|
url += "?" + urlencode(fields)
|
||||||
|
|
||||||
|
return self.urlopen(method, url, **extra_kw)
|
||||||
|
|
||||||
|
def request_encode_body(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
fields: _TYPE_FIELDS | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
encode_multipart: bool = True,
|
||||||
|
multipart_boundary: str | None = None,
|
||||||
|
**urlopen_kw: str,
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
Make a request using :meth:`urlopen` with the ``fields`` encoded in
|
||||||
|
the body. This is useful for request methods like POST, PUT, PATCH, etc.
|
||||||
|
|
||||||
|
When ``encode_multipart=True`` (default), then
|
||||||
|
:func:`urllib3.encode_multipart_formdata` is used to encode
|
||||||
|
the payload with the appropriate content type. Otherwise
|
||||||
|
:func:`urllib.parse.urlencode` is used with the
|
||||||
|
'application/x-www-form-urlencoded' content type.
|
||||||
|
|
||||||
|
Multipart encoding must be used when posting files, and it's reasonably
|
||||||
|
safe to use it in other times too. However, it may break request
|
||||||
|
signing, such as with OAuth.
|
||||||
|
|
||||||
|
Supports an optional ``fields`` parameter of key/value strings AND
|
||||||
|
key/filetuple. A filetuple is a (filename, data, MIME type) tuple where
|
||||||
|
the MIME type is optional. For example::
|
||||||
|
|
||||||
|
fields = {
|
||||||
|
'foo': 'bar',
|
||||||
|
'fakefile': ('foofile.txt', 'contents of foofile'),
|
||||||
|
'realfile': ('barfile.txt', open('realfile').read()),
|
||||||
|
'typedfile': ('bazfile.bin', open('bazfile').read(),
|
||||||
|
'image/jpeg'),
|
||||||
|
'nonamefile': 'contents of nonamefile field',
|
||||||
|
}
|
||||||
|
|
||||||
|
When uploading a file, providing a filename (the first parameter of the
|
||||||
|
tuple) is optional but recommended to best mimic behavior of browsers.
|
||||||
|
|
||||||
|
Note that if ``headers`` are supplied, the 'Content-Type' header will
|
||||||
|
be overwritten because it depends on the dynamic random boundary string
|
||||||
|
which is used to compose the body of the request. The random boundary
|
||||||
|
string can be explicitly set with the ``multipart_boundary`` parameter.
|
||||||
|
|
||||||
|
:param method:
|
||||||
|
HTTP request method (such as GET, POST, PUT, etc.)
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
The URL to perform the request on.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Data to encode and send in the request body.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Dictionary of custom headers to send, such as User-Agent,
|
||||||
|
If-None-Match, etc. If None, pool headers are used. If provided,
|
||||||
|
these headers completely replace any pool-specific headers.
|
||||||
|
|
||||||
|
:param encode_multipart:
|
||||||
|
If True, encode the ``fields`` using the multipart/form-data MIME
|
||||||
|
format.
|
||||||
|
|
||||||
|
:param multipart_boundary:
|
||||||
|
If not specified, then a random boundary will be generated using
|
||||||
|
:func:`urllib3.filepost.choose_boundary`.
|
||||||
|
"""
|
||||||
|
if headers is None:
|
||||||
|
headers = self.headers
|
||||||
|
|
||||||
|
extra_kw: dict[str, typing.Any] = {"headers": HTTPHeaderDict(headers)}
|
||||||
|
body: bytes | str
|
||||||
|
|
||||||
|
if fields:
|
||||||
|
if "body" in urlopen_kw:
|
||||||
|
raise TypeError(
|
||||||
|
"request got values for both 'fields' and 'body', can only specify one."
|
||||||
|
)
|
||||||
|
|
||||||
|
if encode_multipart:
|
||||||
|
body, content_type = encode_multipart_formdata(
|
||||||
|
fields, boundary=multipart_boundary
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
body, content_type = (
|
||||||
|
urlencode(fields), # type: ignore[arg-type]
|
||||||
|
"application/x-www-form-urlencoded",
|
||||||
|
)
|
||||||
|
|
||||||
|
extra_kw["body"] = body
|
||||||
|
extra_kw["headers"].setdefault("Content-Type", content_type)
|
||||||
|
|
||||||
|
extra_kw.update(urlopen_kw)
|
||||||
|
|
||||||
|
return self.urlopen(method, url, **extra_kw)
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
# This file is protected via CODEOWNERS
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
__version__ = "2.2.0"
|
||||||
|
|
@ -0,0 +1,930 @@
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import datetime
|
||||||
|
import logging
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
import socket
|
||||||
|
import sys
|
||||||
|
import typing
|
||||||
|
import warnings
|
||||||
|
from http.client import HTTPConnection as _HTTPConnection
|
||||||
|
from http.client import HTTPException as HTTPException # noqa: F401
|
||||||
|
from http.client import ResponseNotReady
|
||||||
|
from socket import timeout as SocketTimeout
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from typing import Literal
|
||||||
|
|
||||||
|
from .response import HTTPResponse
|
||||||
|
from .util.ssl_ import _TYPE_PEER_CERT_RET_DICT
|
||||||
|
from .util.ssltransport import SSLTransport
|
||||||
|
|
||||||
|
from ._collections import HTTPHeaderDict
|
||||||
|
from .util.response import assert_header_parsing
|
||||||
|
from .util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT, Timeout
|
||||||
|
from .util.util import to_str
|
||||||
|
from .util.wait import wait_for_read
|
||||||
|
|
||||||
|
try: # Compiled with SSL?
|
||||||
|
import ssl
|
||||||
|
|
||||||
|
BaseSSLError = ssl.SSLError
|
||||||
|
except (ImportError, AttributeError):
|
||||||
|
ssl = None # type: ignore[assignment]
|
||||||
|
|
||||||
|
class BaseSSLError(BaseException): # type: ignore[no-redef]
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
from ._base_connection import _TYPE_BODY
|
||||||
|
from ._base_connection import ProxyConfig as ProxyConfig
|
||||||
|
from ._base_connection import _ResponseOptions as _ResponseOptions
|
||||||
|
from ._version import __version__
|
||||||
|
from .exceptions import (
|
||||||
|
ConnectTimeoutError,
|
||||||
|
HeaderParsingError,
|
||||||
|
NameResolutionError,
|
||||||
|
NewConnectionError,
|
||||||
|
ProxyError,
|
||||||
|
SystemTimeWarning,
|
||||||
|
)
|
||||||
|
from .util import SKIP_HEADER, SKIPPABLE_HEADERS, connection, ssl_
|
||||||
|
from .util.request import body_to_chunks
|
||||||
|
from .util.ssl_ import assert_fingerprint as _assert_fingerprint
|
||||||
|
from .util.ssl_ import (
|
||||||
|
create_urllib3_context,
|
||||||
|
is_ipaddress,
|
||||||
|
resolve_cert_reqs,
|
||||||
|
resolve_ssl_version,
|
||||||
|
ssl_wrap_socket,
|
||||||
|
)
|
||||||
|
from .util.ssl_match_hostname import CertificateError, match_hostname
|
||||||
|
from .util.url import Url
|
||||||
|
|
||||||
|
# Not a no-op, we're adding this to the namespace so it can be imported.
|
||||||
|
ConnectionError = ConnectionError
|
||||||
|
BrokenPipeError = BrokenPipeError
|
||||||
|
|
||||||
|
|
||||||
|
log = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
port_by_scheme = {"http": 80, "https": 443}
|
||||||
|
|
||||||
|
# When it comes time to update this value as a part of regular maintenance
|
||||||
|
# (ie test_recent_date is failing) update it to ~6 months before the current date.
|
||||||
|
RECENT_DATE = datetime.date(2023, 6, 1)
|
||||||
|
|
||||||
|
_CONTAINS_CONTROL_CHAR_RE = re.compile(r"[^-!#$%&'*+.^_`|~0-9a-zA-Z]")
|
||||||
|
|
||||||
|
_HAS_SYS_AUDIT = hasattr(sys, "audit")
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPConnection(_HTTPConnection):
|
||||||
|
"""
|
||||||
|
Based on :class:`http.client.HTTPConnection` but provides an extra constructor
|
||||||
|
backwards-compatibility layer between older and newer Pythons.
|
||||||
|
|
||||||
|
Additional keyword parameters are used to configure attributes of the connection.
|
||||||
|
Accepted parameters include:
|
||||||
|
|
||||||
|
- ``source_address``: Set the source address for the current connection.
|
||||||
|
- ``socket_options``: Set specific options on the underlying socket. If not specified, then
|
||||||
|
defaults are loaded from ``HTTPConnection.default_socket_options`` which includes disabling
|
||||||
|
Nagle's algorithm (sets TCP_NODELAY to 1) unless the connection is behind a proxy.
|
||||||
|
|
||||||
|
For example, if you wish to enable TCP Keep Alive in addition to the defaults,
|
||||||
|
you might pass:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
HTTPConnection.default_socket_options + [
|
||||||
|
(socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1),
|
||||||
|
]
|
||||||
|
|
||||||
|
Or you may want to disable the defaults by passing an empty list (e.g., ``[]``).
|
||||||
|
"""
|
||||||
|
|
||||||
|
default_port: typing.ClassVar[int] = port_by_scheme["http"] # type: ignore[misc]
|
||||||
|
|
||||||
|
#: Disable Nagle's algorithm by default.
|
||||||
|
#: ``[(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)]``
|
||||||
|
default_socket_options: typing.ClassVar[connection._TYPE_SOCKET_OPTIONS] = [
|
||||||
|
(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
|
||||||
|
]
|
||||||
|
|
||||||
|
#: Whether this connection verifies the host's certificate.
|
||||||
|
is_verified: bool = False
|
||||||
|
|
||||||
|
#: Whether this proxy connection verified the proxy host's certificate.
|
||||||
|
# If no proxy is currently connected to the value will be ``None``.
|
||||||
|
proxy_is_verified: bool | None = None
|
||||||
|
|
||||||
|
blocksize: int
|
||||||
|
source_address: tuple[str, int] | None
|
||||||
|
socket_options: connection._TYPE_SOCKET_OPTIONS | None
|
||||||
|
|
||||||
|
_has_connected_to_proxy: bool
|
||||||
|
_response_options: _ResponseOptions | None
|
||||||
|
_tunnel_host: str | None
|
||||||
|
_tunnel_port: int | None
|
||||||
|
_tunnel_scheme: str | None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 16384,
|
||||||
|
socket_options: None
|
||||||
|
| (connection._TYPE_SOCKET_OPTIONS) = default_socket_options,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
) -> None:
|
||||||
|
super().__init__(
|
||||||
|
host=host,
|
||||||
|
port=port,
|
||||||
|
timeout=Timeout.resolve_default_timeout(timeout),
|
||||||
|
source_address=source_address,
|
||||||
|
blocksize=blocksize,
|
||||||
|
)
|
||||||
|
self.socket_options = socket_options
|
||||||
|
self.proxy = proxy
|
||||||
|
self.proxy_config = proxy_config
|
||||||
|
|
||||||
|
self._has_connected_to_proxy = False
|
||||||
|
self._response_options = None
|
||||||
|
self._tunnel_host: str | None = None
|
||||||
|
self._tunnel_port: int | None = None
|
||||||
|
self._tunnel_scheme: str | None = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def host(self) -> str:
|
||||||
|
"""
|
||||||
|
Getter method to remove any trailing dots that indicate the hostname is an FQDN.
|
||||||
|
|
||||||
|
In general, SSL certificates don't include the trailing dot indicating a
|
||||||
|
fully-qualified domain name, and thus, they don't validate properly when
|
||||||
|
checked against a domain name that includes the dot. In addition, some
|
||||||
|
servers may not expect to receive the trailing dot when provided.
|
||||||
|
|
||||||
|
However, the hostname with trailing dot is critical to DNS resolution; doing a
|
||||||
|
lookup with the trailing dot will properly only resolve the appropriate FQDN,
|
||||||
|
whereas a lookup without a trailing dot will search the system's search domain
|
||||||
|
list. Thus, it's important to keep the original host around for use only in
|
||||||
|
those cases where it's appropriate (i.e., when doing DNS lookup to establish the
|
||||||
|
actual TCP connection across which we're going to send HTTP requests).
|
||||||
|
"""
|
||||||
|
return self._dns_host.rstrip(".")
|
||||||
|
|
||||||
|
@host.setter
|
||||||
|
def host(self, value: str) -> None:
|
||||||
|
"""
|
||||||
|
Setter for the `host` property.
|
||||||
|
|
||||||
|
We assume that only urllib3 uses the _dns_host attribute; httplib itself
|
||||||
|
only uses `host`, and it seems reasonable that other libraries follow suit.
|
||||||
|
"""
|
||||||
|
self._dns_host = value
|
||||||
|
|
||||||
|
def _new_conn(self) -> socket.socket:
|
||||||
|
"""Establish a socket connection and set nodelay settings on it.
|
||||||
|
|
||||||
|
:return: New socket connection.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
sock = connection.create_connection(
|
||||||
|
(self._dns_host, self.port),
|
||||||
|
self.timeout,
|
||||||
|
source_address=self.source_address,
|
||||||
|
socket_options=self.socket_options,
|
||||||
|
)
|
||||||
|
except socket.gaierror as e:
|
||||||
|
raise NameResolutionError(self.host, self, e) from e
|
||||||
|
except SocketTimeout as e:
|
||||||
|
raise ConnectTimeoutError(
|
||||||
|
self,
|
||||||
|
f"Connection to {self.host} timed out. (connect timeout={self.timeout})",
|
||||||
|
) from e
|
||||||
|
|
||||||
|
except OSError as e:
|
||||||
|
raise NewConnectionError(
|
||||||
|
self, f"Failed to establish a new connection: {e}"
|
||||||
|
) from e
|
||||||
|
|
||||||
|
# Audit hooks are only available in Python 3.8+
|
||||||
|
if _HAS_SYS_AUDIT:
|
||||||
|
sys.audit("http.client.connect", self, self.host, self.port)
|
||||||
|
|
||||||
|
return sock
|
||||||
|
|
||||||
|
def set_tunnel(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
scheme: str = "http",
|
||||||
|
) -> None:
|
||||||
|
if scheme not in ("http", "https"):
|
||||||
|
raise ValueError(
|
||||||
|
f"Invalid proxy scheme for tunneling: {scheme!r}, must be either 'http' or 'https'"
|
||||||
|
)
|
||||||
|
super().set_tunnel(host, port=port, headers=headers)
|
||||||
|
self._tunnel_scheme = scheme
|
||||||
|
|
||||||
|
def connect(self) -> None:
|
||||||
|
self.sock = self._new_conn()
|
||||||
|
if self._tunnel_host:
|
||||||
|
# If we're tunneling it means we're connected to our proxy.
|
||||||
|
self._has_connected_to_proxy = True
|
||||||
|
|
||||||
|
# TODO: Fix tunnel so it doesn't depend on self.sock state.
|
||||||
|
self._tunnel() # type: ignore[attr-defined]
|
||||||
|
|
||||||
|
# If there's a proxy to be connected to we are fully connected.
|
||||||
|
# This is set twice (once above and here) due to forwarding proxies
|
||||||
|
# not using tunnelling.
|
||||||
|
self._has_connected_to_proxy = bool(self.proxy)
|
||||||
|
|
||||||
|
if self._has_connected_to_proxy:
|
||||||
|
self.proxy_is_verified = False
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_closed(self) -> bool:
|
||||||
|
return self.sock is None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_connected(self) -> bool:
|
||||||
|
if self.sock is None:
|
||||||
|
return False
|
||||||
|
return not wait_for_read(self.sock, timeout=0.0)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def has_connected_to_proxy(self) -> bool:
|
||||||
|
return self._has_connected_to_proxy
|
||||||
|
|
||||||
|
@property
|
||||||
|
def proxy_is_forwarding(self) -> bool:
|
||||||
|
"""
|
||||||
|
Return True if a forwarding proxy is configured, else return False
|
||||||
|
"""
|
||||||
|
return bool(self.proxy) and self._tunnel_host is None
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
try:
|
||||||
|
super().close()
|
||||||
|
finally:
|
||||||
|
# Reset all stateful properties so connection
|
||||||
|
# can be re-used without leaking prior configs.
|
||||||
|
self.sock = None
|
||||||
|
self.is_verified = False
|
||||||
|
self.proxy_is_verified = None
|
||||||
|
self._has_connected_to_proxy = False
|
||||||
|
self._response_options = None
|
||||||
|
self._tunnel_host = None
|
||||||
|
self._tunnel_port = None
|
||||||
|
self._tunnel_scheme = None
|
||||||
|
|
||||||
|
def putrequest(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
skip_host: bool = False,
|
||||||
|
skip_accept_encoding: bool = False,
|
||||||
|
) -> None:
|
||||||
|
""""""
|
||||||
|
# Empty docstring because the indentation of CPython's implementation
|
||||||
|
# is broken but we don't want this method in our documentation.
|
||||||
|
match = _CONTAINS_CONTROL_CHAR_RE.search(method)
|
||||||
|
if match:
|
||||||
|
raise ValueError(
|
||||||
|
f"Method cannot contain non-token characters {method!r} (found at least {match.group()!r})"
|
||||||
|
)
|
||||||
|
|
||||||
|
return super().putrequest(
|
||||||
|
method, url, skip_host=skip_host, skip_accept_encoding=skip_accept_encoding
|
||||||
|
)
|
||||||
|
|
||||||
|
def putheader(self, header: str, *values: str) -> None:
|
||||||
|
""""""
|
||||||
|
if not any(isinstance(v, str) and v == SKIP_HEADER for v in values):
|
||||||
|
super().putheader(header, *values)
|
||||||
|
elif to_str(header.lower()) not in SKIPPABLE_HEADERS:
|
||||||
|
skippable_headers = "', '".join(
|
||||||
|
[str.title(header) for header in sorted(SKIPPABLE_HEADERS)]
|
||||||
|
)
|
||||||
|
raise ValueError(
|
||||||
|
f"urllib3.util.SKIP_HEADER only supports '{skippable_headers}'"
|
||||||
|
)
|
||||||
|
|
||||||
|
# `request` method's signature intentionally violates LSP.
|
||||||
|
# urllib3's API is different from `http.client.HTTPConnection` and the subclassing is only incidental.
|
||||||
|
def request( # type: ignore[override]
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
*,
|
||||||
|
chunked: bool = False,
|
||||||
|
preload_content: bool = True,
|
||||||
|
decode_content: bool = True,
|
||||||
|
enforce_content_length: bool = True,
|
||||||
|
) -> None:
|
||||||
|
# Update the inner socket's timeout value to send the request.
|
||||||
|
# This only triggers if the connection is re-used.
|
||||||
|
if self.sock is not None:
|
||||||
|
self.sock.settimeout(self.timeout)
|
||||||
|
|
||||||
|
# Store these values to be fed into the HTTPResponse
|
||||||
|
# object later. TODO: Remove this in favor of a real
|
||||||
|
# HTTP lifecycle mechanism.
|
||||||
|
|
||||||
|
# We have to store these before we call .request()
|
||||||
|
# because sometimes we can still salvage a response
|
||||||
|
# off the wire even if we aren't able to completely
|
||||||
|
# send the request body.
|
||||||
|
self._response_options = _ResponseOptions(
|
||||||
|
request_method=method,
|
||||||
|
request_url=url,
|
||||||
|
preload_content=preload_content,
|
||||||
|
decode_content=decode_content,
|
||||||
|
enforce_content_length=enforce_content_length,
|
||||||
|
)
|
||||||
|
|
||||||
|
if headers is None:
|
||||||
|
headers = {}
|
||||||
|
header_keys = frozenset(to_str(k.lower()) for k in headers)
|
||||||
|
skip_accept_encoding = "accept-encoding" in header_keys
|
||||||
|
skip_host = "host" in header_keys
|
||||||
|
self.putrequest(
|
||||||
|
method, url, skip_accept_encoding=skip_accept_encoding, skip_host=skip_host
|
||||||
|
)
|
||||||
|
|
||||||
|
# Transform the body into an iterable of sendall()-able chunks
|
||||||
|
# and detect if an explicit Content-Length is doable.
|
||||||
|
chunks_and_cl = body_to_chunks(body, method=method, blocksize=self.blocksize)
|
||||||
|
chunks = chunks_and_cl.chunks
|
||||||
|
content_length = chunks_and_cl.content_length
|
||||||
|
|
||||||
|
# When chunked is explicit set to 'True' we respect that.
|
||||||
|
if chunked:
|
||||||
|
if "transfer-encoding" not in header_keys:
|
||||||
|
self.putheader("Transfer-Encoding", "chunked")
|
||||||
|
else:
|
||||||
|
# Detect whether a framing mechanism is already in use. If so
|
||||||
|
# we respect that value, otherwise we pick chunked vs content-length
|
||||||
|
# depending on the type of 'body'.
|
||||||
|
if "content-length" in header_keys:
|
||||||
|
chunked = False
|
||||||
|
elif "transfer-encoding" in header_keys:
|
||||||
|
chunked = True
|
||||||
|
|
||||||
|
# Otherwise we go off the recommendation of 'body_to_chunks()'.
|
||||||
|
else:
|
||||||
|
chunked = False
|
||||||
|
if content_length is None:
|
||||||
|
if chunks is not None:
|
||||||
|
chunked = True
|
||||||
|
self.putheader("Transfer-Encoding", "chunked")
|
||||||
|
else:
|
||||||
|
self.putheader("Content-Length", str(content_length))
|
||||||
|
|
||||||
|
# Now that framing headers are out of the way we send all the other headers.
|
||||||
|
if "user-agent" not in header_keys:
|
||||||
|
self.putheader("User-Agent", _get_default_user_agent())
|
||||||
|
for header, value in headers.items():
|
||||||
|
self.putheader(header, value)
|
||||||
|
self.endheaders()
|
||||||
|
|
||||||
|
# If we're given a body we start sending that in chunks.
|
||||||
|
if chunks is not None:
|
||||||
|
for chunk in chunks:
|
||||||
|
# Sending empty chunks isn't allowed for TE: chunked
|
||||||
|
# as it indicates the end of the body.
|
||||||
|
if not chunk:
|
||||||
|
continue
|
||||||
|
if isinstance(chunk, str):
|
||||||
|
chunk = chunk.encode("utf-8")
|
||||||
|
if chunked:
|
||||||
|
self.send(b"%x\r\n%b\r\n" % (len(chunk), chunk))
|
||||||
|
else:
|
||||||
|
self.send(chunk)
|
||||||
|
|
||||||
|
# Regardless of whether we have a body or not, if we're in
|
||||||
|
# chunked mode we want to send an explicit empty chunk.
|
||||||
|
if chunked:
|
||||||
|
self.send(b"0\r\n\r\n")
|
||||||
|
|
||||||
|
def request_chunked(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
) -> None:
|
||||||
|
"""
|
||||||
|
Alternative to the common request method, which sends the
|
||||||
|
body with chunked encoding and not as one block
|
||||||
|
"""
|
||||||
|
warnings.warn(
|
||||||
|
"HTTPConnection.request_chunked() is deprecated and will be removed "
|
||||||
|
"in urllib3 v2.1.0. Instead use HTTPConnection.request(..., chunked=True).",
|
||||||
|
category=DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
self.request(method, url, body=body, headers=headers, chunked=True)
|
||||||
|
|
||||||
|
def getresponse( # type: ignore[override]
|
||||||
|
self,
|
||||||
|
) -> HTTPResponse:
|
||||||
|
"""
|
||||||
|
Get the response from the server.
|
||||||
|
|
||||||
|
If the HTTPConnection is in the correct state, returns an instance of HTTPResponse or of whatever object is returned by the response_class variable.
|
||||||
|
|
||||||
|
If a request has not been sent or if a previous response has not be handled, ResponseNotReady is raised. If the HTTP response indicates that the connection should be closed, then it will be closed before the response is returned. When the connection is closed, the underlying socket is closed.
|
||||||
|
"""
|
||||||
|
# Raise the same error as http.client.HTTPConnection
|
||||||
|
if self._response_options is None:
|
||||||
|
raise ResponseNotReady()
|
||||||
|
|
||||||
|
# Reset this attribute for being used again.
|
||||||
|
resp_options = self._response_options
|
||||||
|
self._response_options = None
|
||||||
|
|
||||||
|
# Since the connection's timeout value may have been updated
|
||||||
|
# we need to set the timeout on the socket.
|
||||||
|
self.sock.settimeout(self.timeout)
|
||||||
|
|
||||||
|
# This is needed here to avoid circular import errors
|
||||||
|
from .response import HTTPResponse
|
||||||
|
|
||||||
|
# Get the response from http.client.HTTPConnection
|
||||||
|
httplib_response = super().getresponse()
|
||||||
|
|
||||||
|
try:
|
||||||
|
assert_header_parsing(httplib_response.msg)
|
||||||
|
except (HeaderParsingError, TypeError) as hpe:
|
||||||
|
log.warning(
|
||||||
|
"Failed to parse headers (url=%s): %s",
|
||||||
|
_url_from_connection(self, resp_options.request_url),
|
||||||
|
hpe,
|
||||||
|
exc_info=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
headers = HTTPHeaderDict(httplib_response.msg.items())
|
||||||
|
|
||||||
|
response = HTTPResponse(
|
||||||
|
body=httplib_response,
|
||||||
|
headers=headers,
|
||||||
|
status=httplib_response.status,
|
||||||
|
version=httplib_response.version,
|
||||||
|
reason=httplib_response.reason,
|
||||||
|
preload_content=resp_options.preload_content,
|
||||||
|
decode_content=resp_options.decode_content,
|
||||||
|
original_response=httplib_response,
|
||||||
|
enforce_content_length=resp_options.enforce_content_length,
|
||||||
|
request_method=resp_options.request_method,
|
||||||
|
request_url=resp_options.request_url,
|
||||||
|
)
|
||||||
|
return response
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPSConnection(HTTPConnection):
|
||||||
|
"""
|
||||||
|
Many of the parameters to this constructor are passed to the underlying SSL
|
||||||
|
socket by means of :py:func:`urllib3.util.ssl_wrap_socket`.
|
||||||
|
"""
|
||||||
|
|
||||||
|
default_port = port_by_scheme["https"] # type: ignore[misc]
|
||||||
|
|
||||||
|
cert_reqs: int | str | None = None
|
||||||
|
ca_certs: str | None = None
|
||||||
|
ca_cert_dir: str | None = None
|
||||||
|
ca_cert_data: None | str | bytes = None
|
||||||
|
ssl_version: int | str | None = None
|
||||||
|
ssl_minimum_version: int | None = None
|
||||||
|
ssl_maximum_version: int | None = None
|
||||||
|
assert_fingerprint: str | None = None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 16384,
|
||||||
|
socket_options: None
|
||||||
|
| (connection._TYPE_SOCKET_OPTIONS) = HTTPConnection.default_socket_options,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
cert_reqs: int | str | None = None,
|
||||||
|
assert_hostname: None | str | Literal[False] = None,
|
||||||
|
assert_fingerprint: str | None = None,
|
||||||
|
server_hostname: str | None = None,
|
||||||
|
ssl_context: ssl.SSLContext | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
ssl_minimum_version: int | None = None,
|
||||||
|
ssl_maximum_version: int | None = None,
|
||||||
|
ssl_version: int | str | None = None, # Deprecated
|
||||||
|
cert_file: str | None = None,
|
||||||
|
key_file: str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
) -> None:
|
||||||
|
super().__init__(
|
||||||
|
host,
|
||||||
|
port=port,
|
||||||
|
timeout=timeout,
|
||||||
|
source_address=source_address,
|
||||||
|
blocksize=blocksize,
|
||||||
|
socket_options=socket_options,
|
||||||
|
proxy=proxy,
|
||||||
|
proxy_config=proxy_config,
|
||||||
|
)
|
||||||
|
|
||||||
|
self.key_file = key_file
|
||||||
|
self.cert_file = cert_file
|
||||||
|
self.key_password = key_password
|
||||||
|
self.ssl_context = ssl_context
|
||||||
|
self.server_hostname = server_hostname
|
||||||
|
self.assert_hostname = assert_hostname
|
||||||
|
self.assert_fingerprint = assert_fingerprint
|
||||||
|
self.ssl_version = ssl_version
|
||||||
|
self.ssl_minimum_version = ssl_minimum_version
|
||||||
|
self.ssl_maximum_version = ssl_maximum_version
|
||||||
|
self.ca_certs = ca_certs and os.path.expanduser(ca_certs)
|
||||||
|
self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)
|
||||||
|
self.ca_cert_data = ca_cert_data
|
||||||
|
|
||||||
|
# cert_reqs depends on ssl_context so calculate last.
|
||||||
|
if cert_reqs is None:
|
||||||
|
if self.ssl_context is not None:
|
||||||
|
cert_reqs = self.ssl_context.verify_mode
|
||||||
|
else:
|
||||||
|
cert_reqs = resolve_cert_reqs(None)
|
||||||
|
self.cert_reqs = cert_reqs
|
||||||
|
|
||||||
|
def set_cert(
|
||||||
|
self,
|
||||||
|
key_file: str | None = None,
|
||||||
|
cert_file: str | None = None,
|
||||||
|
cert_reqs: int | str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
assert_hostname: None | str | Literal[False] = None,
|
||||||
|
assert_fingerprint: str | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
) -> None:
|
||||||
|
"""
|
||||||
|
This method should only be called once, before the connection is used.
|
||||||
|
"""
|
||||||
|
warnings.warn(
|
||||||
|
"HTTPSConnection.set_cert() is deprecated and will be removed "
|
||||||
|
"in urllib3 v2.1.0. Instead provide the parameters to the "
|
||||||
|
"HTTPSConnection constructor.",
|
||||||
|
category=DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
|
||||||
|
# If cert_reqs is not provided we'll assume CERT_REQUIRED unless we also
|
||||||
|
# have an SSLContext object in which case we'll use its verify_mode.
|
||||||
|
if cert_reqs is None:
|
||||||
|
if self.ssl_context is not None:
|
||||||
|
cert_reqs = self.ssl_context.verify_mode
|
||||||
|
else:
|
||||||
|
cert_reqs = resolve_cert_reqs(None)
|
||||||
|
|
||||||
|
self.key_file = key_file
|
||||||
|
self.cert_file = cert_file
|
||||||
|
self.cert_reqs = cert_reqs
|
||||||
|
self.key_password = key_password
|
||||||
|
self.assert_hostname = assert_hostname
|
||||||
|
self.assert_fingerprint = assert_fingerprint
|
||||||
|
self.ca_certs = ca_certs and os.path.expanduser(ca_certs)
|
||||||
|
self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)
|
||||||
|
self.ca_cert_data = ca_cert_data
|
||||||
|
|
||||||
|
def connect(self) -> None:
|
||||||
|
sock: socket.socket | ssl.SSLSocket
|
||||||
|
self.sock = sock = self._new_conn()
|
||||||
|
server_hostname: str = self.host
|
||||||
|
tls_in_tls = False
|
||||||
|
|
||||||
|
# Do we need to establish a tunnel?
|
||||||
|
if self._tunnel_host is not None:
|
||||||
|
# We're tunneling to an HTTPS origin so need to do TLS-in-TLS.
|
||||||
|
if self._tunnel_scheme == "https":
|
||||||
|
# _connect_tls_proxy will verify and assign proxy_is_verified
|
||||||
|
self.sock = sock = self._connect_tls_proxy(self.host, sock)
|
||||||
|
tls_in_tls = True
|
||||||
|
elif self._tunnel_scheme == "http":
|
||||||
|
self.proxy_is_verified = False
|
||||||
|
|
||||||
|
# If we're tunneling it means we're connected to our proxy.
|
||||||
|
self._has_connected_to_proxy = True
|
||||||
|
|
||||||
|
self._tunnel() # type: ignore[attr-defined]
|
||||||
|
# Override the host with the one we're requesting data from.
|
||||||
|
server_hostname = self._tunnel_host
|
||||||
|
|
||||||
|
if self.server_hostname is not None:
|
||||||
|
server_hostname = self.server_hostname
|
||||||
|
|
||||||
|
is_time_off = datetime.date.today() < RECENT_DATE
|
||||||
|
if is_time_off:
|
||||||
|
warnings.warn(
|
||||||
|
(
|
||||||
|
f"System time is way off (before {RECENT_DATE}). This will probably "
|
||||||
|
"lead to SSL verification errors"
|
||||||
|
),
|
||||||
|
SystemTimeWarning,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Remove trailing '.' from fqdn hostnames to allow certificate validation
|
||||||
|
server_hostname_rm_dot = server_hostname.rstrip(".")
|
||||||
|
|
||||||
|
sock_and_verified = _ssl_wrap_socket_and_match_hostname(
|
||||||
|
sock=sock,
|
||||||
|
cert_reqs=self.cert_reqs,
|
||||||
|
ssl_version=self.ssl_version,
|
||||||
|
ssl_minimum_version=self.ssl_minimum_version,
|
||||||
|
ssl_maximum_version=self.ssl_maximum_version,
|
||||||
|
ca_certs=self.ca_certs,
|
||||||
|
ca_cert_dir=self.ca_cert_dir,
|
||||||
|
ca_cert_data=self.ca_cert_data,
|
||||||
|
cert_file=self.cert_file,
|
||||||
|
key_file=self.key_file,
|
||||||
|
key_password=self.key_password,
|
||||||
|
server_hostname=server_hostname_rm_dot,
|
||||||
|
ssl_context=self.ssl_context,
|
||||||
|
tls_in_tls=tls_in_tls,
|
||||||
|
assert_hostname=self.assert_hostname,
|
||||||
|
assert_fingerprint=self.assert_fingerprint,
|
||||||
|
)
|
||||||
|
self.sock = sock_and_verified.socket
|
||||||
|
|
||||||
|
# Forwarding proxies can never have a verified target since
|
||||||
|
# the proxy is the one doing the verification. Should instead
|
||||||
|
# use a CONNECT tunnel in order to verify the target.
|
||||||
|
# See: https://github.com/urllib3/urllib3/issues/3267.
|
||||||
|
if self.proxy_is_forwarding:
|
||||||
|
self.is_verified = False
|
||||||
|
else:
|
||||||
|
self.is_verified = sock_and_verified.is_verified
|
||||||
|
|
||||||
|
# If there's a proxy to be connected to we are fully connected.
|
||||||
|
# This is set twice (once above and here) due to forwarding proxies
|
||||||
|
# not using tunnelling.
|
||||||
|
self._has_connected_to_proxy = bool(self.proxy)
|
||||||
|
|
||||||
|
# Set `self.proxy_is_verified` unless it's already set while
|
||||||
|
# establishing a tunnel.
|
||||||
|
if self._has_connected_to_proxy and self.proxy_is_verified is None:
|
||||||
|
self.proxy_is_verified = sock_and_verified.is_verified
|
||||||
|
|
||||||
|
def _connect_tls_proxy(self, hostname: str, sock: socket.socket) -> ssl.SSLSocket:
|
||||||
|
"""
|
||||||
|
Establish a TLS connection to the proxy using the provided SSL context.
|
||||||
|
"""
|
||||||
|
# `_connect_tls_proxy` is called when self._tunnel_host is truthy.
|
||||||
|
proxy_config = typing.cast(ProxyConfig, self.proxy_config)
|
||||||
|
ssl_context = proxy_config.ssl_context
|
||||||
|
sock_and_verified = _ssl_wrap_socket_and_match_hostname(
|
||||||
|
sock,
|
||||||
|
cert_reqs=self.cert_reqs,
|
||||||
|
ssl_version=self.ssl_version,
|
||||||
|
ssl_minimum_version=self.ssl_minimum_version,
|
||||||
|
ssl_maximum_version=self.ssl_maximum_version,
|
||||||
|
ca_certs=self.ca_certs,
|
||||||
|
ca_cert_dir=self.ca_cert_dir,
|
||||||
|
ca_cert_data=self.ca_cert_data,
|
||||||
|
server_hostname=hostname,
|
||||||
|
ssl_context=ssl_context,
|
||||||
|
assert_hostname=proxy_config.assert_hostname,
|
||||||
|
assert_fingerprint=proxy_config.assert_fingerprint,
|
||||||
|
# Features that aren't implemented for proxies yet:
|
||||||
|
cert_file=None,
|
||||||
|
key_file=None,
|
||||||
|
key_password=None,
|
||||||
|
tls_in_tls=False,
|
||||||
|
)
|
||||||
|
self.proxy_is_verified = sock_and_verified.is_verified
|
||||||
|
return sock_and_verified.socket # type: ignore[return-value]
|
||||||
|
|
||||||
|
|
||||||
|
class _WrappedAndVerifiedSocket(typing.NamedTuple):
|
||||||
|
"""
|
||||||
|
Wrapped socket and whether the connection is
|
||||||
|
verified after the TLS handshake
|
||||||
|
"""
|
||||||
|
|
||||||
|
socket: ssl.SSLSocket | SSLTransport
|
||||||
|
is_verified: bool
|
||||||
|
|
||||||
|
|
||||||
|
def _ssl_wrap_socket_and_match_hostname(
|
||||||
|
sock: socket.socket,
|
||||||
|
*,
|
||||||
|
cert_reqs: None | str | int,
|
||||||
|
ssl_version: None | str | int,
|
||||||
|
ssl_minimum_version: int | None,
|
||||||
|
ssl_maximum_version: int | None,
|
||||||
|
cert_file: str | None,
|
||||||
|
key_file: str | None,
|
||||||
|
key_password: str | None,
|
||||||
|
ca_certs: str | None,
|
||||||
|
ca_cert_dir: str | None,
|
||||||
|
ca_cert_data: None | str | bytes,
|
||||||
|
assert_hostname: None | str | Literal[False],
|
||||||
|
assert_fingerprint: str | None,
|
||||||
|
server_hostname: str | None,
|
||||||
|
ssl_context: ssl.SSLContext | None,
|
||||||
|
tls_in_tls: bool = False,
|
||||||
|
) -> _WrappedAndVerifiedSocket:
|
||||||
|
"""Logic for constructing an SSLContext from all TLS parameters, passing
|
||||||
|
that down into ssl_wrap_socket, and then doing certificate verification
|
||||||
|
either via hostname or fingerprint. This function exists to guarantee
|
||||||
|
that both proxies and targets have the same behavior when connecting via TLS.
|
||||||
|
"""
|
||||||
|
default_ssl_context = False
|
||||||
|
if ssl_context is None:
|
||||||
|
default_ssl_context = True
|
||||||
|
context = create_urllib3_context(
|
||||||
|
ssl_version=resolve_ssl_version(ssl_version),
|
||||||
|
ssl_minimum_version=ssl_minimum_version,
|
||||||
|
ssl_maximum_version=ssl_maximum_version,
|
||||||
|
cert_reqs=resolve_cert_reqs(cert_reqs),
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
context = ssl_context
|
||||||
|
|
||||||
|
context.verify_mode = resolve_cert_reqs(cert_reqs)
|
||||||
|
|
||||||
|
# In some cases, we want to verify hostnames ourselves
|
||||||
|
if (
|
||||||
|
# `ssl` can't verify fingerprints or alternate hostnames
|
||||||
|
assert_fingerprint
|
||||||
|
or assert_hostname
|
||||||
|
# assert_hostname can be set to False to disable hostname checking
|
||||||
|
or assert_hostname is False
|
||||||
|
# We still support OpenSSL 1.0.2, which prevents us from verifying
|
||||||
|
# hostnames easily: https://github.com/pyca/pyopenssl/pull/933
|
||||||
|
or ssl_.IS_PYOPENSSL
|
||||||
|
or not ssl_.HAS_NEVER_CHECK_COMMON_NAME
|
||||||
|
):
|
||||||
|
context.check_hostname = False
|
||||||
|
|
||||||
|
# Try to load OS default certs if none are given. We need to do the hasattr() check
|
||||||
|
# for custom pyOpenSSL SSLContext objects because they don't support
|
||||||
|
# load_default_certs().
|
||||||
|
if (
|
||||||
|
not ca_certs
|
||||||
|
and not ca_cert_dir
|
||||||
|
and not ca_cert_data
|
||||||
|
and default_ssl_context
|
||||||
|
and hasattr(context, "load_default_certs")
|
||||||
|
):
|
||||||
|
context.load_default_certs()
|
||||||
|
|
||||||
|
# Ensure that IPv6 addresses are in the proper format and don't have a
|
||||||
|
# scope ID. Python's SSL module fails to recognize scoped IPv6 addresses
|
||||||
|
# and interprets them as DNS hostnames.
|
||||||
|
if server_hostname is not None:
|
||||||
|
normalized = server_hostname.strip("[]")
|
||||||
|
if "%" in normalized:
|
||||||
|
normalized = normalized[: normalized.rfind("%")]
|
||||||
|
if is_ipaddress(normalized):
|
||||||
|
server_hostname = normalized
|
||||||
|
|
||||||
|
ssl_sock = ssl_wrap_socket(
|
||||||
|
sock=sock,
|
||||||
|
keyfile=key_file,
|
||||||
|
certfile=cert_file,
|
||||||
|
key_password=key_password,
|
||||||
|
ca_certs=ca_certs,
|
||||||
|
ca_cert_dir=ca_cert_dir,
|
||||||
|
ca_cert_data=ca_cert_data,
|
||||||
|
server_hostname=server_hostname,
|
||||||
|
ssl_context=context,
|
||||||
|
tls_in_tls=tls_in_tls,
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
if assert_fingerprint:
|
||||||
|
_assert_fingerprint(
|
||||||
|
ssl_sock.getpeercert(binary_form=True), assert_fingerprint
|
||||||
|
)
|
||||||
|
elif (
|
||||||
|
context.verify_mode != ssl.CERT_NONE
|
||||||
|
and not context.check_hostname
|
||||||
|
and assert_hostname is not False
|
||||||
|
):
|
||||||
|
cert: _TYPE_PEER_CERT_RET_DICT = ssl_sock.getpeercert() # type: ignore[assignment]
|
||||||
|
|
||||||
|
# Need to signal to our match_hostname whether to use 'commonName' or not.
|
||||||
|
# If we're using our own constructed SSLContext we explicitly set 'False'
|
||||||
|
# because PyPy hard-codes 'True' from SSLContext.hostname_checks_common_name.
|
||||||
|
if default_ssl_context:
|
||||||
|
hostname_checks_common_name = False
|
||||||
|
else:
|
||||||
|
hostname_checks_common_name = (
|
||||||
|
getattr(context, "hostname_checks_common_name", False) or False
|
||||||
|
)
|
||||||
|
|
||||||
|
_match_hostname(
|
||||||
|
cert,
|
||||||
|
assert_hostname or server_hostname, # type: ignore[arg-type]
|
||||||
|
hostname_checks_common_name,
|
||||||
|
)
|
||||||
|
|
||||||
|
return _WrappedAndVerifiedSocket(
|
||||||
|
socket=ssl_sock,
|
||||||
|
is_verified=context.verify_mode == ssl.CERT_REQUIRED
|
||||||
|
or bool(assert_fingerprint),
|
||||||
|
)
|
||||||
|
except BaseException:
|
||||||
|
ssl_sock.close()
|
||||||
|
raise
|
||||||
|
|
||||||
|
|
||||||
|
def _match_hostname(
|
||||||
|
cert: _TYPE_PEER_CERT_RET_DICT | None,
|
||||||
|
asserted_hostname: str,
|
||||||
|
hostname_checks_common_name: bool = False,
|
||||||
|
) -> None:
|
||||||
|
# Our upstream implementation of ssl.match_hostname()
|
||||||
|
# only applies this normalization to IP addresses so it doesn't
|
||||||
|
# match DNS SANs so we do the same thing!
|
||||||
|
stripped_hostname = asserted_hostname.strip("[]")
|
||||||
|
if is_ipaddress(stripped_hostname):
|
||||||
|
asserted_hostname = stripped_hostname
|
||||||
|
|
||||||
|
try:
|
||||||
|
match_hostname(cert, asserted_hostname, hostname_checks_common_name)
|
||||||
|
except CertificateError as e:
|
||||||
|
log.warning(
|
||||||
|
"Certificate did not match expected hostname: %s. Certificate: %s",
|
||||||
|
asserted_hostname,
|
||||||
|
cert,
|
||||||
|
)
|
||||||
|
# Add cert to exception and reraise so client code can inspect
|
||||||
|
# the cert when catching the exception, if they want to
|
||||||
|
e._peer_cert = cert # type: ignore[attr-defined]
|
||||||
|
raise
|
||||||
|
|
||||||
|
|
||||||
|
def _wrap_proxy_error(err: Exception, proxy_scheme: str | None) -> ProxyError:
|
||||||
|
# Look for the phrase 'wrong version number', if found
|
||||||
|
# then we should warn the user that we're very sure that
|
||||||
|
# this proxy is HTTP-only and they have a configuration issue.
|
||||||
|
error_normalized = " ".join(re.split("[^a-z]", str(err).lower()))
|
||||||
|
is_likely_http_proxy = (
|
||||||
|
"wrong version number" in error_normalized
|
||||||
|
or "unknown protocol" in error_normalized
|
||||||
|
or "record layer failure" in error_normalized
|
||||||
|
)
|
||||||
|
http_proxy_warning = (
|
||||||
|
". Your proxy appears to only use HTTP and not HTTPS, "
|
||||||
|
"try changing your proxy URL to be HTTP. See: "
|
||||||
|
"https://urllib3.readthedocs.io/en/latest/advanced-usage.html"
|
||||||
|
"#https-proxy-error-http-proxy"
|
||||||
|
)
|
||||||
|
new_err = ProxyError(
|
||||||
|
f"Unable to connect to proxy"
|
||||||
|
f"{http_proxy_warning if is_likely_http_proxy and proxy_scheme == 'https' else ''}",
|
||||||
|
err,
|
||||||
|
)
|
||||||
|
new_err.__cause__ = err
|
||||||
|
return new_err
|
||||||
|
|
||||||
|
|
||||||
|
def _get_default_user_agent() -> str:
|
||||||
|
return f"python-urllib3/{__version__}"
|
||||||
|
|
||||||
|
|
||||||
|
class DummyConnection:
|
||||||
|
"""Used to detect a failed ConnectionCls import."""
|
||||||
|
|
||||||
|
|
||||||
|
if not ssl:
|
||||||
|
HTTPSConnection = DummyConnection # type: ignore[misc, assignment] # noqa: F811
|
||||||
|
|
||||||
|
|
||||||
|
VerifiedHTTPSConnection = HTTPSConnection
|
||||||
|
|
||||||
|
|
||||||
|
def _url_from_connection(
|
||||||
|
conn: HTTPConnection | HTTPSConnection, path: str | None = None
|
||||||
|
) -> str:
|
||||||
|
"""Returns the URL from a given connection. This is mainly used for testing and logging."""
|
||||||
|
|
||||||
|
scheme = "https" if isinstance(conn, HTTPSConnection) else "http"
|
||||||
|
|
||||||
|
return Url(scheme=scheme, host=conn.host, port=conn.port, path=path).url
|
||||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,16 @@
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import urllib3.connection
|
||||||
|
|
||||||
|
from ...connectionpool import HTTPConnectionPool, HTTPSConnectionPool
|
||||||
|
from .connection import EmscriptenHTTPConnection, EmscriptenHTTPSConnection
|
||||||
|
|
||||||
|
|
||||||
|
def inject_into_urllib3() -> None:
|
||||||
|
# override connection classes to use emscripten specific classes
|
||||||
|
# n.b. mypy complains about the overriding of classes below
|
||||||
|
# if it isn't ignored
|
||||||
|
HTTPConnectionPool.ConnectionCls = EmscriptenHTTPConnection
|
||||||
|
HTTPSConnectionPool.ConnectionCls = EmscriptenHTTPSConnection
|
||||||
|
urllib3.connection.HTTPConnection = EmscriptenHTTPConnection # type: ignore[misc,assignment]
|
||||||
|
urllib3.connection.HTTPSConnection = EmscriptenHTTPSConnection # type: ignore[misc,assignment]
|
||||||
|
|
@ -0,0 +1,249 @@
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import os
|
||||||
|
import typing
|
||||||
|
|
||||||
|
# use http.client.HTTPException for consistency with non-emscripten
|
||||||
|
from http.client import HTTPException as HTTPException # noqa: F401
|
||||||
|
from http.client import ResponseNotReady
|
||||||
|
|
||||||
|
from ..._base_connection import _TYPE_BODY
|
||||||
|
from ...connection import HTTPConnection, ProxyConfig, port_by_scheme
|
||||||
|
from ...exceptions import TimeoutError
|
||||||
|
from ...response import BaseHTTPResponse
|
||||||
|
from ...util.connection import _TYPE_SOCKET_OPTIONS
|
||||||
|
from ...util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT
|
||||||
|
from ...util.url import Url
|
||||||
|
from .fetch import _RequestError, _TimeoutError, send_request, send_streaming_request
|
||||||
|
from .request import EmscriptenRequest
|
||||||
|
from .response import EmscriptenHttpResponseWrapper, EmscriptenResponse
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from ..._base_connection import BaseHTTPConnection, BaseHTTPSConnection
|
||||||
|
|
||||||
|
|
||||||
|
class EmscriptenHTTPConnection:
|
||||||
|
default_port: typing.ClassVar[int] = port_by_scheme["http"]
|
||||||
|
default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]
|
||||||
|
|
||||||
|
timeout: None | (float)
|
||||||
|
|
||||||
|
host: str
|
||||||
|
port: int
|
||||||
|
blocksize: int
|
||||||
|
source_address: tuple[str, int] | None
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None
|
||||||
|
|
||||||
|
proxy: Url | None
|
||||||
|
proxy_config: ProxyConfig | None
|
||||||
|
|
||||||
|
is_verified: bool = False
|
||||||
|
proxy_is_verified: bool | None = None
|
||||||
|
|
||||||
|
_response: EmscriptenResponse | None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int = 0,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 8192,
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None = None,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
) -> None:
|
||||||
|
self.host = host
|
||||||
|
self.port = port
|
||||||
|
self.timeout = timeout if isinstance(timeout, float) else 0.0
|
||||||
|
self.scheme = "http"
|
||||||
|
self._closed = True
|
||||||
|
self._response = None
|
||||||
|
# ignore these things because we don't
|
||||||
|
# have control over that stuff
|
||||||
|
self.proxy = None
|
||||||
|
self.proxy_config = None
|
||||||
|
self.blocksize = blocksize
|
||||||
|
self.source_address = None
|
||||||
|
self.socket_options = None
|
||||||
|
|
||||||
|
def set_tunnel(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = 0,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
scheme: str = "http",
|
||||||
|
) -> None:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def connect(self) -> None:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def request(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
# We know *at least* botocore is depending on the order of the
|
||||||
|
# first 3 parameters so to be safe we only mark the later ones
|
||||||
|
# as keyword-only to ensure we have space to extend.
|
||||||
|
*,
|
||||||
|
chunked: bool = False,
|
||||||
|
preload_content: bool = True,
|
||||||
|
decode_content: bool = True,
|
||||||
|
enforce_content_length: bool = True,
|
||||||
|
) -> None:
|
||||||
|
self._closed = False
|
||||||
|
if url.startswith("/"):
|
||||||
|
# no scheme / host / port included, make a full url
|
||||||
|
url = f"{self.scheme}://{self.host}:{self.port}" + url
|
||||||
|
request = EmscriptenRequest(
|
||||||
|
url=url,
|
||||||
|
method=method,
|
||||||
|
timeout=self.timeout if self.timeout else 0,
|
||||||
|
decode_content=decode_content,
|
||||||
|
)
|
||||||
|
request.set_body(body)
|
||||||
|
if headers:
|
||||||
|
for k, v in headers.items():
|
||||||
|
request.set_header(k, v)
|
||||||
|
self._response = None
|
||||||
|
try:
|
||||||
|
if not preload_content:
|
||||||
|
self._response = send_streaming_request(request)
|
||||||
|
if self._response is None:
|
||||||
|
self._response = send_request(request)
|
||||||
|
except _TimeoutError as e:
|
||||||
|
raise TimeoutError(e.message) from e
|
||||||
|
except _RequestError as e:
|
||||||
|
raise HTTPException(e.message) from e
|
||||||
|
|
||||||
|
def getresponse(self) -> BaseHTTPResponse:
|
||||||
|
if self._response is not None:
|
||||||
|
return EmscriptenHttpResponseWrapper(
|
||||||
|
internal_response=self._response,
|
||||||
|
url=self._response.request.url,
|
||||||
|
connection=self,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ResponseNotReady()
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
self._closed = True
|
||||||
|
self._response = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_closed(self) -> bool:
|
||||||
|
"""Whether the connection either is brand new or has been previously closed.
|
||||||
|
If this property is True then both ``is_connected`` and ``has_connected_to_proxy``
|
||||||
|
properties must be False.
|
||||||
|
"""
|
||||||
|
return self._closed
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_connected(self) -> bool:
|
||||||
|
"""Whether the connection is actively connected to any origin (proxy or target)"""
|
||||||
|
return True
|
||||||
|
|
||||||
|
@property
|
||||||
|
def has_connected_to_proxy(self) -> bool:
|
||||||
|
"""Whether the connection has successfully connected to its proxy.
|
||||||
|
This returns False if no proxy is in use. Used to determine whether
|
||||||
|
errors are coming from the proxy layer or from tunnelling to the target origin.
|
||||||
|
"""
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
class EmscriptenHTTPSConnection(EmscriptenHTTPConnection):
|
||||||
|
default_port = port_by_scheme["https"]
|
||||||
|
# all this is basically ignored, as browser handles https
|
||||||
|
cert_reqs: int | str | None = None
|
||||||
|
ca_certs: str | None = None
|
||||||
|
ca_cert_dir: str | None = None
|
||||||
|
ca_cert_data: None | str | bytes = None
|
||||||
|
cert_file: str | None
|
||||||
|
key_file: str | None
|
||||||
|
key_password: str | None
|
||||||
|
ssl_context: typing.Any | None
|
||||||
|
ssl_version: int | str | None = None
|
||||||
|
ssl_minimum_version: int | None = None
|
||||||
|
ssl_maximum_version: int | None = None
|
||||||
|
assert_hostname: None | str | typing.Literal[False]
|
||||||
|
assert_fingerprint: str | None = None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int = 0,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 16384,
|
||||||
|
socket_options: None
|
||||||
|
| _TYPE_SOCKET_OPTIONS = HTTPConnection.default_socket_options,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
cert_reqs: int | str | None = None,
|
||||||
|
assert_hostname: None | str | typing.Literal[False] = None,
|
||||||
|
assert_fingerprint: str | None = None,
|
||||||
|
server_hostname: str | None = None,
|
||||||
|
ssl_context: typing.Any | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
ssl_minimum_version: int | None = None,
|
||||||
|
ssl_maximum_version: int | None = None,
|
||||||
|
ssl_version: int | str | None = None, # Deprecated
|
||||||
|
cert_file: str | None = None,
|
||||||
|
key_file: str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
) -> None:
|
||||||
|
super().__init__(
|
||||||
|
host,
|
||||||
|
port=port,
|
||||||
|
timeout=timeout,
|
||||||
|
source_address=source_address,
|
||||||
|
blocksize=blocksize,
|
||||||
|
socket_options=socket_options,
|
||||||
|
proxy=proxy,
|
||||||
|
proxy_config=proxy_config,
|
||||||
|
)
|
||||||
|
self.scheme = "https"
|
||||||
|
|
||||||
|
self.key_file = key_file
|
||||||
|
self.cert_file = cert_file
|
||||||
|
self.key_password = key_password
|
||||||
|
self.ssl_context = ssl_context
|
||||||
|
self.server_hostname = server_hostname
|
||||||
|
self.assert_hostname = assert_hostname
|
||||||
|
self.assert_fingerprint = assert_fingerprint
|
||||||
|
self.ssl_version = ssl_version
|
||||||
|
self.ssl_minimum_version = ssl_minimum_version
|
||||||
|
self.ssl_maximum_version = ssl_maximum_version
|
||||||
|
self.ca_certs = ca_certs and os.path.expanduser(ca_certs)
|
||||||
|
self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)
|
||||||
|
self.ca_cert_data = ca_cert_data
|
||||||
|
|
||||||
|
self.cert_reqs = None
|
||||||
|
|
||||||
|
def set_cert(
|
||||||
|
self,
|
||||||
|
key_file: str | None = None,
|
||||||
|
cert_file: str | None = None,
|
||||||
|
cert_reqs: int | str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
assert_hostname: None | str | typing.Literal[False] = None,
|
||||||
|
assert_fingerprint: str | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
) -> None:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
# verify that this class implements BaseHTTP(s) connection correctly
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
_supports_http_protocol: BaseHTTPConnection = EmscriptenHTTPConnection("", 0)
|
||||||
|
_supports_https_protocol: BaseHTTPSConnection = EmscriptenHTTPSConnection("", 0)
|
||||||
|
|
@ -0,0 +1,110 @@
|
||||||
|
let Status = {
|
||||||
|
SUCCESS_HEADER: -1,
|
||||||
|
SUCCESS_EOF: -2,
|
||||||
|
ERROR_TIMEOUT: -3,
|
||||||
|
ERROR_EXCEPTION: -4,
|
||||||
|
};
|
||||||
|
|
||||||
|
let connections = {};
|
||||||
|
let nextConnectionID = 1;
|
||||||
|
const encoder = new TextEncoder();
|
||||||
|
|
||||||
|
self.addEventListener("message", async function (event) {
|
||||||
|
if (event.data.close) {
|
||||||
|
let connectionID = event.data.close;
|
||||||
|
delete connections[connectionID];
|
||||||
|
return;
|
||||||
|
} else if (event.data.getMore) {
|
||||||
|
let connectionID = event.data.getMore;
|
||||||
|
let { curOffset, value, reader, intBuffer, byteBuffer } =
|
||||||
|
connections[connectionID];
|
||||||
|
// if we still have some in buffer, then just send it back straight away
|
||||||
|
if (!value || curOffset >= value.length) {
|
||||||
|
// read another buffer if required
|
||||||
|
try {
|
||||||
|
let readResponse = await reader.read();
|
||||||
|
|
||||||
|
if (readResponse.done) {
|
||||||
|
// read everything - clear connection and return
|
||||||
|
delete connections[connectionID];
|
||||||
|
Atomics.store(intBuffer, 0, Status.SUCCESS_EOF);
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
// finished reading successfully
|
||||||
|
// return from event handler
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
curOffset = 0;
|
||||||
|
connections[connectionID].value = readResponse.value;
|
||||||
|
value = readResponse.value;
|
||||||
|
} catch (error) {
|
||||||
|
console.log("Request exception:", error);
|
||||||
|
let errorBytes = encoder.encode(error.message);
|
||||||
|
let written = errorBytes.length;
|
||||||
|
byteBuffer.set(errorBytes);
|
||||||
|
intBuffer[1] = written;
|
||||||
|
Atomics.store(intBuffer, 0, Status.ERROR_EXCEPTION);
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// send as much buffer as we can
|
||||||
|
let curLen = value.length - curOffset;
|
||||||
|
if (curLen > byteBuffer.length) {
|
||||||
|
curLen = byteBuffer.length;
|
||||||
|
}
|
||||||
|
byteBuffer.set(value.subarray(curOffset, curOffset + curLen), 0);
|
||||||
|
|
||||||
|
Atomics.store(intBuffer, 0, curLen); // store current length in bytes
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
curOffset += curLen;
|
||||||
|
connections[connectionID].curOffset = curOffset;
|
||||||
|
|
||||||
|
return;
|
||||||
|
} else {
|
||||||
|
// start fetch
|
||||||
|
let connectionID = nextConnectionID;
|
||||||
|
nextConnectionID += 1;
|
||||||
|
const intBuffer = new Int32Array(event.data.buffer);
|
||||||
|
const byteBuffer = new Uint8Array(event.data.buffer, 8);
|
||||||
|
try {
|
||||||
|
const response = await fetch(event.data.url, event.data.fetchParams);
|
||||||
|
// return the headers first via textencoder
|
||||||
|
var headers = [];
|
||||||
|
for (const pair of response.headers.entries()) {
|
||||||
|
headers.push([pair[0], pair[1]]);
|
||||||
|
}
|
||||||
|
let headerObj = {
|
||||||
|
headers: headers,
|
||||||
|
status: response.status,
|
||||||
|
connectionID,
|
||||||
|
};
|
||||||
|
const headerText = JSON.stringify(headerObj);
|
||||||
|
let headerBytes = encoder.encode(headerText);
|
||||||
|
let written = headerBytes.length;
|
||||||
|
byteBuffer.set(headerBytes);
|
||||||
|
intBuffer[1] = written;
|
||||||
|
// make a connection
|
||||||
|
connections[connectionID] = {
|
||||||
|
reader: response.body.getReader(),
|
||||||
|
intBuffer: intBuffer,
|
||||||
|
byteBuffer: byteBuffer,
|
||||||
|
value: undefined,
|
||||||
|
curOffset: 0,
|
||||||
|
};
|
||||||
|
// set header ready
|
||||||
|
Atomics.store(intBuffer, 0, Status.SUCCESS_HEADER);
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
// all fetching after this goes through a new postmessage call with getMore
|
||||||
|
// this allows for parallel requests
|
||||||
|
} catch (error) {
|
||||||
|
console.log("Request exception:", error);
|
||||||
|
let errorBytes = encoder.encode(error.message);
|
||||||
|
let written = errorBytes.length;
|
||||||
|
byteBuffer.set(errorBytes);
|
||||||
|
intBuffer[1] = written;
|
||||||
|
Atomics.store(intBuffer, 0, Status.ERROR_EXCEPTION);
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
});
|
||||||
|
self.postMessage({ inited: true });
|
||||||
|
|
@ -0,0 +1,413 @@
|
||||||
|
"""
|
||||||
|
Support for streaming http requests in emscripten.
|
||||||
|
|
||||||
|
A few caveats -
|
||||||
|
|
||||||
|
Firstly, you can't do streaming http in the main UI thread, because atomics.wait isn't allowed.
|
||||||
|
Streaming only works if you're running pyodide in a web worker.
|
||||||
|
|
||||||
|
Secondly, this uses an extra web worker and SharedArrayBuffer to do the asynchronous fetch
|
||||||
|
operation, so it requires that you have crossOriginIsolation enabled, by serving over https
|
||||||
|
(or from localhost) with the two headers below set:
|
||||||
|
|
||||||
|
Cross-Origin-Opener-Policy: same-origin
|
||||||
|
Cross-Origin-Embedder-Policy: require-corp
|
||||||
|
|
||||||
|
You can tell if cross origin isolation is successfully enabled by looking at the global crossOriginIsolated variable in
|
||||||
|
javascript console. If it isn't, streaming requests will fallback to XMLHttpRequest, i.e. getting the whole
|
||||||
|
request into a buffer and then returning it. it shows a warning in the javascript console in this case.
|
||||||
|
|
||||||
|
Finally, the webworker which does the streaming fetch is created on initial import, but will only be started once
|
||||||
|
control is returned to javascript. Call `await wait_for_streaming_ready()` to wait for streaming fetch.
|
||||||
|
|
||||||
|
NB: in this code, there are a lot of javascript objects. They are named js_*
|
||||||
|
to make it clear what type of object they are.
|
||||||
|
"""
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import io
|
||||||
|
import json
|
||||||
|
from email.parser import Parser
|
||||||
|
from importlib.resources import files
|
||||||
|
from typing import TYPE_CHECKING, Any
|
||||||
|
|
||||||
|
import js # type: ignore[import]
|
||||||
|
from pyodide.ffi import JsArray, JsException, JsProxy, to_js # type: ignore[import]
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from typing_extensions import Buffer
|
||||||
|
|
||||||
|
from .request import EmscriptenRequest
|
||||||
|
from .response import EmscriptenResponse
|
||||||
|
|
||||||
|
"""
|
||||||
|
There are some headers that trigger unintended CORS preflight requests.
|
||||||
|
See also https://github.com/koenvo/pyodide-http/issues/22
|
||||||
|
"""
|
||||||
|
HEADERS_TO_IGNORE = ("user-agent",)
|
||||||
|
|
||||||
|
SUCCESS_HEADER = -1
|
||||||
|
SUCCESS_EOF = -2
|
||||||
|
ERROR_TIMEOUT = -3
|
||||||
|
ERROR_EXCEPTION = -4
|
||||||
|
|
||||||
|
_STREAMING_WORKER_CODE = (
|
||||||
|
files(__package__)
|
||||||
|
.joinpath("emscripten_fetch_worker.js")
|
||||||
|
.read_text(encoding="utf-8")
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class _RequestError(Exception):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
message: str | None = None,
|
||||||
|
*,
|
||||||
|
request: EmscriptenRequest | None = None,
|
||||||
|
response: EmscriptenResponse | None = None,
|
||||||
|
):
|
||||||
|
self.request = request
|
||||||
|
self.response = response
|
||||||
|
self.message = message
|
||||||
|
super().__init__(self.message)
|
||||||
|
|
||||||
|
|
||||||
|
class _StreamingError(_RequestError):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class _TimeoutError(_RequestError):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
def _obj_from_dict(dict_val: dict[str, Any]) -> JsProxy:
|
||||||
|
return to_js(dict_val, dict_converter=js.Object.fromEntries)
|
||||||
|
|
||||||
|
|
||||||
|
class _ReadStream(io.RawIOBase):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
int_buffer: JsArray,
|
||||||
|
byte_buffer: JsArray,
|
||||||
|
timeout: float,
|
||||||
|
worker: JsProxy,
|
||||||
|
connection_id: int,
|
||||||
|
request: EmscriptenRequest,
|
||||||
|
):
|
||||||
|
self.int_buffer = int_buffer
|
||||||
|
self.byte_buffer = byte_buffer
|
||||||
|
self.read_pos = 0
|
||||||
|
self.read_len = 0
|
||||||
|
self.connection_id = connection_id
|
||||||
|
self.worker = worker
|
||||||
|
self.timeout = int(1000 * timeout) if timeout > 0 else None
|
||||||
|
self.is_live = True
|
||||||
|
self._is_closed = False
|
||||||
|
self.request: EmscriptenRequest | None = request
|
||||||
|
|
||||||
|
def __del__(self) -> None:
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
# this is compatible with _base_connection
|
||||||
|
def is_closed(self) -> bool:
|
||||||
|
return self._is_closed
|
||||||
|
|
||||||
|
# for compatibility with RawIOBase
|
||||||
|
@property
|
||||||
|
def closed(self) -> bool:
|
||||||
|
return self.is_closed()
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
if not self.is_closed():
|
||||||
|
self.read_len = 0
|
||||||
|
self.read_pos = 0
|
||||||
|
self.int_buffer = None
|
||||||
|
self.byte_buffer = None
|
||||||
|
self._is_closed = True
|
||||||
|
self.request = None
|
||||||
|
if self.is_live:
|
||||||
|
self.worker.postMessage(_obj_from_dict({"close": self.connection_id}))
|
||||||
|
self.is_live = False
|
||||||
|
super().close()
|
||||||
|
|
||||||
|
def readable(self) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def writable(self) -> bool:
|
||||||
|
return False
|
||||||
|
|
||||||
|
def seekable(self) -> bool:
|
||||||
|
return False
|
||||||
|
|
||||||
|
def readinto(self, byte_obj: Buffer) -> int:
|
||||||
|
if not self.int_buffer:
|
||||||
|
raise _StreamingError(
|
||||||
|
"No buffer for stream in _ReadStream.readinto",
|
||||||
|
request=self.request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
if self.read_len == 0:
|
||||||
|
# wait for the worker to send something
|
||||||
|
js.Atomics.store(self.int_buffer, 0, ERROR_TIMEOUT)
|
||||||
|
self.worker.postMessage(_obj_from_dict({"getMore": self.connection_id}))
|
||||||
|
if (
|
||||||
|
js.Atomics.wait(self.int_buffer, 0, ERROR_TIMEOUT, self.timeout)
|
||||||
|
== "timed-out"
|
||||||
|
):
|
||||||
|
raise _TimeoutError
|
||||||
|
data_len = self.int_buffer[0]
|
||||||
|
if data_len > 0:
|
||||||
|
self.read_len = data_len
|
||||||
|
self.read_pos = 0
|
||||||
|
elif data_len == ERROR_EXCEPTION:
|
||||||
|
string_len = self.int_buffer[1]
|
||||||
|
# decode the error string
|
||||||
|
js_decoder = js.TextDecoder.new()
|
||||||
|
json_str = js_decoder.decode(self.byte_buffer.slice(0, string_len))
|
||||||
|
raise _StreamingError(
|
||||||
|
f"Exception thrown in fetch: {json_str}",
|
||||||
|
request=self.request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# EOF, free the buffers and return zero
|
||||||
|
# and free the request
|
||||||
|
self.is_live = False
|
||||||
|
self.close()
|
||||||
|
return 0
|
||||||
|
# copy from int32array to python bytes
|
||||||
|
ret_length = min(self.read_len, len(memoryview(byte_obj)))
|
||||||
|
subarray = self.byte_buffer.subarray(
|
||||||
|
self.read_pos, self.read_pos + ret_length
|
||||||
|
).to_py()
|
||||||
|
memoryview(byte_obj)[0:ret_length] = subarray
|
||||||
|
self.read_len -= ret_length
|
||||||
|
self.read_pos += ret_length
|
||||||
|
return ret_length
|
||||||
|
|
||||||
|
|
||||||
|
class _StreamingFetcher:
|
||||||
|
def __init__(self) -> None:
|
||||||
|
# make web-worker and data buffer on startup
|
||||||
|
self.streaming_ready = False
|
||||||
|
|
||||||
|
js_data_blob = js.Blob.new(
|
||||||
|
[_STREAMING_WORKER_CODE], _obj_from_dict({"type": "application/javascript"})
|
||||||
|
)
|
||||||
|
|
||||||
|
def promise_resolver(js_resolve_fn: JsProxy, js_reject_fn: JsProxy) -> None:
|
||||||
|
def onMsg(e: JsProxy) -> None:
|
||||||
|
self.streaming_ready = True
|
||||||
|
js_resolve_fn(e)
|
||||||
|
|
||||||
|
def onErr(e: JsProxy) -> None:
|
||||||
|
js_reject_fn(e) # Defensive: never happens in ci
|
||||||
|
|
||||||
|
self.js_worker.onmessage = onMsg
|
||||||
|
self.js_worker.onerror = onErr
|
||||||
|
|
||||||
|
js_data_url = js.URL.createObjectURL(js_data_blob)
|
||||||
|
self.js_worker = js.globalThis.Worker.new(js_data_url)
|
||||||
|
self.js_worker_ready_promise = js.globalThis.Promise.new(promise_resolver)
|
||||||
|
|
||||||
|
def send(self, request: EmscriptenRequest) -> EmscriptenResponse:
|
||||||
|
headers = {
|
||||||
|
k: v for k, v in request.headers.items() if k not in HEADERS_TO_IGNORE
|
||||||
|
}
|
||||||
|
|
||||||
|
body = request.body
|
||||||
|
fetch_data = {"headers": headers, "body": to_js(body), "method": request.method}
|
||||||
|
# start the request off in the worker
|
||||||
|
timeout = int(1000 * request.timeout) if request.timeout > 0 else None
|
||||||
|
js_shared_buffer = js.SharedArrayBuffer.new(1048576)
|
||||||
|
js_int_buffer = js.Int32Array.new(js_shared_buffer)
|
||||||
|
js_byte_buffer = js.Uint8Array.new(js_shared_buffer, 8)
|
||||||
|
|
||||||
|
js.Atomics.store(js_int_buffer, 0, ERROR_TIMEOUT)
|
||||||
|
js.Atomics.notify(js_int_buffer, 0)
|
||||||
|
js_absolute_url = js.URL.new(request.url, js.location).href
|
||||||
|
self.js_worker.postMessage(
|
||||||
|
_obj_from_dict(
|
||||||
|
{
|
||||||
|
"buffer": js_shared_buffer,
|
||||||
|
"url": js_absolute_url,
|
||||||
|
"fetchParams": fetch_data,
|
||||||
|
}
|
||||||
|
)
|
||||||
|
)
|
||||||
|
# wait for the worker to send something
|
||||||
|
js.Atomics.wait(js_int_buffer, 0, ERROR_TIMEOUT, timeout)
|
||||||
|
if js_int_buffer[0] == ERROR_TIMEOUT:
|
||||||
|
raise _TimeoutError(
|
||||||
|
"Timeout connecting to streaming request",
|
||||||
|
request=request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
elif js_int_buffer[0] == SUCCESS_HEADER:
|
||||||
|
# got response
|
||||||
|
# header length is in second int of intBuffer
|
||||||
|
string_len = js_int_buffer[1]
|
||||||
|
# decode the rest to a JSON string
|
||||||
|
js_decoder = js.TextDecoder.new()
|
||||||
|
# this does a copy (the slice) because decode can't work on shared array
|
||||||
|
# for some silly reason
|
||||||
|
json_str = js_decoder.decode(js_byte_buffer.slice(0, string_len))
|
||||||
|
# get it as an object
|
||||||
|
response_obj = json.loads(json_str)
|
||||||
|
return EmscriptenResponse(
|
||||||
|
request=request,
|
||||||
|
status_code=response_obj["status"],
|
||||||
|
headers=response_obj["headers"],
|
||||||
|
body=_ReadStream(
|
||||||
|
js_int_buffer,
|
||||||
|
js_byte_buffer,
|
||||||
|
request.timeout,
|
||||||
|
self.js_worker,
|
||||||
|
response_obj["connectionID"],
|
||||||
|
request,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
elif js_int_buffer[0] == ERROR_EXCEPTION:
|
||||||
|
string_len = js_int_buffer[1]
|
||||||
|
# decode the error string
|
||||||
|
js_decoder = js.TextDecoder.new()
|
||||||
|
json_str = js_decoder.decode(js_byte_buffer.slice(0, string_len))
|
||||||
|
raise _StreamingError(
|
||||||
|
f"Exception thrown in fetch: {json_str}", request=request, response=None
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise _StreamingError(
|
||||||
|
f"Unknown status from worker in fetch: {js_int_buffer[0]}",
|
||||||
|
request=request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
# check if we are in a worker or not
|
||||||
|
def is_in_browser_main_thread() -> bool:
|
||||||
|
return hasattr(js, "window") and hasattr(js, "self") and js.self == js.window
|
||||||
|
|
||||||
|
|
||||||
|
def is_cross_origin_isolated() -> bool:
|
||||||
|
return hasattr(js, "crossOriginIsolated") and js.crossOriginIsolated
|
||||||
|
|
||||||
|
|
||||||
|
def is_in_node() -> bool:
|
||||||
|
return (
|
||||||
|
hasattr(js, "process")
|
||||||
|
and hasattr(js.process, "release")
|
||||||
|
and hasattr(js.process.release, "name")
|
||||||
|
and js.process.release.name == "node"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def is_worker_available() -> bool:
|
||||||
|
return hasattr(js, "Worker") and hasattr(js, "Blob")
|
||||||
|
|
||||||
|
|
||||||
|
_fetcher: _StreamingFetcher | None = None
|
||||||
|
|
||||||
|
if is_worker_available() and (
|
||||||
|
(is_cross_origin_isolated() and not is_in_browser_main_thread())
|
||||||
|
and (not is_in_node())
|
||||||
|
):
|
||||||
|
_fetcher = _StreamingFetcher()
|
||||||
|
else:
|
||||||
|
_fetcher = None
|
||||||
|
|
||||||
|
|
||||||
|
def send_streaming_request(request: EmscriptenRequest) -> EmscriptenResponse | None:
|
||||||
|
if _fetcher and streaming_ready():
|
||||||
|
return _fetcher.send(request)
|
||||||
|
else:
|
||||||
|
_show_streaming_warning()
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
_SHOWN_TIMEOUT_WARNING = False
|
||||||
|
|
||||||
|
|
||||||
|
def _show_timeout_warning() -> None:
|
||||||
|
global _SHOWN_TIMEOUT_WARNING
|
||||||
|
if not _SHOWN_TIMEOUT_WARNING:
|
||||||
|
_SHOWN_TIMEOUT_WARNING = True
|
||||||
|
message = "Warning: Timeout is not available on main browser thread"
|
||||||
|
js.console.warn(message)
|
||||||
|
|
||||||
|
|
||||||
|
_SHOWN_STREAMING_WARNING = False
|
||||||
|
|
||||||
|
|
||||||
|
def _show_streaming_warning() -> None:
|
||||||
|
global _SHOWN_STREAMING_WARNING
|
||||||
|
if not _SHOWN_STREAMING_WARNING:
|
||||||
|
_SHOWN_STREAMING_WARNING = True
|
||||||
|
message = "Can't stream HTTP requests because: \n"
|
||||||
|
if not is_cross_origin_isolated():
|
||||||
|
message += " Page is not cross-origin isolated\n"
|
||||||
|
if is_in_browser_main_thread():
|
||||||
|
message += " Python is running in main browser thread\n"
|
||||||
|
if not is_worker_available():
|
||||||
|
message += " Worker or Blob classes are not available in this environment." # Defensive: this is always False in browsers that we test in
|
||||||
|
if streaming_ready() is False:
|
||||||
|
message += """ Streaming fetch worker isn't ready. If you want to be sure that streaming fetch
|
||||||
|
is working, you need to call: 'await urllib3.contrib.emscripten.fetch.wait_for_streaming_ready()`"""
|
||||||
|
from js import console
|
||||||
|
|
||||||
|
console.warn(message)
|
||||||
|
|
||||||
|
|
||||||
|
def send_request(request: EmscriptenRequest) -> EmscriptenResponse:
|
||||||
|
try:
|
||||||
|
js_xhr = js.XMLHttpRequest.new()
|
||||||
|
|
||||||
|
if not is_in_browser_main_thread():
|
||||||
|
js_xhr.responseType = "arraybuffer"
|
||||||
|
if request.timeout:
|
||||||
|
js_xhr.timeout = int(request.timeout * 1000)
|
||||||
|
else:
|
||||||
|
js_xhr.overrideMimeType("text/plain; charset=ISO-8859-15")
|
||||||
|
if request.timeout:
|
||||||
|
# timeout isn't available on the main thread - show a warning in console
|
||||||
|
# if it is set
|
||||||
|
_show_timeout_warning()
|
||||||
|
|
||||||
|
js_xhr.open(request.method, request.url, False)
|
||||||
|
for name, value in request.headers.items():
|
||||||
|
if name.lower() not in HEADERS_TO_IGNORE:
|
||||||
|
js_xhr.setRequestHeader(name, value)
|
||||||
|
|
||||||
|
js_xhr.send(to_js(request.body))
|
||||||
|
|
||||||
|
headers = dict(Parser().parsestr(js_xhr.getAllResponseHeaders()))
|
||||||
|
|
||||||
|
if not is_in_browser_main_thread():
|
||||||
|
body = js_xhr.response.to_py().tobytes()
|
||||||
|
else:
|
||||||
|
body = js_xhr.response.encode("ISO-8859-15")
|
||||||
|
return EmscriptenResponse(
|
||||||
|
status_code=js_xhr.status, headers=headers, body=body, request=request
|
||||||
|
)
|
||||||
|
except JsException as err:
|
||||||
|
if err.name == "TimeoutError":
|
||||||
|
raise _TimeoutError(err.message, request=request)
|
||||||
|
elif err.name == "NetworkError":
|
||||||
|
raise _RequestError(err.message, request=request)
|
||||||
|
else:
|
||||||
|
# general http error
|
||||||
|
raise _RequestError(err.message, request=request)
|
||||||
|
|
||||||
|
|
||||||
|
def streaming_ready() -> bool | None:
|
||||||
|
if _fetcher:
|
||||||
|
return _fetcher.streaming_ready
|
||||||
|
else:
|
||||||
|
return None # no fetcher, return None to signify that
|
||||||
|
|
||||||
|
|
||||||
|
async def wait_for_streaming_ready() -> bool:
|
||||||
|
if _fetcher:
|
||||||
|
await _fetcher.js_worker_ready_promise
|
||||||
|
return True
|
||||||
|
else:
|
||||||
|
return False
|
||||||
|
|
@ -0,0 +1,22 @@
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from dataclasses import dataclass, field
|
||||||
|
|
||||||
|
from ..._base_connection import _TYPE_BODY
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class EmscriptenRequest:
|
||||||
|
method: str
|
||||||
|
url: str
|
||||||
|
params: dict[str, str] | None = None
|
||||||
|
body: _TYPE_BODY | None = None
|
||||||
|
headers: dict[str, str] = field(default_factory=dict)
|
||||||
|
timeout: float = 0
|
||||||
|
decode_content: bool = True
|
||||||
|
|
||||||
|
def set_header(self, name: str, value: str) -> None:
|
||||||
|
self.headers[name.capitalize()] = value
|
||||||
|
|
||||||
|
def set_body(self, body: _TYPE_BODY | None) -> None:
|
||||||
|
self.body = body
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue